Jot Down
PyTorch nn 与 nn.functional 区别
其实这两个是差不多的,不过一个包装好的类,一个是可以直接调用的函数. 下面以卷积Conv1d为例:
首先是torch.nn下的Conv1d:
class Conv1d(_ConvNd):
def __init__(self, in_channels, out_channels, kernel_size, stride=1,
padding=0, dilation=1, groups=1, bias=True):
kernel_size = _single(kernel_size)
stride = _single(stride)
padding = _single(padding)
dilation = _single(dilation)
super(Conv1d, self).__init__(
in_channels, out_channels, kernel_size, stride, padding, dilation,
False, _single(0), groups, bias)
def forward(self, input):
return F.conv1d(input, self.weight, self.bias, self.stride,
self.padding, self.dilation, self.groups)torch.nn.functional下的conv1d:
def conv1d(input, weight, bias=None, stride=1, padding=0, dilation=1,
groups=1):
if input is not None and input.dim() != 3:
raise ValueError("Expected 3D tensor as input, got {}D tensor instead.".format(input.dim()))
f = ConvNd(_single(stride), _single(padding), _single(dilation), False,
_single(0), groups, torch.backends.cudnn.benchmark,
torch.backends.cudnn.deterministic, torch.backends.cudnn.enabled)
return f(input, weight, bias)可以看到torch.nn下的Conv1d类在forward时调用了nn.functional下的conv1d,当然最终的计算是通过C++编写的THNN库中的ConvNd进行计算的,因此这两个其实是互相调用的关系.
为什么需要这两个功能如此相近的模块??
如果只保留nn.functional下的函数的话,在训练或者使用时,就要手动去维护weight, bias, stride这些中间量的值,这显然是给用户带来了不便. 而如果只保留nn下的类的话,其实就牺牲了一部分灵活性,因为做一些简单的计算都需要创造一个类,这也与PyTorch的风格不符.
pytorch loss function
Cross EntropyLoss
交叉熵损失函数. 在二分的情况下,模型最后需要预测的结果只有两种情况,对于每个类别我们的预测得到的概率为 $p$ 和 $1-p$此时表达式:
$L = \frac{1}{N}\sum_i L_i = \frac{1}{N}\sum_i -[y_i \cdot log(p_i) + (1-y_i)\cdot log(1-p_i)]$
而用于多分类,其中$y_i$是one_hot标签,$p_i$是softmax层的输出结果,交叉熵损失$L$定义为:
$L=\frac{1}{N}\sum_i - \sum_{c=1}^M y_{ic} *log(p_{ic}) $
$M$- 类别的数量$y_{ic}$- 指示变量(0或1),如果该类别和样本i的类别相同就是1,否则是0$p_{ic}$- 对于观测样本i属于类别 c 的预测概率
例子:
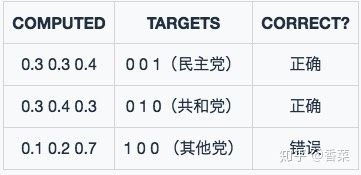
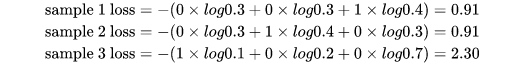
对所有样本的loss求平均:
$L=\frac{0.35+0.35+1.2}{3} = 0.63$
在pytorch中, 用nn.CrossEntropyLoss 前面不需要加 Softmax 层.
Negative Log Liklihood(NLL) Loss
NLLLoss 全称 Negative Log Likelihood Loss,就是求对数概率并取负.
$nll\_loss = -log(pred)$
模型输出的概率分布在 0-1 之间,log 函数的 0-1 区间正好全是负数,所以要加上一个负号,让 loss 值为正数. 显而易见,概率越接近 1,loss 值越小.
NLLLoss的另一种表达:
$nll\_loss = -pred[class]$
这里的 class 就是指第几个标签,它不是 one hot 表示形式. 这里少了一个 log 函数,实际上 pred 是使用 log_softmax 函数计算之后的结果.
Q: Negative Log Liklihood, log 不见了, 这不就是名存实亡了???
