5 - Convolutional Sequence to Sequence Learning
5 - Convolutional Sequence to Sequence Learning
This part will be be implementing the Convolutional Sequence to Sequence Learning model
Introduction
There are no recurrent components used at all in this tutorial. Instead it makes use of convolutional layers, typically used for image processing.
In short, a convolutional layer uses filters. These filters have a width (and also a height in images, but usually not text). If a filter has a width of 3, then it can see 3 consecutive tokens. Each convolutional layer has many of these filters (1024 in this tutorial). Each filter will slide across the sequence, from beginning to the end, looking at all 3 consecutive tokens at a time. The idea is that each of these 1024 filters will learn to extract a different feature from the text. The result of this feature extraction will then be used by the model - potentially as input to another convolutional layer. This can then all be used to extract features from the source sentence to translate it into the target language.
Preparing Data
First, import all the required modules and set the random seeds for reproducability.
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torchtext.datasets import TranslationDataset, Multi30k
from torchtext.data import Field, BucketIterator
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
import spacy
import numpy as np
import random
import math
import time
SEED = 1234
random.seed(SEED)
np.random.seed(SEED)
torch.manual_seed(SEED)
torch.cuda.manual_seed(SEED)
torch.backends.cudnn.deterministic = True
spacy_de = spacy.load('de')
spacy_en = spacy.load('en')
# create tokenizer
def tokenize_de(text):
"""
Tokenizes German text from a string into a list of strings
"""
return [tok.text for tok in spacy_de.tokenizer(text)]
def tokenize_en(text):
"""
Tokenizes English text from a string into a list of strings
"""
return [tok.text for tok in spacy_en.tokenizer(text)]Next, set up the Fields which decide how the data will be processed. By default RNN models in PyTorch require the sequence to be a tensor of shape [sequence length, batch size] so TorchText will, by default, return batches of tensors in the same shape. However, this tutorial use CNNs which expect the batch dimension to be first. Therefore, tell TorchText to have batches be [batch size, sequence length] by setting batch_first = True.
Also append the start and end of sequence tokens as well as lowercasing all text.
init_token = '<sos>',
eos_token = '<eos>',
lower = True,
batch_first = True)
TRG = Field(tokenize = tokenize_en,
init_token = '<sos>',
eos_token = '<eos>',
lower = True,
batch_first = True)
# Load data
train_data, valid_data, test_data = Multi30k.splits(exts = ('.de', '.en'), fields = (SRC, TRG))
print(vars(train_data.examples[0]))
# {'src': ['zwei', 'junge', 'weiße', 'männer', 'sind', 'im', 'freien', 'in', 'der', 'nähe', 'vieler', 'büsche', '.'], 'trg': ['two', 'young', ',', 'white', 'males', 'are', 'outside', 'near', 'many', 'bushes', '.']}
# Build the vocabulary
SRC.build_vocab(train_data, min_freq = 2)
