4 - Packed Padded Sequences, Masking, Inference and BLEU
4 - Packed Padded Sequences, Masking, Inference and BLEU
Introduction
This part will be adding a few improvements - packed padded sequences and masking - to the model from the previous tutorial. Packed padded sequences are used to tell RNN to skip over padding tokens in encoder. Masking explicitly forces the model to ignore certain values, such as attention over padded elements. Both of these techniques are commonly used in NLP.
Also will look at how to use model for inference, by giving it a sentence, seeing what it translates it as and seeing where exactly it pays attention to when translating each word.
Finally, will use the BLEU metric to measure the quality of translations.
Preparing Data
First, import all the modules as before, with the addition of the matplotlib modules used for viewing the attention.
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torchtext.datasets import TranslationDataset, Multi30k
from torchtext.data import Field, BucketIterator
import spacy
import numpy as np
import random
import math
import time
SEED = 1234
random.seed(SEED)
np.random.seed(SEED)
torch.manual_seed(SEED)
torch.cuda.manual_seed(SEED)
torch.backends.cudnn.deterministic = True
spacy_de = spacy.load('de')
spacy_en = spacy.load('en')
# create tokenizer
def tokenize_de(text):
"""
Tokenizes German text from a string into a list of strings
"""
return [tok.text for tok in spacy_de.tokenizer(text)]
def tokenize_en(text):
"""
Tokenizes English text from a string into a list of strings
"""
return [tok.text for tok in spacy_en.tokenizer(text)]Create field. When using packed padded sequences, need to tell PyTorch how long the actual (non-padded) sequences are. TorchText’s Field objects allow us to use the include_lengths argument, this will cause our batch.src to be a tuple. The first element of the tuple is the same as before, a batch of numericalized source sentence as a tensor, and the second element is the non-padded lengths of each source sentence within the batch.
SRC = Field(tokenize=tokenize_de,
init_token='<sos>',
eos_token='<eos>',
lower=True,
include_lengths = True)
TRG = Field(tokenize = tokenize_en,
init_token='<sos>',
eos_token='<eos>',
lower=True)
# Load data
train_data, valid_data, test_data = Multi30k.splits(exts = ('.de', '.en'), fields = (SRC, TRG))
print(vars(train_data.examples[0]))
# {'src': ['zwei', 'junge', 'weiße', 'männer', 'sind', 'im', 'freien', 'in', 'der', 'nähe', 'vieler', 'büsche', '.'], 'trg': ['two', 'young', ',', 'white', 'males', 'are', 'outside', 'near', 'many', 'bushes', '.']}
# Build the vocabulary
SRC.build_vocab(train_data, min_freq = 2)
TRG.build_vocab(train_data, min_freq = 2)Define the device and create iterators
One quirk about packed padded sequences is that all elements in the batch need to be sorted by their non-padded lengths in descending order, i.e. the first sentence in the batch needs to be the longest. Use two arguments of the iterator to handle this, sort_within_batch which tells the iterator that the contents of the batch need to be sorted, and sort_key a function which tells the iterator how to sort the elements in the batch. Here sort by the length of the src sentence.
BATCH_SIZE = 128
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
train_iterator, valid_iterator, test_iterator = BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size = BATCH_SIZE,
sort_within_batch = True,
sort_key = lambda x : len(x.src),
device = device)Building the Seq2Seq Model
Encoder
The changes of Encoder all within the forward method. It now accepts the lengths of the source sentences(src_lec) as well as the sentences themselves(src).
After the source sentence (padded automatically within the iterator) has been embedded, can then use pack_padded_sequence on it with the lengths of the sentences. packed_embedded will then be packed padded sequence. This can be then fed to RNN as normal which will return packed_outputs, a packed tensor containing all of the hidden states from the sequence, and hidden which is simply the final hidden state from sequence. hidden is a standard tensor and not packed in any way, the only difference is that as the input was a packed sequence, this tensor is from the final non-padded element in the sequence.
Then unpack packed_outputs using pad_packed_sequence which returns the outputs and the lengths of each(not used).
The first dimension of outputs is the padded sequence lengths however due to using a packed padded sequence the values of tensors when a padding token was the input will be all zeros.