A: 这可能是因为 pytorch 想要简化操作,才这么设置的. 简而言之,pytorch 框架中,nll loss 的公式是 -pred. crossentropy 的公式是 logsoftmax + nll loss, 即 nll(log_softmax(output)). 也就是说,如果神经网络的最后一层输出是 logsoftmax,那么就使用 nll loss. 如果最后一层只是输出,偷懒不想写 logsoftmax,那么就使用 crossentropy loss.
- CrossEntropyLoss = LogSoftmax + NLLLoss
- CrossEntropyLoss 中已经附带了 log_softmax 操作,可以直接将输出向量输入 CrossEntropyLoss (即用nn.CrossEntropyLoss 前面不需要加 Softmax 层)
- 如果使用 NLLLoss,那么在使用 NLLLoss 之前,还需要经过一层 LogSoftmax, 然后就等价于交叉熵损失
注: log_softmax applies logarithm after softmax
Code:
import torch
import torch.nn.functional as F
#output是神经网络最后的输出张量,b_y是标签(1hot)
loss1 = torch.nn.CrossEntropyLoss(output,b_y)
loss2 =F.nll_loss(F.log_softmax(output,1),b_y)
#loss1与loss2等效Ref:
- https://blog.csdn.net/hao5335156/article/details/80607732
- https://blog.csdn.net/zhangxb35/article/details/72464152?utm_source=itdadao&utm_medium=referral
- http://www.ituring.com.cn/book/tupubarticle/16827
- pytorch常用的loss: https://blog.csdn.net/zhangxb35/article/details/72464152
- https://yan624.github.io/project/%E5%A4%9A%E9%A2%86%E5%9F%9Fseq2lf.html
Some tricks
optimizer.zero_grad()
Q: 在 pytorch 中,为什么要在每个循环之初调用这个方法?
A: 调用backward()函数之前都要将梯度清零,因为如果梯度不清零,pytorch中会将上次计算的梯度和本次计算的梯度累加. 这样逻辑的好处是,当硬件限制不能使用更大的bachsize时,使用多次计算较小的bachsize的梯度平均值来代替,更方便; 坏处当然是每次都要清零梯度.
optimizer.zero_grad()
output = net(input)
loss = loss_f(output, target) # prediction和y之间进行比对(熵或者其他loss function), 产生最初的梯度
loss.backward() # 计算梯度 (反向传播到整个网络的所有链路和节点)
optimizer.step() # 更新参数 (用所有的梯度更新parameter的值)pytorch的一个特点是每一步都是独立功能的操作,因此也就有需要梯度清零的说法. 当你GPU显存较少时,你又想要调大batch-size,此时你就可以利用PyTorch的这个性质进行梯度的累加来进行backward. 试想本来你想运行 batch_size=1024,但是由于电脑太差,只能运行 batch_size=256 的批次数据. 那么只需要每循环两次调用一次 zero_grad() 即可, 达到梯度累加(gradient accumulation)的效果.
举例: 传统的训练函数,一个batch是这么训练的
for i,(images,target) in enumerate(train_loader):
# 1. input output
images = images.cuda(non_blocking=True)
target = torch.from_numpy(np.array(target)).float().cuda(non_blocking=True)
outputs = model(images)
loss = criterion(outputs,target)
# 2. backward
optimizer.zero_grad() # reset gradient
loss.backward()
optimizer.step()- 获取loss:输入图像和标签,通过infer计算得到预测值,计算损失函数;
- optimizer.zero_grad() 清空过往梯度;
- loss.backward() 反向传播,计算当前梯度;
- optimizer.step() 根据梯度更新网络参数
简单的说就是进来一个batch的数据,计算一次梯度,更新一次网络
使用梯度累加是这么写的:
for i,(images,target) in enumerate(train_loader):
# 1. input output
images = images.cuda(non_blocking=True)
target = torch.from_numpy(np.array(target)).float().cuda(non_blocking=True)
outputs = model(images)
loss = criterion(outputs,target)
# 2.1 loss regularization
loss = loss/accumulation_steps
# 2.2 back propagation
loss.backward()
# 3. update parameters of net
if((i+1)%accumulation_steps)==0:
# optimizer the net
optimizer.step() # update parameters of net
optimizer.zero_grad() # reset gradient- 获取loss:输入图像和标签,通过infer计算得到预测值,计算损失函数;
- loss.backward() 反向传播,计算当前梯度;
- 多次循环步骤1-2,不清空梯度,使梯度累加在已有梯度上;
- 梯度累加了一定次数后,先optimizer.step() 根据累计的梯度更新网络参数,然后optimizer.zero_grad() 清空过往梯度,为下一波梯度累加做准备;
总结来说:梯度累加就是,每次获取1个batch的数据,计算1次梯度,梯度不清空,不断累加,累加一定次数后,根据累加的梯度更新网络参数,然后清空梯度,进行下一次循环.