TRG.build_vocab(train_data, min_freq = 2)The final bit of data preparation is defining the device and then building the iterator.
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
BATCH_SIZE = 128
train_iterator, valid_iterator, test_iterator = BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size = BATCH_SIZE,
device = device)Building the Seq2Seq Model
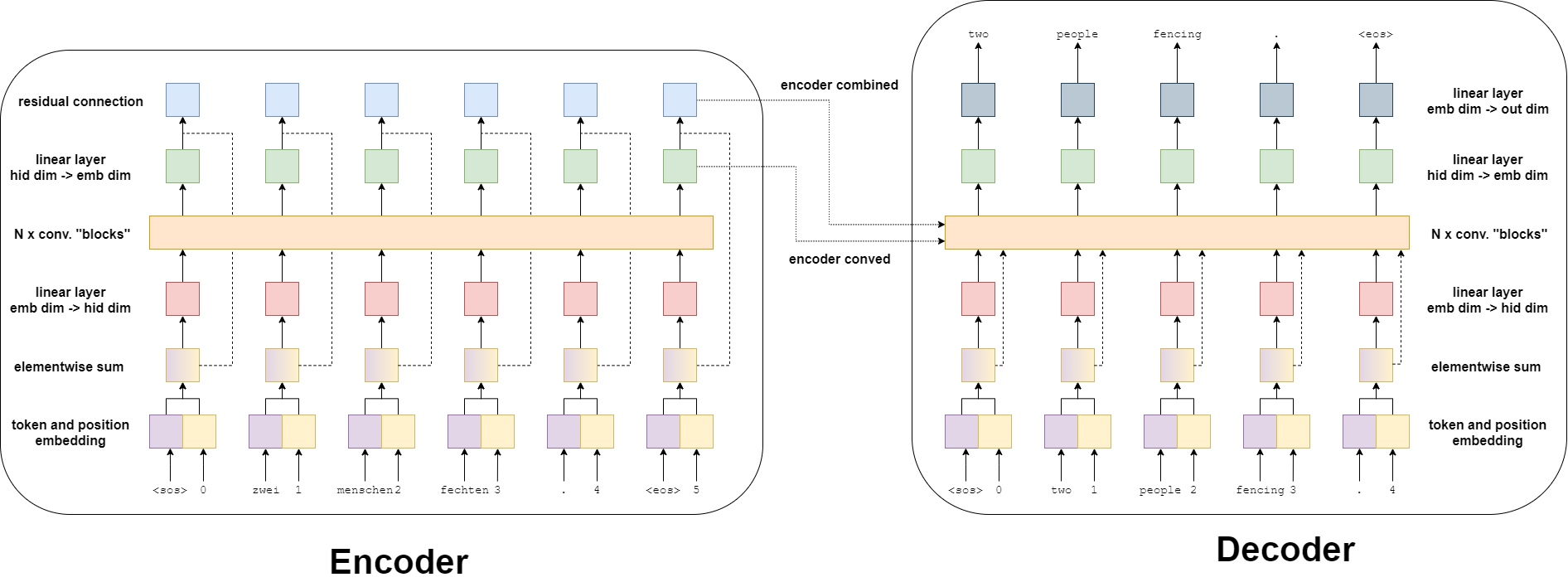
Encoder
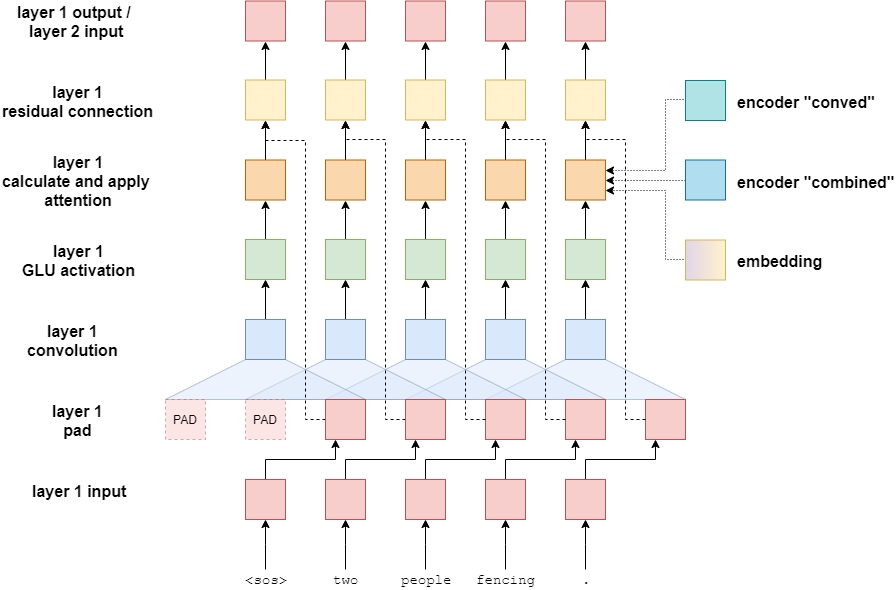
Previous models in tutorials had an encoder that compresses an entire input sentence into a single context vector, $z$. But the convolutional sequence-to-sequence model gets two context vectors for each token in the input sentence. So, if input sentence had 6 tokens, it would get 12 context vectors, two for each token.
The two context vectors per token are a conved vector and a combined vector.
- The conved vector is the result of each token being passed through a few layers
- The combined vector comes from the sum of the convolved vector and the embedding of that token
Both of these are returned by the encoder to be used by the decoder.
The image below shows the result of an input sentence - zwei menschen fechten. - being passed through the encoder.
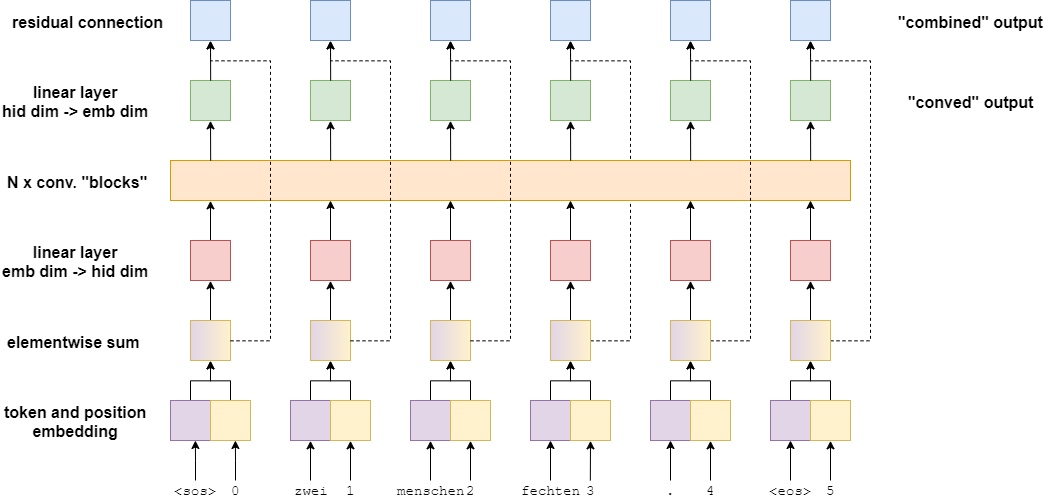
First, the token is passed through a token embedding layer. However, as there are no recurrent connections in this model it has no idea about the order of the tokens within a sequence. To rectify this, use a second embedding layer, the positional embedding layer. This is a standard embedding layer where the input is the position of the token within the sequence - starting with the first token, the
Next, the token and positional embeddings are elementwise summed together to get a vector which contains information about the token and also its position with in the sequence - which simply call it the embedding vector. This is followed by a linear layer which transforms the embedding vector into a vector with the required hidden dimension size.
The next step is to pass this hidden vector into $N$ convolutional blocks where the “magic” happens in this model. After passing through the convolutional blocks, the vector is then fed through another linear layer to transform it back from the hidden dimension size into the embedding dimension size. This is the conved vector - each token in the input sequence has one of this.
Finally, the conved vector is elementwise summed with the embedding vector via a residual connection to get a combined vector for each token. Again, there is a combined vector for each token in the input sequence.
上述总结, 看图走.
Convolutional Blocks
So, how do these convolutional blocks work? The below image shows 2 convolutional blocks with a single filter (blue) that is sliding across the tokens within the sequence. In the actual implementation it will have 10 convolutional blocks with 1024 filters in each block.