为了使一个batch size的数据的seq len一样, 加入很多pad token. 然而, 例如将[‘yes’,’
class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, enc_hid_dim, dec_hid_dim, dropout):
super().__init__()
self.embedding = nn.Embedding(input_dim, emb_dim)
self.rnn = nn.GRU(emb_dim, enc_hid_dim, bidirectional = True)
self.fc = nn.Linear(enc_hid_dim * 2, dec_hid_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, src, src_len):
#src = [src len, batch size]
#src_len = [batch size]
embedded = self.dropout(self.embedding(src))
#embedded = [src len, batch size, emb dim]
packed_embedded = nn.utils.rnn.pack_padded_sequence(embedded, src_len)
packed_outputs, hidden = self.rnn(packed_embedded)
#packed_outputs is a packed sequence containing all hidden states
#hidden is now from the final non-padded element in the batch
outputs, _ = nn.utils.rnn.pad_packed_sequence(packed_outputs)
#outputs is now a non-packed sequence, all hidden states obtained
# when the input is a pad token are all zeros
#outputs = [src len, batch size, hid dim * num directions]
#hidden = [n layers * num directions, batch size, hid dim]
#hidden is stacked [forward_1, backward_1, forward_2, backward_2, ...]
#outputs are always from the last layer
#hidden [-2, :, : ] is the last of the forwards RNN
#hidden [-1, :, : ] is the last of the backwards RNN
#initial decoder hidden is final hidden state of the forwards and backwards
# encoder RNNs fed through a linear layer
hidden = torch.tanh(self.fc(torch.cat((hidden[-2,:,:], hidden[-1,:,:]), dim = 1)))
#outputs = [src len, batch size, enc hid dim * 2]
#hidden = [batch size, dec hid dim]
return outputs, hiddenAttention
The attention module is where calculate the attention values over the source sentence.
Previously, it is allowed this module to “pay attention” to padding tokens within the source sentence. However, using masking, it can force the attention to only be over non-padding elements.
The forward function now takes a mask input. This is a [batch size, source sentence length] tensor that is 1 when the source sentence token is not a padding token, and 0 when it is a padding token. For example, if the source sentence is: [“hello”, “how”, “are”, “you”, “?”,
Apply the mask after the attention has been calculated, but before it has been normalized by the softmax function. It is applied using masked_fill. This fills the tensor at each element where the first argument (mask == 0) is true, with the value given by the second argument (-1e10). In other words, it will take the un-normalized attention values, and change the attention values over padded elements to be -1e10. As these numbers will be miniscule compared to the other values they will become zero when passed through the softmax layer, ensuring no attention is payed to padding tokens in the source sentence. (To sum up, replace all pad tokens with small numbers before put into softmax, to ensure it will pay no attention to pad token)
mask就是[batch size, source sentence length]由0和1组成的序列, 0的部分为pad token, 剩余的为1. 利用pytorch的mask_fill(), 将所有0的部分替换成一个非常小的数, 这样在做softmax的计算时候, pad的部分就会是0, 不会影响结果.
a = torch.tensor([1, 2, 3, 4],dtype=torch.float)
a = a.masked_fill(mask=torch.tensor([0, 0, 1, 1],dtype=torch.bool), value=-np.inf)
print(a) # tensor([1., 2., -inf, -inf])
b = F.softmax(a,dim=0)
print(b) # tensor([0.2689, 0.7311, 0.0000, 0.0000])class Attention(nn.Module):
def __init__(self, enc_hid_dim, dec_hid_dim):
super().__init__()
self.attn = nn.Linear((enc_hid_dim * 2) + dec_hid_dim, dec_hid_dim)
self.v = nn.Linear(dec_hid_dim, 1, bias = False)
def forward(self, hidden, encoder_outputs, mask):
#hidden = [batch size, dec hid dim]
#encoder_outputs = [src len, batch size, enc hid dim * 2]
batch_size = encoder_outputs.shape[1]
src_len = encoder_outputs.shape[0]
#repeat decoder hidden state src_len times
hidden = hidden.unsqueeze(1).repeat(1, src_len, 1)
encoder_outputs = encoder_outputs.permute(1, 0, 2)
#hidden = [batch size, src len, dec hid dim]
#encoder_outputs = [batch size, src len, enc hid dim * 2]
energy = torch.tanh(self.attn(torch.cat((hidden, encoder_outputs), dim = 2)))
#energy = [batch size, src len, dec hid dim]
attention = self.v(energy).squeeze(2)
#attention = [batch size, src len]
attention = attention.masked_fill(mask == 0, -1e10) # !!!