一定条件下,batchsize越大训练效果越好,梯度累加则实现了batchsize的变相扩大,如果accumulation_steps为8,则batchsize ‘变相’ 扩大了8倍,是解决显存受限的一个不错的trick,使用时需要注意,学习率也要适当放大.
clip gradient
此论文提出了 clip gradient(以下称 clipping)解决梯度爆炸. 首先看下图:
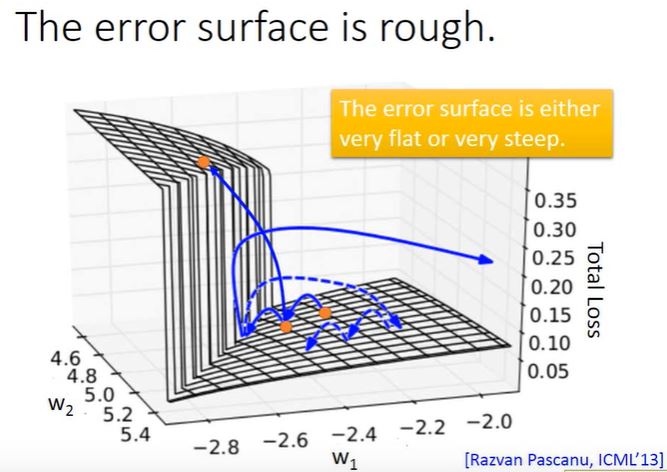 如果只看图, 会发现有一个像峭壁一样的东西,它就是罪魁祸首. 当一个小球往前移动时,有时候正好迈过峭壁,小球得以正常移动; 但是当小球碰到峭壁时,小球就会被反弹回去,导致 loss 发生剧烈变化.
如果只看图, 会发现有一个像峭壁一样的东西,它就是罪魁祸首. 当一个小球往前移动时,有时候正好迈过峭壁,小球得以正常移动; 但是当小球碰到峭壁时,小球就会被反弹回去,导致 loss 发生剧烈变化.
从数学角度来看,那个峭壁就是梯度. 根据参数更新公式 $w -= \alpha * \Delta w$ 代表 w 的梯度,所以 w 的更新方向其实与梯度直接相关. 当 w 不幸到达某个值时,遇到梯度极大的情况,那么不管梯度是正还是负,都会将 w 更新到一个相对很大的值,从而 loss 值也会跟着改变. 注:这里其实也与 learning rate 有关,因为原本的梯度都很小,所以初始设置的 lr 都很大. 突然梯度增大,而 lr 没有适应,一个大的梯度乘上一个大的 lr,那就更大了.
- 解决办法是:当 gradient 大于某个 threshold 时,就不让它大于 threshold(threshold 应该是具体情况具体分析)
Q:那么是什么导致了出现梯度猛增的现象呢?
A: 由于 RNN 是序列模型,它需要处理一连串的序列. 前一个的输出是后一个输入 类似于蝴蝶效应,一个很小的值,经过多个函数也能被放的很大. 在正向传播时, 由于BN和激活函数每个神经元的输出都永远在 [-1, 1] 中间, 并不会造成梯度爆炸/消散, 真正原因是是反向传播时做的链式求导,它导致了梯度的连乘.
解决办法:LSTM,clipping 等.