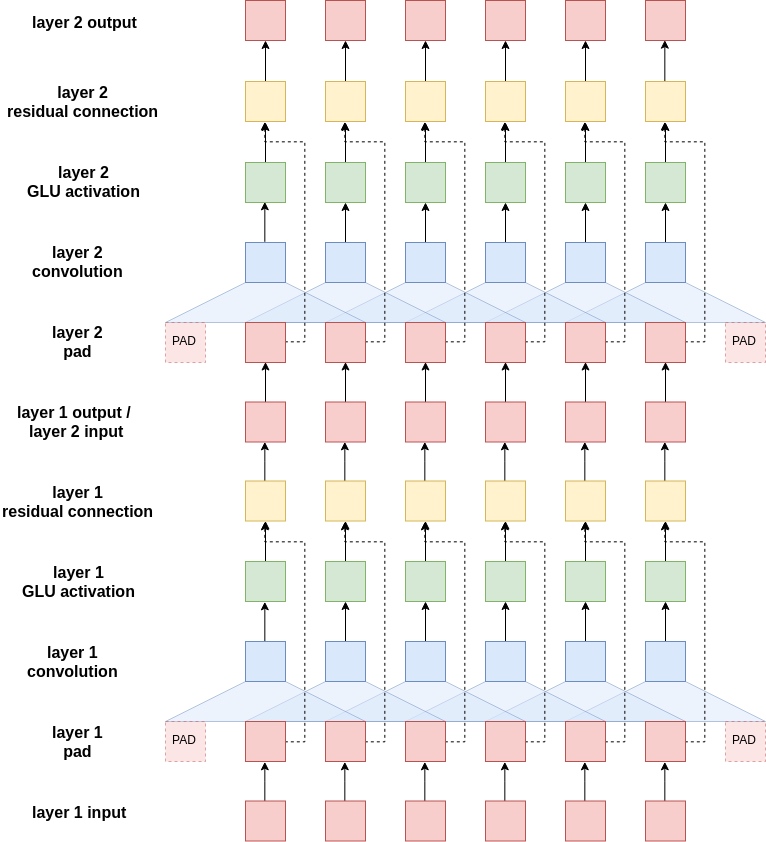
First, the input sentence is padded. This is because the convolutional layers will reduce the length of the input sentence and want the length of the sentence coming into the convolutional blocks to equal the length of it coming out of the convolutional blocks. Without padding, the length of the sequence coming out of a convolutional layer will be filter_size - 1 shorter than the sequence entering the convolutional layer. For example, if had a filter size of 3, the sequence will be 2 elements shorter. Thus, pad the sentence with one padding element on each side. Can calculate the amount of padding on each side by simply doing (filter_size - 1)/2 for odd sized filters - Even sized filters is not covered in this tutorial.
These filters are designed so the output hidden dimension of them is twice the input hidden dimension. In computer vision terminology these hidden dimensions are called channels - but will stick to calling them hidden dimensions. Why double the size of the hidden dimension leaving the convolutional filter? This is because it is using a special activation function called gated linear units (GLU). GLUs have gating mechanisms (similar to LSTMs and GRUs) contained within the activation function and actually half the size of the hidden dimension - whereas usually activation functions keep the hidden dimensions the same size.
After passing through the GLU activation the hidden dimension size for each token is the same as it was when it entered the convolutional blocks. It is now elementwise summed with its own vector before it was passed through the convolutional layer.
This concludes a single convolutional block. Subsequent blocks take the output of the previous block and perform the same steps. Each block has their own parameters, they are not shared between blocks. The output of the last block goes back to the main encoder - where it is fed through a linear layer to get the conved output and then elementwise summed with the embedding of the token to get the combined output.
Encoder Implementation
To keep the implementation simple, only allow for odd sized kernels. This allows padding to be added equally to both sides of the source sequence.
The scale variable is used by the authors to “ensure that the variance throughout the network does not change dramatically”. The performance of the model seems to vary wildly using different seeds if this is not used.
The positional embedding is initialized to have a “vocabulary” of 100. This means it can handle sequences up to 100 elements long, indexed from 0 to 99. This can be increased if used on a dataset with longer sequences.
class Encoder(nn.Module):
def __init__(self,
input_dim,
emb_dim,
hid_dim,
n_layers,
kernel_size,
dropout,
device,
max_length = 100):
super().__init__()
assert kernel_size % 2 == 1, "Kernel size must be odd!"
self.device = device
self.scale = torch.sqrt(torch.FloatTensor([0.5])).to(device)
self.tok_embedding = nn.Embedding(input_dim, emb_dim)
self.pos_embedding = nn.Embedding(max_length, emb_dim)
self.emb2hid = nn.Linear(emb_dim, hid_dim)
self.hid2emb = nn.Linear(hid_dim, emb_dim)
self.convs = nn.ModuleList([nn.Conv1d(in_channels = hid_dim,
out_channels = 2 * hid_dim,
kernel_size = kernel_size,
padding = (kernel_size - 1) // 2)
for _ in range(n_layers)])
self.dropout = nn.Dropout(dropout)
def forward(self, src):
#src = [batch size, src len]
batch_size = src.shape[0]
src_len = src.shape[1]
#create position tensor
pos = torch.arange(0, src_len).unsqueeze(0).repeat(batch_size, 1).to(self.device)
#pos = [0, 1, 2, 3, ..., src len - 1]
#pos = [batch size, src len]
#embed tokens and positions
tok_embedded = self.tok_embedding(src)
pos_embedded = self.pos_embedding(pos)
#tok_embedded = pos_embedded = [batch size, src len, emb dim]
#combine embeddings by elementwise summing
embedded = self.dropout(tok_embedded + pos_embedded)
#embedded = [batch size, src len, emb dim]
#pass embedded through linear layer to convert from emb dim to hid dim
conv_input = self.emb2hid(embedded)
#conv_input = [batch size, src len, hid dim]
#permute for convolutional layer
conv_input = conv_input.permute(0, 2, 1)
#conv_input = [batch size, hid dim, src len]
#begin convolutional blocks...
for i, conv in enumerate(self.convs):
#pass through convolutional layer
conved = conv(self.dropout(conv_input))
#conved = [batch size, 2 * hid dim, src len]
#pass through GLU activation function
conved = F.glu(conved, dim = 1)
#conved = [batch size, hid dim, src len]
#apply residual connection
conved = (conved + conv_input) * self.scale
#conved = [batch size, hid dim, src len]
#set conv_input to conved for next loop iteration
conv_input = conved
#...end convolutional blocks
#permute and convert back to emb dim
conved = self.hid2emb(conved.permute(0, 2, 1))
#conved = [batch size, src len, emb dim]
#elementwise sum output (conved) and input (embedded) to be used for attention
combined = (conved + embedded) * self.scale
#combined = [batch size, src len, emb dim]
return conved, combinedDecoder
The decoder takes in the actual target sentence and tries to predict it. This model differs from the recurrent neural network models previously detailed in these tutorials as it predicts all tokens within the target sentence in parallel. There is no sequential processing, i.e. no decoding loop. This will be detailed further later on in the tutorials.