return F.softmax(attention, dim = 1)Decoder
The decoder needs to accept a mask over the source sentence and pass this to the attention module. In order to view the values of attention during inference, so it also return the attention tensor.
def __init__(self, output_dim, emb_dim, enc_hid_dim, dec_hid_dim, dropout, attention):
super().__init__()
self.output_dim = output_dim
self.attention = attention
self.embedding = nn.Embedding(output_dim, emb_dim)
self.rnn = nn.GRU((enc_hid_dim * 2) + emb_dim, dec_hid_dim)
self.fc_out = nn.Linear((enc_hid_dim * 2) + dec_hid_dim + emb_dim, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, input, hidden, encoder_outputs, mask):
#input = [batch size]
#hidden = [batch size, dec hid dim]
#encoder_outputs = [src len, batch size, enc hid dim * 2]
#mask = [batch size, src len]
input = input.unsqueeze(0)
#input = [1, batch size]
embedded = self.dropout(self.embedding(input))
#embedded = [1, batch size, emb dim]
a = self.attention(hidden, encoder_outputs, mask)
#a = [batch size, src len]
a = a.unsqueeze(1)
#a = [batch size, 1, src len]
encoder_outputs = encoder_outputs.permute(1, 0, 2)
#encoder_outputs = [batch size, src len, enc hid dim * 2]
weighted = torch.bmm(a, encoder_outputs)
#weighted = [batch size, 1, enc hid dim * 2]
weighted = weighted.permute(1, 0, 2)
#weighted = [1, batch size, enc hid dim * 2]
rnn_input = torch.cat((embedded, weighted), dim = 2)
#rnn_input = [1, batch size, (enc hid dim * 2) + emb dim]
output, hidden = self.rnn(rnn_input, hidden.unsqueeze(0))
#output = [seq len, batch size, dec hid dim * n directions]
#hidden = [n layers * n directions, batch size, dec hid dim]
#seq len, n layers and n directions will always be 1 in this decoder, therefore:
#output = [1, batch size, dec hid dim]
#hidden = [1, batch size, dec hid dim]
#this also means that output == hidden
assert (output == hidden).all()
embedded = embedded.squeeze(0)
output = output.squeeze(0)
weighted = weighted.squeeze(0)
prediction = self.fc_out(torch.cat((output, weighted, embedded), dim = 1))
#prediction = [batch size, output dim]
return prediction, hidden.squeeze(0), a.squeeze(1)Seq2Seq Model
The overarching seq2seq model also needs a few changes for packed padded sequences, masking and inference.
Need to tell it what the indexes are for the pad token and also pass the source sentence lengths as input to the forward function.
Use the pad token index to create the masks, by creating a mask tensor that is 1 wherever the source sentence is not equal to the pad token. This is all done within the create_mask function.
The sequence lengths as needed to pass to the encoder to use packed padded sequences.
The attention at each time-step is stored in the attentions
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, src_pad_idx, device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.src_pad_idx = src_pad_idx
self.device = device
def create_mask(self, src):
mask = (src != self.src_pad_idx).permute(1, 0)
return mask
def forward(self, src, src_len, trg, teacher_forcing_ratio = 0.5):
#src = [src len, batch size]
#src_len = [batch size]
#trg = [trg len, batch size]
#teacher_forcing_ratio is probability to use teacher forcing
#e.g. if teacher_forcing_ratio is 0.75 we use teacher forcing 75% of the time
batch_size = src.shape[1]
trg_len = trg.shape[0]
trg_vocab_size = self.decoder.output_dim
#tensor to store decoder outputs
outputs = torch.zeros(trg_len, batch_size, trg_vocab_size).to(self.device)
#encoder_outputs is all hidden states of the input sequence, back and forwards
#hidden is the final forward and backward hidden states, passed through a linear layer
encoder_outputs, hidden = self.encoder(src, src_len)
#first input to the decoder is the <sos> tokens
input = trg[0,:]
mask = self.create_mask(src)
#mask = [batch size, src len]
for t in range(1, trg_len):
#insert input token embedding, previous hidden state, all encoder hidden states
# and mask
#receive output tensor (predictions) and new hidden state
output, hidden, _ = self.decoder(input, hidden, encoder_outputs, mask)
#place predictions in a tensor holding predictions for each token
outputs[t] = output
#decide if we are going to use teacher forcing or not
teacher_force = random.random() < teacher_forcing_ratio
#get the highest predicted token from our predictions
top1 = output.argmax(1)
#if teacher forcing, use actual next token as next input
#if not, use predicted token
input = trg[t] if teacher_force else top1
return outputsTraining the Seq2Seq Model
Initialise encoder, decoder and seq2seq model as before.