- 注意:LSTM 只解决了 gradient vanishing 的问题,没有解决 gradient explode。
- 同理 clipping 也只能解决 gradient explode 的问题,因为它能将梯度限制在一个点上
- 那么可以结合 LSTM 和 clipping,从而同时解决梯度爆炸/消失
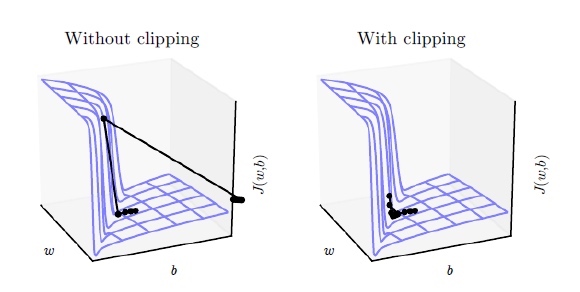
梯度裁剪(gradient clipping) . 这个技巧通常是为了防止梯度爆炸(exploding gradient), 它把参数限制在一个范围之内, 从而可以避免梯度的梯度过大或者出现NaN等问题. 注意:虽然它的名字叫梯度裁剪, 但实际它是对模型的参数进行裁剪, 它把整个参数看成一个向量, 如果这个向量的模大于max_norm, 那么就把这个向量除以一个值使得模等于max_norm, 因此也等价于把这个向量投影到半径为max_norm的球上. 它的效果如下图所示
pytorch code:
clip = 1
torch.nn.utils.clip_grad_norm_(encoder.parameters(), clip)learning rate decay
学习率对整个函数模型的优化起着至关重要的作用
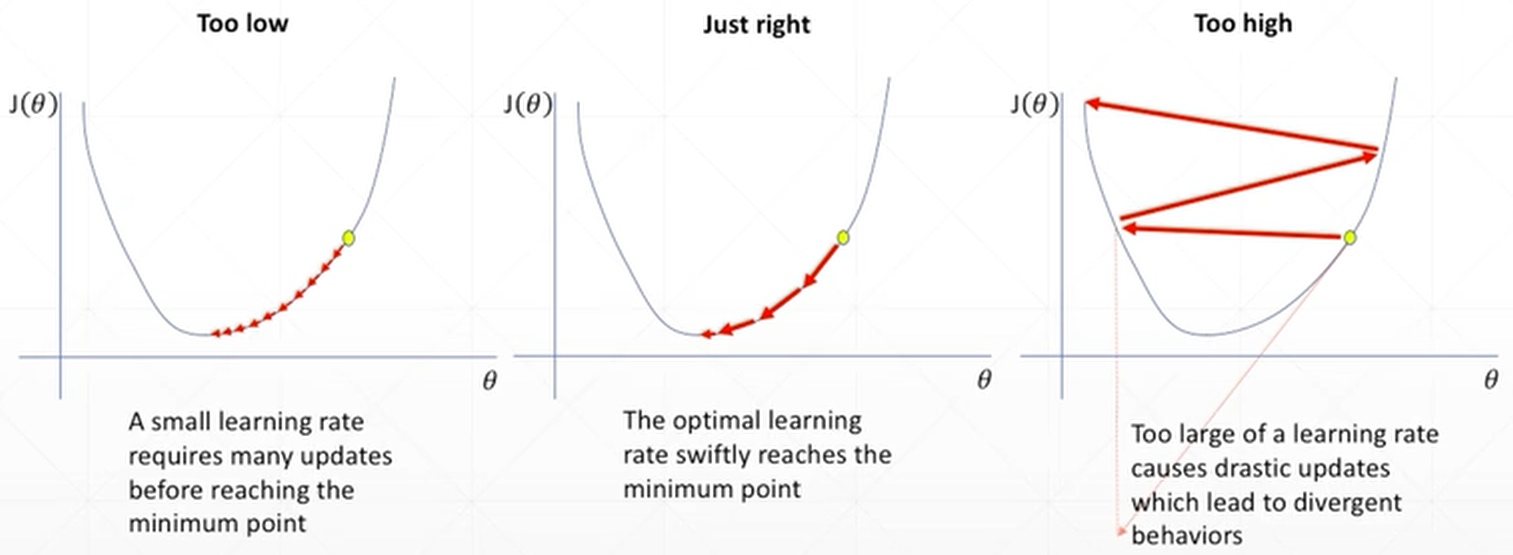 最左边的图由于learning rate设置小了,可能需要大量时间才能找到全局最小值;中间的图表示learning rate设置的刚刚好,则很快就能找到全局最小值;最右边的图表示learning rate设置过大,可能造成loss忽大忽小,无法找到全局最小值.
最左边的图由于learning rate设置小了,可能需要大量时间才能找到全局最小值;中间的图表示learning rate设置的刚刚好,则很快就能找到全局最小值;最右边的图表示learning rate设置过大,可能造成loss忽大忽小,无法找到全局最小值.