The decoder is similar to the encoder, with a few changes to both the main model and the convolutional blocks inside the model.
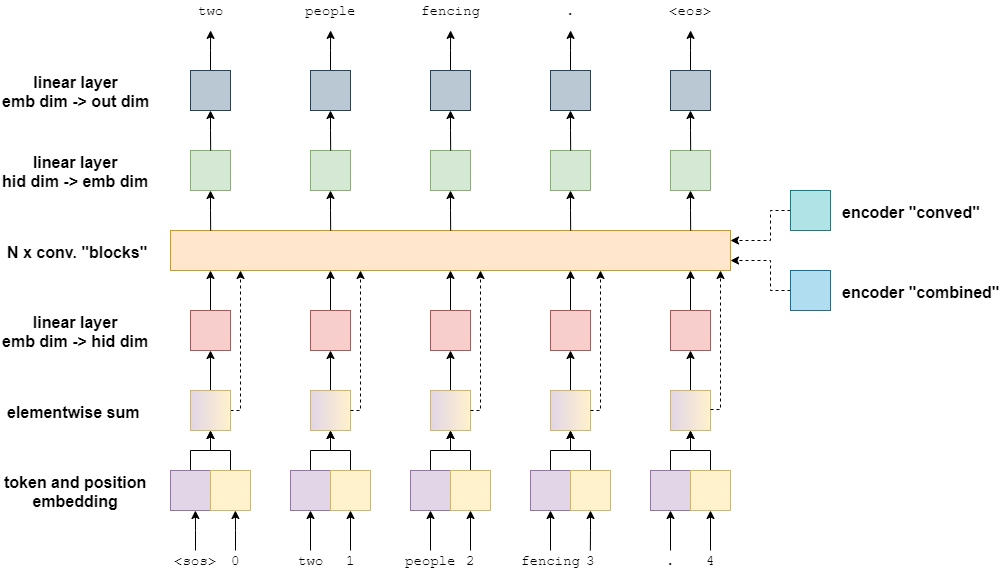
First, the embeddings do not have a residual connection that connects after the convolutional blocks and the transformation. Instead the embeddings are fed into the convolutional blocks to be used as residual connections there.
Second, to feed the decoder information from the encoder, the encoder conved and combined outputs are used - again, within the convolutional blocks.
Finally, the output of the decoder is a linear layer from embedding dimension to output dimension. This is used make a prediction about what the next word in the translation should be.
Decoder Convolutional Blocks
Again, these are similar to the convolutional blocks within the encoder, with a few changes.
First, the padding. Instead of padding equally on each side to ensure the length of the sentence stays the same throughout, only pad at the beginning of the sentence. As it is processing all of the targets simultaneously in parallel, and not sequentially, need a method of only allowing the filters translating token $i$ to only look at tokens before word $i$. If they were allowed to look at token $i+1$ (the token they should be outputting), the model will simply learn to output the next word in the sequence by directly copying it, without actually learning how to translate.
Let’s see what happens if incorrectly padded equally on each side, like operation in the encoder.
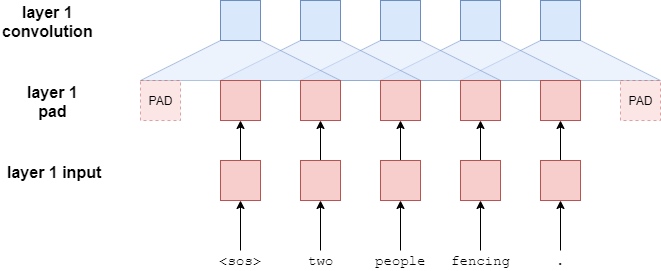
The filter at the first position, which is trying use the first word in the sequence,
Second, after the GLU activation and before the residual connection, the block calculates and applies attention - using the encoded representations and the embedding of the current word. Note: only show the connections to the rightmost token, but they are actually connected to all tokens - this was done for clarity. Each token input uses their own, and only their own, embedding for their own attention calculation.
The attention is calculated by first using a linear layer to change the hidden dimension to the same size as the embedding dimension. Then the embedding summed via a residual connection. This combination then has the standard attention calculation applied by finding how much it “matches” with the encoded conved and then this is applied by getting a weighted sum over the encoded combined. This is then projected back up to the hidden dimenson size and a residual connection to the initial input to the attention layer is applied.
Why do they calculate attention first with the encoded conved and then use it to calculate the weighted sum over the encoded combined? The paper argues that the encoded conved is good for getting a larger context over the encoded sequence, whereas the encoded combined has more information about the specific token and is thus therefore more useful for makng a prediction.
Decoder Impementation
As only pad on one side the decoder is allowed to use both odd and even sized padding. Again, the scale is used to reduce variance throughout the model and the position embedding is initialized to have a “vocabulary” of 100.