INPUT_DIM = len(SRC.vocab)
OUTPUT_DIM = len(TRG.vocab)
ENC_EMB_DIM = 256
DEC_EMB_DIM = 256
ENC_HID_DIM = 512
DEC_HID_DIM = 512
ENC_DROPOUT = 0.5
DEC_DROPOUT = 0.5
attn = Attention(ENC_HID_DIM, DEC_HID_DIM)
enc = Encoder(INPUT_DIM, ENC_EMB_DIM, ENC_HID_DIM, DEC_HID_DIM, ENC_DROPOUT)
dec = Decoder(OUTPUT_DIM, DEC_EMB_DIM, ENC_HID_DIM, DEC_HID_DIM, DEC_DROPOUT, attn)
model = Seq2Seq(enc, dec, device).to(device)Then, initialize the model parameters.
def init_weights(m):
for name, param in m.named_parameters():
if 'weight' in name:
nn.init.normal_(param.data, mean=0, std=0.01)
else:
nn.init.constant_(param.data, 0)
model.apply(init_weights)
'''
Seq2Seq(
(encoder): Encoder(
(embedding): Embedding(7853, 256)
(rnn): GRU(256, 512, bidirectional=True)
(fc): Linear(in_features=1024, out_features=512, bias=True)
(dropout): Dropout(p=0.5, inplace=False)
)
(decoder): Decoder(
(attention): Attention(
(attn): Linear(in_features=1536, out_features=512, bias=True)
(v): Linear(in_features=512, out_features=1, bias=False)
)
(embedding): Embedding(5893, 256)
(rnn): GRU(1280, 512)
(fc_out): Linear(in_features=1792, out_features=5893, bias=True)
(dropout): Dropout(p=0.5, inplace=False)
)
)
'''Print out the number of trainable parameters in the model, noticing that it has the exact same amount of parameters as the model without these improvements.
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f'The model has {count_parameters(model):,} trainable parameters') # The model has 20,518,405 trainable parametersInitiaize optimizer and the loss function, making sure to ignore the loss on
optimizer = optim.Adam(model.parameters())
TRG_PAD_IDX = TRG.vocab.stoi[TRG.pad_token]
criterion = nn.CrossEntropyLoss(ignore_index = TRG_PAD_IDX)Next, will define training and evaluation loops.
As using include_lengths = True for source field, batch.src is now a tuple with the first element being the numericalized tensor representing the sentence and the second element being the lengths of each sentence within the batch.
Model also returns the attention vectors over the batch of source source sentences for each decoding time-step. It won’t be used these during the training/evaluation, but will be used later for inference.
def train(model, iterator, optimizer, criterion, clip):
model.train()
epoch_loss = 0
for i, batch in enumerate(iterator):
src, src_len = batch.src
trg = batch.trg
optimizer.zero_grad()
output = model(src, src_len, trg)
#trg = [trg len, batch size]
#output = [trg len, batch size, output dim]
output_dim = output.shape[-1]
output = output[1:].view(-1, output_dim)
trg = trg[1:].view(-1)
#trg = [(trg len - 1) * batch size]
#output = [(trg len - 1) * batch size, output dim]
loss = criterion(output, trg)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), clip)
optimizer.step()
epoch_loss += loss.item()
return epoch_loss / len(iterator)
def evaluate(model, iterator, criterion):
model.eval()
epoch_loss = 0
with torch.no_grad():
for i, batch in enumerate(iterator):
src, src_len = batch.src
trg = batch.trg
output = model(src, src_len, trg, 0) #turn off teacher forcing
#trg = [trg len, batch size]
#output = [trg len, batch size, output dim]
output_dim = output.shape[-1]
output = output[1:].view(-1, output_dim)
trg = trg[1:].view(-1)
#trg = [(trg len - 1) * batch size]
#output = [(trg len - 1) * batch size, output dim]
loss = criterion(output, trg)
epoch_loss += loss.item()
return epoch_loss / len(iterator)
def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secsThe penultimate step is to train model. Notice how it takes almost half the time as model without the improvements added in this notebook.