由此可以看出,选择合适的learning rate是很讲究技巧的. 如下图所示,设置一个可以自动衰减的learning rate可能会在一定程度上加快优化
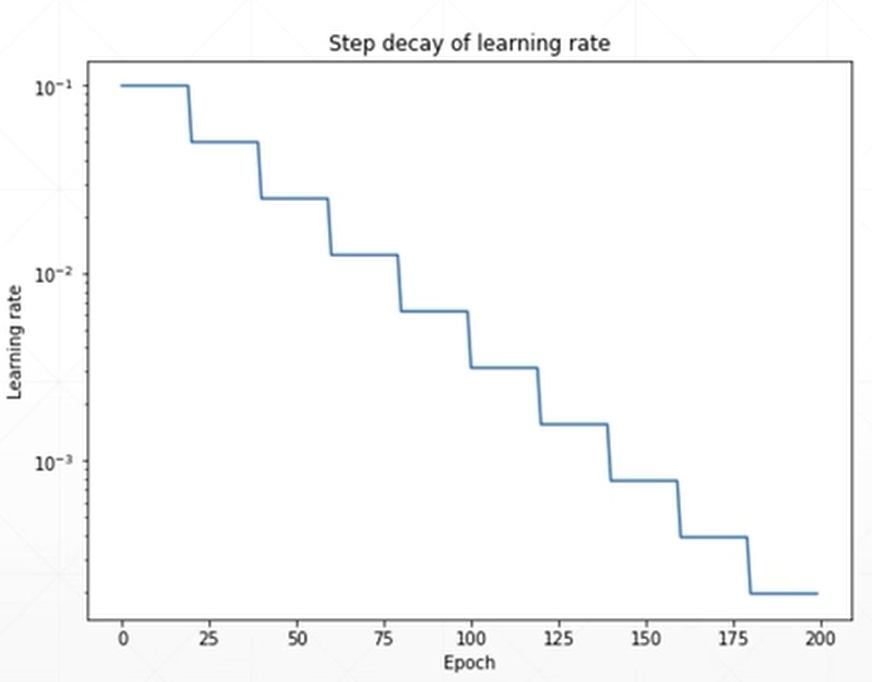
在pytorch中有一个函数可以帮助实现learning rate decay
class torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=10, verbose=False, threshold=0.0001, threshold_mode='rel', cooldown=0, min_lr=0, eps=1e-8)例子:
# patience=10代表的是耐心值为10,
# 当loss出现10次不变化时,即开始调用learning rate decay功能
optimizer = torch.optim.SGD(model.parameters(),
args.lr,
momentum=args.momentum,
weight_decay=args.weight_decay)
scheduler = ReduceLROnPlateau(optimizer, 'min')
for epoch in xrange(args.start_epoch, args.epochs):
train(train_loder, model, criterion, optimizer, epoch)
result_avg, loss_val = validate(val_loder, model, criterion, epoch)
scheduler.step(loss_val) # 设置监听的是lossDropout
在机器学习的模型中,如果模型的参数太多,而训练样本又太少,训练出来的模型很容易产生过拟合的现象。在训练神经网络的时候经常会遇到过拟合的问题,过拟合具体表现在:模型在训练数据上损失函数较小,预测准确率较高;但是在测试数据上损失函数比较大,预测准确率较低.
Dropout可以比较有效的缓解过拟合的发生,在一定程度上达到正则化的效果.