This model takes in the encoder representations in its forward method and both are passed to the calculate_attention method which calculates and applies attention. It also returns the actual attention values, but not currently use them.
class Decoder(nn.Module):
def __init__(self,
output_dim,
emb_dim,
hid_dim,
n_layers,
kernel_size,
dropout,
trg_pad_idx,
device,
max_length = 100):
super().__init__()
self.kernel_size = kernel_size
self.trg_pad_idx = trg_pad_idx
self.device = device
self.scale = torch.sqrt(torch.FloatTensor([0.5])).to(device)
self.tok_embedding = nn.Embedding(output_dim, emb_dim)
self.pos_embedding = nn.Embedding(max_length, emb_dim)
self.emb2hid = nn.Linear(emb_dim, hid_dim)
self.hid2emb = nn.Linear(hid_dim, emb_dim)
self.attn_hid2emb = nn.Linear(hid_dim, emb_dim)
self.attn_emb2hid = nn.Linear(emb_dim, hid_dim)
self.fc_out = nn.Linear(emb_dim, output_dim)
self.convs = nn.ModuleList([nn.Conv1d(in_channels = hid_dim,
out_channels = 2 * hid_dim,
kernel_size = kernel_size)
for _ in range(n_layers)])
self.dropout = nn.Dropout(dropout)
def calculate_attention(self, embedded, conved, encoder_conved, encoder_combined):
#embedded = [batch size, trg len, emb dim]
#conved = [batch size, hid dim, trg len]
#encoder_conved = encoder_combined = [batch size, src len, emb dim]
#permute and convert back to emb dim
conved_emb = self.attn_hid2emb(conved.permute(0, 2, 1))
#conved_emb = [batch size, trg len, emb dim]
combined = (conved_emb + embedded) * self.scale
#combined = [batch size, trg len, emb dim]
energy = torch.matmul(combined, encoder_conved.permute(0, 2, 1))
#energy = [batch size, trg len, src len]
attention = F.softmax(energy, dim=2)
#attention = [batch size, trg len, src len]
attended_encoding = torch.matmul(attention, encoder_combined)
#attended_encoding = [batch size, trg len, emd dim]
#convert from emb dim -> hid dim
attended_encoding = self.attn_emb2hid(attended_encoding)
#attended_encoding = [batch size, trg len, hid dim]
#apply residual connection
attended_combined = (conved + attended_encoding.permute(0, 2, 1)) * self.scale
#attended_combined = [batch size, hid dim, trg len]
return attention, attended_combined
def forward(self, trg, encoder_conved, encoder_combined):
#trg = [batch size, trg len]
#encoder_conved = encoder_combined = [batch size, src len, emb dim]
batch_size = trg.shape[0]
trg_len = trg.shape[1]
#create position tensor
pos = torch.arange(0, trg_len).unsqueeze(0).repeat(batch_size, 1).to(self.device)
#pos = [batch size, trg len]
#embed tokens and positions
tok_embedded = self.tok_embedding(trg)
pos_embedded = self.pos_embedding(pos)
#tok_embedded = [batch size, trg len, emb dim]
#pos_embedded = [batch size, trg len, emb dim]
#combine embeddings by elementwise summing
embedded = self.dropout(tok_embedded + pos_embedded)
#embedded = [batch size, trg len, emb dim]
#pass embedded through linear layer to go through emb dim -> hid dim
conv_input = self.emb2hid(embedded)
#conv_input = [batch size, trg len, hid dim]
#permute for convolutional layer
conv_input = conv_input.permute(0, 2, 1)
#conv_input = [batch size, hid dim, trg len]
batch_size = conv_input.shape[0]
hid_dim = conv_input.shape[1]
for i, conv in enumerate(self.convs):
#apply dropout
conv_input = self.dropout(conv_input)
#need to pad so decoder can't "cheat"
padding = torch.zeros(batch_size,
hid_dim,
self.kernel_size - 1).fill_(self.trg_pad_idx).to(self.device)
padded_conv_input = torch.cat((padding, conv_input), dim = 2)
#padded_conv_input = [batch size, hid dim, trg len + kernel size - 1]
#pass through convolutional layer
conved = conv(padded_conv_input)
#conved = [batch size, 2 * hid dim, trg len]
#pass through GLU activation function
conved = F.glu(conved, dim = 1)
#conved = [batch size, hid dim, trg len]
#calculate attention
attention, conved = self.calculate_attention(embedded,
conved,
encoder_conved,
encoder_combined)
#attention = [batch size, trg len, src len]
#apply residual connection
conved = (conved + conv_input) * self.scale
#conved = [batch size, hid dim, trg len]
#set conv_input to conved for next loop iteration
conv_input = conved
conved = self.hid2emb(conved.permute(0, 2, 1))
#conved = [batch size, trg len, emb dim]
output = self.fc_out(self.dropout(conved))
#output = [batch size, trg len, output dim]
return output, attentionSeq2Seq Model
The encapsulating Seq2Seq module is a lot different from recurrent neural network methods used in previous notebooks, especially in the decoding.
trg has the
The encoding is similar, insert the source sequence and receive a “context vector”. However, here have two context vectors per word in the source sequence, encoder_conved and encoder_combined.
As the decoding is done in parallel do not need a decoding loop. All of the target sequence is input into the decoder at once and the padding is used to ensure each convolutional filter in the decoder can only see the current and previous tokens in the sequence as it slides across the sentence.
This also, however, means cannot do teacher forcing using this model. Do not have a loop in which can choose whether to input the predicted token or the actual token in the sequence as everything is predicted in parallel.
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder):
super().__init__()
self.encoder = encoder
self.decoder = decoder
def forward(self, src, trg):
#src = [batch size, src len]
#trg = [batch size, trg len - 1] (<eos> token sliced off the end)
#calculate z^u (encoder_conved) and (z^u + e) (encoder_combined)
#encoder_conved is output from final encoder conv. block
#encoder_combined is encoder_conved plus (elementwise) src embedding plus
# positional embeddings
encoder_conved, encoder_combined = self.encoder(src)
#encoder_conved = [batch size, src len, emb dim]
#encoder_combined = [batch size, src len, emb dim]
#calculate predictions of next words
#output is a batch of predictions for each word in the trg sentence
#attention a batch of attention scores across the src sentence for
# each word in the trg sentence
output, attention = self.decoder(trg, encoder_conved, encoder_combined)
#output = [batch size, trg len - 1, output dim]
#attention = [batch size, trg len - 1, src len]
return output, attentionTraining the Seq2Seq Model
The rest of the tutorial is similar to all of the previous ones. Define all of the hyperparameters, initialize the encoder and decoder, and initialize the overall model - placing it on the GPU if have one.