N_EPOCHS = 10
CLIP = 1
best_valid_loss = float('inf')
for epoch in range(N_EPOCHS):
start_time = time.time()
train_loss = train(model, train_iterator, optimizer, criterion, CLIP)
valid_loss = evaluate(model, valid_iterator, criterion)
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), 'tut4-model.pt')
print(f'Epoch: {epoch+1:02} | Time: {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train PPL: {math.exp(train_loss):7.3f}')
print(f'\t Val. Loss: {valid_loss:.3f} | Val. PPL: {math.exp(valid_loss):7.3f}')
'''
Epoch: 01 | Time: 0m 32s
Train Loss: 5.062 | Train PPL: 157.888
Val. Loss: 4.809 | Val. PPL: 122.606
Epoch: 02 | Time: 0m 32s
Train Loss: 4.084 | Train PPL: 59.374
Val. Loss: 4.108 | Val. PPL: 60.819
Epoch: 03 | Time: 0m 32s
Train Loss: 3.293 | Train PPL: 26.919
Val. Loss: 3.541 | Val. PPL: 34.504
Epoch: 04 | Time: 0m 33s
Train Loss: 2.808 | Train PPL: 16.583
Val. Loss: 3.320 | Val. PPL: 27.670
Epoch: 05 | Time: 0m 33s
Train Loss: 2.436 | Train PPL: 11.427
Val. Loss: 3.242 | Val. PPL: 25.575
Epoch: 06 | Time: 0m 34s
Train Loss: 2.159 | Train PPL: 8.659
Val. Loss: 3.273 | Val. PPL: 26.389
Epoch: 07 | Time: 0m 32s
Train Loss: 1.937 | Train PPL: 6.937
Val. Loss: 3.172 | Val. PPL: 23.856
Epoch: 08 | Time: 0m 31s
Train Loss: 1.732 | Train PPL: 5.651
Val. Loss: 3.231 | Val. PPL: 25.297
Epoch: 09 | Time: 0m 31s
Train Loss: 1.601 | Train PPL: 4.960
Val. Loss: 3.294 | Val. PPL: 26.957
Epoch: 10 | Time: 0m 31s
Train Loss: 1.491 | Train PPL: 4.441
Val. Loss: 3.278 | Val. PPL: 26.535
'''Finally, load the parameters from best validation loss and get results on the test set.
Get the improved test perplexity whilst almost being twice as fast!
model.load_state_dict(torch.load('tut3-model.pt'))
test_loss = evaluate(model, test_iterator, criterion)
print(f'| Test Loss: {test_loss:.3f} | Test PPL: {math.exp(test_loss):7.3f} |') # | Test Loss: 3.154 | Test PPL: 23.441 |Inference
Now can use trained model to generate translations.
Note: these translations will be poor compared to examples shown in paper as they use hidden dimension sizes of 1000 and train for 4 days.
translate_sentence function will do the following:
- ensure model is in evaluation mode, which it should always be for inference
- tokenize the source sentence if it has not been tokenized (is a string)
- numericalize the source sentence
- convert it to a tensor and add a batch dimension
- get the length of the source sentence and convert to a tensor
- feed the source sentence into the encoder
- create the mask for the source sentence
- create a list to hold the output sentence, initialized with an
token - create a tensor to hold the attention values
- while have’t hit a maximum length
- get the input tensor, which should be either
or the last predicted token - feed the input, all encoder outputs, hidden state and mask into the decoder
- store attention values
- get the predicted next token
- add prediction to current output sentence prediction
- break if the prediction was an
token
- get the input tensor, which should be either
- convert the output sentence from indexes to tokens
- return the output sentence (with the
token removed) and the attention values over the sequence
def translate_sentence(sentence, src_field, trg_field, model, device, max_len = 50):
model.eval()
# tokenize input
if isinstance(sentence, str):
nlp = spacy.load('de')
tokens = [token.text.lower() for token in nlp(sentence)]
else:
tokens = [token.lower() for token in sentence]
# add <sos> and <eos>
tokens = [src_field.init_token] + tokens + [src_field.eos_token]
# get input's one-hot vec
src_indexes = [src_field.vocab.stoi[token] for token in tokens]
# add a batch dim and convert into tensor
src_tensor = torch.LongTensor(src_indexes).unsqueeze(1).to(device)
# convert input's len into tensor (for packed/paded seq)
src_len = torch.LongTensor([len(src_indexes)]).to(device)
with torch.no_grad():
encoder_outputs, hidden = model.encoder(src_tensor, src_len)
mask = model.create_mask(src_tensor)
# get first decoder input (<sos>)'s one hot
trg_indexes = [trg_field.vocab.stoi[trg_field.init_token]]
# create a array to store attetnion
attentions = torch.zeros(max_len, 1, len(src_indexes)).to(device)
for i in range(max_len):
trg_tensor = torch.LongTensor([trg_indexes[-1]]).to(device)
with torch.no_grad():
output, hidden, attention = model.decoder(trg_tensor, hidden, encoder_outputs, mask)
attentions[i] = attention
pred_token = output.argmax(1).item()
trg_indexes.append(pred_token)
if pred_token == trg_field.vocab.stoi[trg_field.eos_token]:
break
trg_tokens = [trg_field.vocab.itos[i] for i in trg_indexes]
# remove output's <sos>
return trg_tokens[1:], attentions[:len(trg_tokens)-1]Next, make a function that displays the model’s attention over the source sentence for each target token generated.