在每个训练批次中, 让一半的隐藏层节点值为0, 可以明显地减少过拟合现象. 这种方式可以减少隐藏层节点之间的相互作用(相互作用是指某些隐藏层节点依赖其他隐藏层节点才能发挥作用, 因为特征(该单元的输入)可能被随机清除(dropout), 所以难以产生依赖)
Dropout说的简单一点就是:在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征, 如下图所示
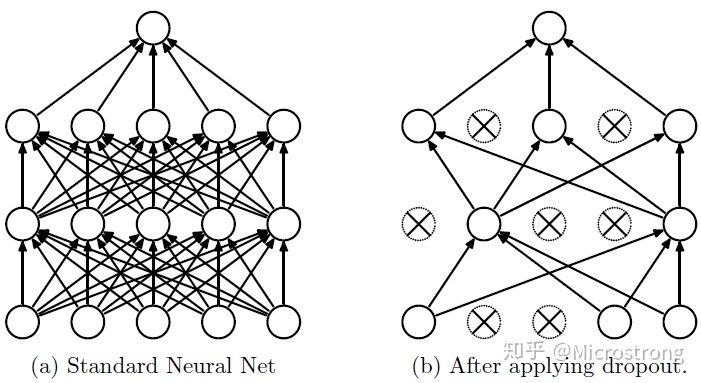
流程:
- 首先随机(临时)删掉网络中一半的隐藏神经元,输入输出神经元保持不变(下图中虚线为部分临时被删除的神经元)
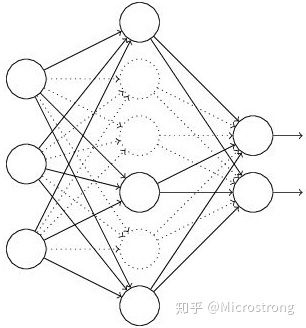
- 然后把输入通过修改后的网络前向传播, 然后把得到的损失结果通过修改的网络反向传播. 一小批训练样本执行完这个过程后,在没有被删除的神经元上按照随机梯度下降法更新对应的参数(w,b)
- 然后继续重复这一过程:
- 恢复被删掉的神经元(此时被删除的神经元保持原样,而没有被删除的神经元已经有所更新)
- 从隐藏层神经元中随机选择一个一半大小的子集临时删除掉(备份被删除神经元的参数)
- 对一小批训练样本,先前向传播然后反向传播损失并根据随机梯度下降法更新参数(w,b) (没有被删除的那一部分参数得到更新,删除的神经元参数保持被删除前的结果)
不断重复这一过程
为什么Dropout可以解决过拟合?
- 取平均的作用: 标准的模型(即没有dropout), 用相同的训练数据去训练5个不同的神经网络,一般会得到5个不同的结果,此时可以采用 “5个结果取均值”或者“多数取胜的投票策略”去决定最终结果. 例如3个网络判断结果为数字9,那么很有可能真正的结果就是数字9, 其它两个网络给出了错误结果. 这种“综合起来取平均”的策略通常可以有效防止过拟合问题. 因为不同的网络可能产生不同的过拟合,取平均则有可能让一些“相反的”拟合互相抵消. dropout掉不同的隐藏神经元就类似在训练不同的网络,随机删掉一半隐藏神经元导致网络结构已经不同,整个dropout过程就相当于对很多个不同的神经网络取平均. 而不同的网络产生不同的过拟合,一些互为“反向”的拟合相互抵消就可以达到整体上减少过拟合
- 减少神经元之间复杂的共适应关系: 因为dropout程序导致两个神经元不一定每次都在一个dropout网络中出现. 这样权值的更新不再依赖于有固定关系的隐含节点的共同作用,阻止了某些特征仅仅在其它特定特征下才有效果的情况. 迫使网络去学习更加鲁棒的特征, 这些特征在其它的神经元的随机子集中也存在. 换句话说假如神经网络是在做出某种预测,它不应该对一些特定的线索片段太过敏感,即使丢失特定的线索,它也应该可以从众多其它线索中学习一些共同的特征. 从这个角度看dropout就有点像L1,L2正则,减少权重使得网络对丢失特定神经元连接的鲁棒性提高
- Dropout类似于性别在生物进化中的角色: 物种为了生存往往会倾向于适应这种环境,环境突变则会导致物种难以做出及时反应,性别的出现可以繁衍出适应新环境的变种,有效的阻止过拟合,即避免环境改变时物种可能面临的灭绝
当前Dropout被大量利用于全连接网络, 一般设置为 0.5. 在 Pytorch 中代表神经网络中某一层的神经元的输出有 0.5 的概率为 0.
处理OOV
- unk技巧
- 在训练word2vec之前,预留一个
符号,把所有stopwords或者低频词都替换成unk,之后使用的时候,也要保留一份词表,对于不在word2vec词表内的词先替换为unk
- 在训练word2vec之前,预留一个
- BPE技巧
- BPE(byte pair encoder), 字节对编码, 也可以叫做digram coding双字母组合编码.