In the paper they find that it is more beneficial to use a small filter (kernel size of 3) and a high number of layers (5+).
INPUT_DIM = len(SRC.vocab)
OUTPUT_DIM = len(TRG.vocab)
EMB_DIM = 256
HID_DIM = 512 # each conv. layer has 2 * hid_dim filters
ENC_LAYERS = 10 # number of conv. blocks in encoder
DEC_LAYERS = 10 # number of conv. blocks in decoder
ENC_KERNEL_SIZE = 3 # must be odd!
DEC_KERNEL_SIZE = 3 # can be even or odd
ENC_DROPOUT = 0.25
DEC_DROPOUT = 0.25
TRG_PAD_IDX = TRG.vocab.stoi[TRG.pad_token]
enc = Encoder(INPUT_DIM, EMB_DIM, HID_DIM, ENC_LAYERS, ENC_KERNEL_SIZE, ENC_DROPOUT, device)
dec = Decoder(OUTPUT_DIM, EMB_DIM, HID_DIM, DEC_LAYERS, DEC_KERNEL_SIZE, DEC_DROPOUT, TRG_PAD_IDX, device)
model = Seq2Seq(enc, dec).to(device)Can also see that the model has almost twice as many parameters as the attention based model (20m to 37m).
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f'The model has {count_parameters(model):,} trainable parameters') # The model has 37,351,685 trainable parametersNext, define the optimizer and the loss function (criterion). As before ignore the loss where the target sequence is a padding token.
optimizer = optim.Adam(model.parameters())
TRG_PAD_IDX = TRG.vocab.stoi[TRG.pad_token]
criterion = nn.CrossEntropyLoss(ignore_index = TRG_PAD_IDX)Then, define the training loop for the model.
Handle the sequences a little differently than previous tutorials. For all models never put the
$$\begin{align*}
\text{trg} &= [sos, x_1, x_2, x_3, eos]\\
\text{trg[:-1]} &= [sos, x_1, x_2, x_3]
\end{align*}$$
$x_i$ denotes actual target sequence element. then feed this into the model to get a predicted sequence that should hopefully predict the
$$\begin{align*}
\text{output} &= [y_1, y_2, y_3, eos]
\end{align*}$$
$y_i$ denotes predicted target sequence element. Then calculate loss using the original trg tensor with the
$$\begin{align*}
\text{output} &= [y_1, y_2, y_3, eos]\\
\text{trg[1:]} &= [x_1, x_2, x_3, eos]
\end{align*}$$
Then calculate losses and update parameters as is standard.
def train(model, iterator, optimizer, criterion, clip):
model.train()
epoch_loss = 0
for i, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
optimizer.zero_grad()
output, _ = model(src, trg[:,:-1])
#output = [batch size, trg len - 1, output dim]
#trg = [batch size, trg len]
output_dim = output.shape[-1]
output = output.contiguous().view(-1, output_dim)
trg = trg[:,1:].contiguous().view(-1)
#output = [batch size * trg len - 1, output dim]
#trg = [batch size * trg len - 1]
loss = criterion(output, trg)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), clip)
optimizer.step()
epoch_loss += loss.item()
return epoch_loss / len(iterator)The evaluation loop is the same as the training loop, just without the gradient calculations and parameter updates.
def evaluate(model, iterator, criterion):
model.eval()
epoch_loss = 0
with torch.no_grad():
for i, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
output, _ = model(src, trg[:,:-1])
#output = [batch size, trg len - 1, output dim]
#trg = [batch size, trg len]
output_dim = output.shape[-1]
output = output.contiguous().view(-1, output_dim)
trg = trg[:,1:].contiguous().view(-1)
#output = [batch size * trg len - 1, output dim]
#trg = [batch size * trg len - 1]
loss = criterion(output, trg)
epoch_loss += loss.item()
return epoch_loss / len(iterator)Again, have a function that tells us how long each epoch takes.
def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secsFinally, train model. Notice have reduced the CLIP value from 1 to 0.1 in order to train this model more reliably. With higher CLIP values, the gradient occasionally explodes.
Although have almost twice as many parameters as the attention based RNN model, it actually takes around half the time as the standard version and about the same time as the packed padded sequences version. This is due to all calculations being done in parallel using the convolutional filters instead of sequentially using RNNs.
Note: this model always has a teacher forcing ratio of 1, i.e. it will always use the ground truth next token from the target sequence. This means cannot compare perplexity values against the previous models when they are using a teacher forcing ratio that is not 1. See here for the results of the attention based RNN using a teacher forcing ratio of 1.
N_EPOCHS = 10
CLIP = 0.1
best_valid_loss = float('inf')
for epoch in range(N_EPOCHS):
start_time = time.time()
train_loss = train(model, train_iterator, optimizer, criterion, CLIP)
valid_loss = evaluate(model, valid_iterator, criterion)
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), 'tut5-model.pt')
print(f'Epoch: {epoch+1:02} | Time: {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train PPL: {math.exp(train_loss):7.3f}')
print(f'\t Val. Loss: {valid_loss:.3f} | Val. PPL: {math.exp(valid_loss):7.3f}')
'''
Epoch: 01 | Time: 0m 30s
Train Loss: 4.240 | Train PPL: 69.408
Val. Loss: 2.994 | Val. PPL: 19.961
Epoch: 02 | Time: 0m 30s
Train Loss: 3.043 | Train PPL: 20.971
Val. Loss: 2.379 | Val. PPL: 10.798
Epoch: 03 | Time: 0m 30s
Train Loss: 2.604 | Train PPL: 13.521
Val. Loss: 2.124 | Val. PPL: 8.361
Epoch: 04 | Time: 0m 30s
Train Loss: 2.369 | Train PPL: 10.685
Val. Loss: 1.991 | Val. PPL: 7.323
Epoch: 05 | Time: 0m 30s
Train Loss: 2.209 | Train PPL: 9.107
Val. Loss: 1.908 | Val. PPL: 6.737
Epoch: 06 | Time: 0m 30s
Train Loss: 2.097 | Train PPL: 8.139
Val. Loss: 1.864 | Val. PPL: 6.448
Epoch: 07 | Time: 0m 30s
Train Loss: 2.009 | Train PPL: 7.456
Val. Loss: 1.810 | Val. PPL: 6.110
Epoch: 08 | Time: 0m 31s
Train Loss: 1.932 | Train PPL: 6.904
Val. Loss: 1.779 | Val. PPL: 5.922
Epoch: 09 | Time: 0m 30s
Train Loss: 1.868 | Train PPL: 6.474
Val. Loss: 1.762 | Val. PPL: 5.825
Epoch: 10 | Time: 0m 30s
Train Loss: 1.817 | Train PPL: 6.156
Val. Loss: 1.736 | Val. PPL: 5.674
'''Then load the parameters which obtained the lowest validation loss and calculate the loss over the test set.