def display_attention(sentence, translation, attention):
fig = plt.figure(figsize=(10,10))
ax = fig.add_subplot(111)
attention = attention.squeeze(1).cpu().detach().numpy()
cax = ax.matshow(attention, cmap='bone')
ax.tick_params(labelsize=15)
ax.set_xticklabels(['']+['<sos>']+[t.lower() for t in sentence]+['<eos>'],
rotation=45)
ax.set_yticklabels(['']+translation)
ax.xaxis.set_major_locator(ticker.MultipleLocator(1))
ax.yaxis.set_major_locator(ticker.MultipleLocator(1))
plt.show()
plt.close()Now, grab some translations from dataset and see how well the model did. Note, the examples showed in here are cherry picked so that it could give something interesting to look at. Can change the example_idx value to look at different examples.
First, get a source and target from dataset.
example_idx = 12
src = vars(train_data.examples[example_idx])['src']
trg = vars(train_data.examples[example_idx])['trg']
print(f'src = {src}') # src = ['ein', 'schwarzer', 'hund', 'und', 'ein', 'gefleckter', 'hund', 'kämpfen', '.']
print(f'trg = {trg}') # trg = ['a', 'black', 'dog', 'and', 'a', 'spotted', 'dog', 'are', 'fighting']Then use translate_sentence function to get predicted translation and attention. Show this graphically by having the source sentence on the x-axis and the predicted translation on the y-axis. The lighter the square at the intersection between two words, the more attention the model gave to that source word when translating that target word.
Below is an example the model attempted to translate, it gets the translation correct except changes are fighting to just fighting.
translation, attention = translate_sentence(src, SRC, TRG, model, device)
print(f'predicted trg = {translation}') # predicted trg = ['a', 'black', 'dog', 'and', 'a', 'spotted', 'dog', 'fighting', '.', '<eos>']
display_attention(src, translation, attention)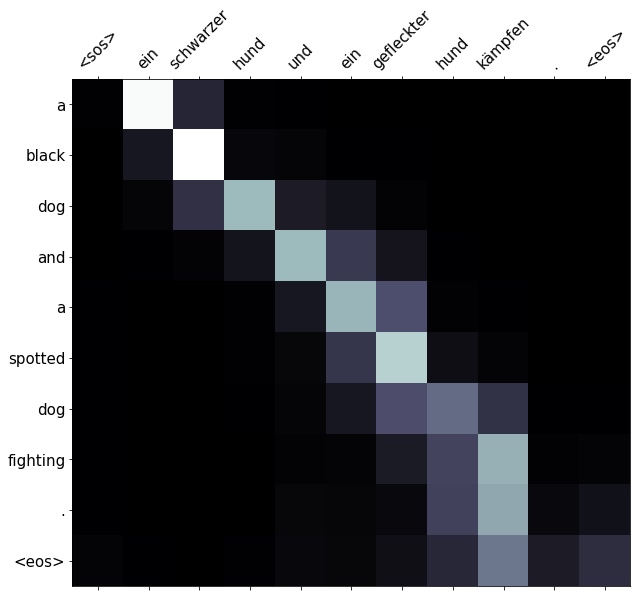 Translations from the
Translations from the training set could simply be memorized by the model. So it’s only fair when look at translations from the validation and testing set too.
Starting with the validation set, let’s get an example.
example_idx = 14
src = vars(valid_data.examples[example_idx])['src']
trg = vars(valid_data.examples[example_idx])['trg']
print(f'src = {src}') # src = ['eine', 'frau', 'spielt', 'ein', 'lied', 'auf', 'ihrer', 'geige', '.']
print(f'trg = {trg}') # trg = ['a', 'female', 'playing', 'a', 'song', 'on', 'her', 'violin', '.']
translation, attention = translate_sentence(src, SRC, TRG, model, device)
print(f'predicted trg = {translation}') # predicted trg = ['a', 'woman', 'playing', 'a', 'song', 'on', 'her', 'violin', '.', '<eos>']
display_attention(src, translation, attention)The translation is the same except for swapping female with woman.
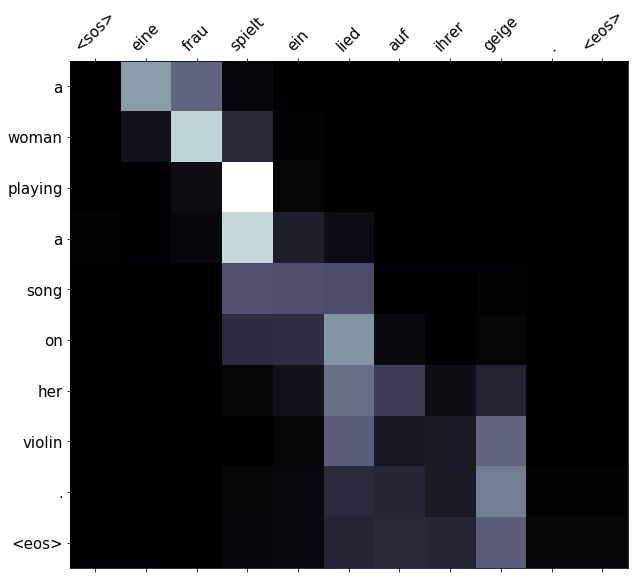
Finally, let’s get an example from the test set.
example_idx = 18
src = vars(test_data.examples[example_idx])['src']
trg = vars(test_data.examples[example_idx])['trg']
print(f'src = {src}') # src = ['die', 'person', 'im', 'gestreiften', 'shirt', 'klettert', 'auf', 'einen', 'berg', '.']
print(f'trg = {trg}') # trg = ['the', 'person', 'in', 'the', 'striped', 'shirt', 'is', 'mountain', 'climbing', '.']Again, it produces a slightly different translation than target, a more literal version of the source sentence. It swaps mountain climbing for climbing on a mountain.
translation, attention = translate_sentence(src, SRC, TRG, model, device)
print(f'predicted trg = {translation}') # predicted trg = ['the', 'person', 'in', 'the', 'striped', 'shirt', 'is', 'climbing', 'on', 'a', 'mountain', '.', '<eos>']
display_attention(src, translation, attention)
BLEU
Previous tutorial only cared about the loss/perplexity of the model. However, the metrics that are specifically designed for measuring the quality of a translation - the most popular is BLEU. BLEU looks at the overlap in the predicted and actual target sequences in terms of their n-grams. It will give a number between 0 and 1 for each sequence, where 1 means there is perfect overlap, i.e. a perfect translation, although is usually shown between 0 and 100. BLEU was designed for multiple candidate translations per source sequence, however in this dataset, it only has one candidate per source.
Define a calculate_bleu function which calculates the BLEU score over a provided TorchText dataset. This function creates a corpus of the actual and predicted translation for each source sentence and then calculates the BLEU score.
from torchtext.data.metrics import bleu_score
def calculate_bleu(data, src_field, trg_field, model, device, max_len = 50):
trgs = []
pred_trgs = []
for datum in data:
src = vars(datum)['src']
trg = vars(datum)['trg']
pred_trg, _ = translate_sentence(src, src_field, trg_field, model, device, max_len)
# cut off <eos> token
pred_trg = pred_trg[:-1]
pred_trgs.append(pred_trg)
trgs.append([trg])
return bleu_score(pred_trgs, trgs)Get a BLEU of around 29. If compare it to the paper that the attention model is attempting to replicate, they achieve a BLEU score of 26.75. This is similar to our score, however they are using a completely different dataset and their model size is much larger - 1000 hidden dimensions which takes 4 days to train!
The most useful part of a BLEU score is that it can be used to compare different models on the same dataset, where the one with the higher BLEU score is “better”.
bleu_score = calculate_bleu(test_data, SRC, TRG, model, device)
print(f'BLEU score = {bleu_score*100:.2f}') # BLEU score = 29.04