model.load_state_dict(torch.load('tut5-model.pt'))
test_loss = evaluate(model, test_iterator, criterion)
print(f'| Test Loss: {test_loss:.3f} | Test PPL: {math.exp(test_loss):7.3f} |') # | Test Loss: 1.795 | Test PPL: 6.022 |Inference
Now can do translations from model with the translate_sentence function below.
The steps taken are:
- tokenize the source sentence if it has not been tokenized (is a string)
- append the
and tokens - numericalize the source sentence
- convert it to a tensor and add a batch dimension
- feed the source sentence into the encoder
- create a list to hold the output sentence, initialized with an
token - while have not hit a maximum length
- convert the current output sentence prediction into a tensor with a batch dimension
- place the current output and the two encoder outputs into the decoder
- get next output token prediction from decoder
- add prediction to current output sentence prediction
- break if the prediction was an
token
- convert the output sentence from indexes to tokens
- return the output sentence (with the
token removed) and the attention from the last layer
def translate_sentence(sentence, src_field, trg_field, model, device, max_len = 50):
model.eval()
if isinstance(sentence, str):
nlp = spacy.load('de')
tokens = [token.text.lower() for token in nlp(sentence)]
else:
tokens = [token.lower() for token in sentence]
tokens = [src_field.init_token] + tokens + [src_field.eos_token]
src_indexes = [src_field.vocab.stoi[token] for token in tokens]
src_tensor = torch.LongTensor(src_indexes).unsqueeze(0).to(device)
with torch.no_grad():
encoder_conved, encoder_combined = model.encoder(src_tensor)
trg_indexes = [trg_field.vocab.stoi[trg_field.init_token]]
for i in range(max_len):
trg_tensor = torch.LongTensor(trg_indexes).unsqueeze(0).to(device)
with torch.no_grad():
output, attention = model.decoder(trg_tensor, encoder_conved, encoder_combined)
pred_token = output.argmax(2)[:,-1].item()
trg_indexes.append(pred_token)
if pred_token == trg_field.vocab.stoi[trg_field.eos_token]:
break
trg_tokens = [trg_field.vocab.itos[i] for i in trg_indexes]
return trg_tokens[1:], attentionNext, have a function what will display how much the model pays attention to each input token during each step of the decoding.
def display_attention(sentence, translation, attention):
fig = plt.figure(figsize=(10,10))
ax = fig.add_subplot(111)
attention = attention.squeeze(0).cpu().detach().numpy()
cax = ax.matshow(attention, cmap='bone')
ax.tick_params(labelsize=15)
ax.set_xticklabels(['']+['<sos>']+[t.lower() for t in sentence]+['<eos>'],
rotation=45)
ax.set_yticklabels(['']+translation)
ax.xaxis.set_major_locator(ticker.MultipleLocator(1))
ax.yaxis.set_major_locator(ticker.MultipleLocator(1))
plt.show()
plt.close()Then finally start translating some sentences. Note: these sentences have been cherry picked.
First, get an example from the training set:
example_idx = 2
src = vars(train_data.examples[example_idx])['src']
trg = vars(train_data.examples[example_idx])['trg']
print(f'src = {src}') # src = ['ein', 'kleines', 'mädchen', 'klettert', 'in', 'ein', 'spielhaus', 'aus', 'holz', '.']
print(f'trg = {trg}') # trg = ['a', 'little', 'girl', 'climbing', 'into', 'a', 'wooden', 'playhouse', '.']Then pass it into translate_sentence function which gives us the predicted translation tokens as well as the attention.
Can see that it doesn’t give the exact same translation, however it does capture the same meaning as the original. It is actual a more literal translation as aus holz literally translates to of wood, so a wooden playhouse is the same thing as a playhouse made of wood.
translation, attention = translate_sentence(src, SRC, TRG, model, device)
print(f'predicted trg = {translation}')# predicted trg = ['a', 'little', 'girl', 'is', 'climbing', 'into', 'a', 'playhouse', 'made', 'of', 'wood', '.', '<eos>']Can view the attention of the model, making sure it gives sensibile looking results.
Can see it correctly pays attention to aus when translation both made and of.
display_attention(src, translation, attention)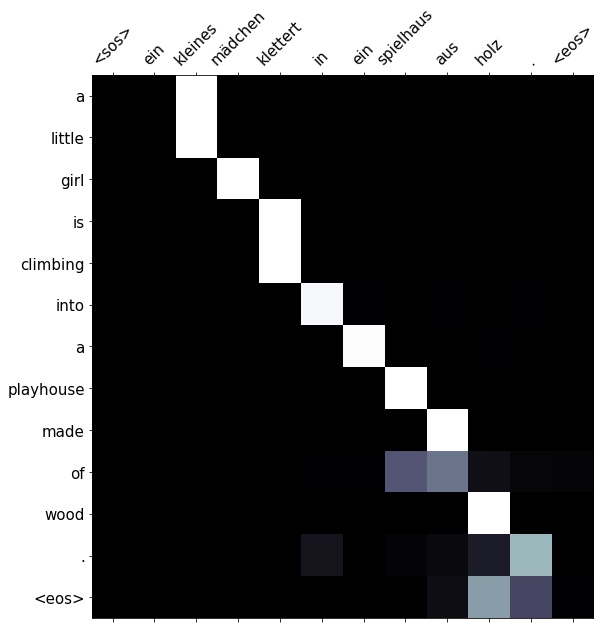
Let’s see how well it translates an example that is not in the training set.
example_idx = 10
src = vars(valid_data.examples[example_idx])['src']
trg = vars(valid_data.examples[example_idx])['trg']
print(f'src = {src}') # src = ['ein', 'junge', 'mit', 'kopfhörern', 'sitzt', 'auf', 'den', 'schultern', 'einer', 'frau', '.']
print(f'trg = {trg}') # trg = ['a', 'boy', 'wearing', 'headphones', 'sits', 'on', 'a', 'woman', "'s", 'shoulders', '.']The model manages to do a decent job at this one, except for changing wearing to in.
translation, attention = translate_sentence(src, SRC, TRG, model, device)
print(f'predicted trg = {translation}') # predicted trg = ['a', 'boy', 'in', 'headphones', 'sits', 'on', 'the', 'shoulders', 'of', 'a', 'woman', '.', '<eos>']
# Again, can see the attention is applied to sensible words - junge for boy, etc.
display_attention(src, translation, attention)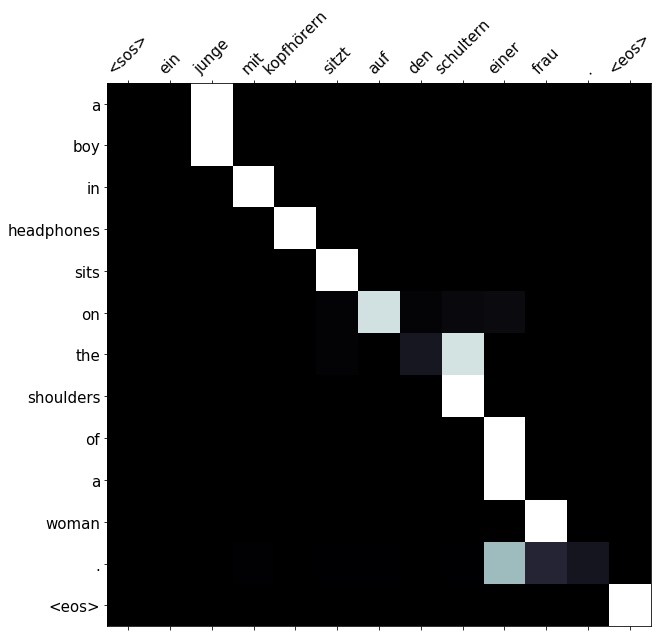
Finally, let’s get an example from the test set.
example_idx = 9
src = vars(test_data.examples[example_idx])['src']
trg = vars(test_data.examples[example_idx])['trg']
print(f'src = {src}') # src = ['ein', 'mann', 'in', 'einer', 'weste', 'sitzt', 'auf', 'einem', 'stuhl', 'und', 'hält', 'magazine', '.']
print(f'trg = {trg}') # trg = ['a', 'man', 'in', 'a', 'vest', 'is', 'sitting', 'in', 'a', 'chair', 'and', 'holding', 'magazines', '.']Get a generally correct translation here, although the model changed sitting in a chair to sitting on a chair and removes the and.
The word magazines is not in vocabulary, hence it was output as an unknown token.
translation, attention = translate_sentence(src, SRC, TRG, model, device)
print(f'predicted trg = {translation}') # predicted trg = ['a', 'man', 'in', 'a', 'vest', 'is', 'sitting', 'on', 'a', 'chair', 'holding', '<unk>', '.', '<eos>']
# The attention seems to be correct. No attention is payed to und as it never outputs and and the word magazine is correctly attended to even though it is not in the output vocabulary.
display_attention(src, translation, attention)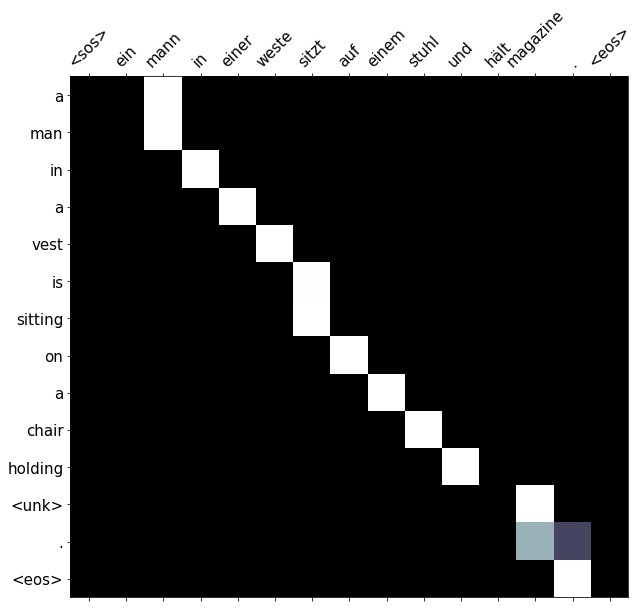
BLEU
Finally, calculate the BLEU score for the model.
from torchtext.data.metrics import bleu_score
def calculate_bleu(data, src_field, trg_field, model, device, max_len = 50):
trgs = []
pred_trgs = []
for datum in data:
src = vars(datum)['src']
trg = vars(datum)['trg']
pred_trg, _ = translate_sentence(src, src_field, trg_field, model, device, max_len)
#cut off <eos> token
pred_trg = pred_trg[:-1]
pred_trgs.append(pred_trg)
trgs.append([trg])
return bleu_score(pred_trgs, trgs)Get a BLEU score of ~33, compared to the attention based RNN model which gave us a ~28. This is a ~17% improvement in BLEU score.
bleu_score = calculate_bleu(test_data, SRC, TRG, model, device)
print(f'BLEU score = {bleu_score*100:.2f}') # BLEU score = 33.29