- BPE首先把一个完整的句子分割为单个的字符,频率最高的相连字符对合并以后加入到词表中,直到达到目标词表大小.
- BPE分割的优势是它可以较好的平衡词表大小和需要用于句子编码的token数量
- BPE的缺点在于,它不能提供多种分割的概率
- 例子: 在英语中不同后缀的词非常的多,就会使得词表变的很大,训练速度变慢,训练的效果也不是太好. “loved”,“loving”,“loves”这三个单词. BPE算法通过训练,能够把上面的3个单词拆分成”lov”,“ed”,“ing”,“es”几部分,这样可以把词的本身的意思和时态分开,有效的减少了词表的数量.
- BERT的tokenizer就是使用这种方式
- ….
- Few-Shot Representation Learning for Out-Of-Vocabulary Words
Batch Norm
Intro
BN将输入控制在一个较好的范围内, 在送入激活函数之前, 进行一个normalize的操作(normalize线性函数 而不是 激活函数). 更重要的是为了防止”梯度弥散”.

在每次mini-batch gradient descent时, 在mini-batch 上对每个隐藏层应用正向prop, 用Batch归一化, 使得结果(输出信号各个维度)的均值为0, 方差为1, 再由γ,β缩放.
而最后的”scale and shift”(γ,β缩放)操作则是为了让因训练所需而”刻意”加入的BN能够有可能还原最初的输入(即当$\gamma = \sqrt{\sigma^2 + \epsilon}$ 和 $\beta = \mu$的时候, $\tilde{x} = x$),从而保证整个network的capacity. (不想让隐藏单元总是含有平均值0和方差1)
- capacity的解释:实际上BN可以看作是在原模型上加入的”新操作”, 这个新操作很大可能会改变某层原来的输入. 当然也可能不改变, 不改变的时候就是”原来输入”. 如此一来,既可以改变同时也可以保持原输入, 那么模型的容纳能力(capacity)就提升了
- γ,β are learnable parameter, 所以可以使用梯度下降算法来更新它们
- 使用了γ,β之后,最后得到的分布是往N(β,γ)上靠的,而不是往N(0,1)上靠的
BN的BP (optional)
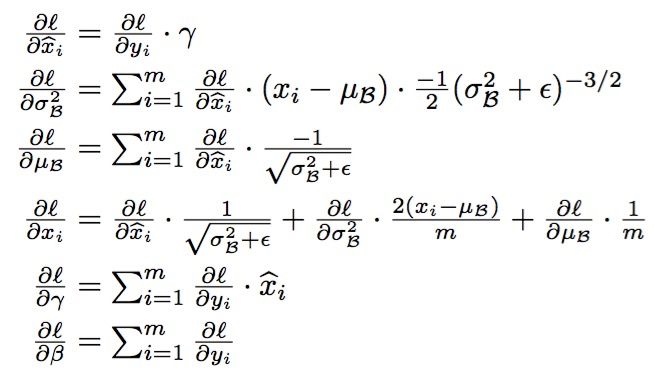
使用BN时机, 例如, 在神经网络训练时遇到收敛速度很慢, 或梯度爆炸等无法训练的状况时可以尝试BN来解决. 另外,在一般使用情况下也可以加入BN来加快训练速度,提高模型精度.
各种Normalization方式
(1)标准的Batch Normalization
一个Batch的图像数据shape为[样本数N, 通道数C, 高度H, 宽度W],将其最后两个维度flatten,得到的是[N, C, H*W],标准的Batch Normalization就是在通道Channel这个维度上进行移动,对所有样本的所有值求均值和方差,所以有几个通道,得到的就是几个均值和方差.
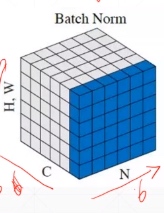
(2)Layer Normalization
Layer Normalization是在实例即样本N的维度上滑动,对每个样本的所有通道的所有值求均值和方差,所以一个Batch有几个样本实例,得到的就是几个均值和方差。
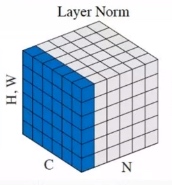
(3)Instance Normalization
Instance Normalization是在样本N和通道C两个维度上滑动,对Batch中的N个样本里的每个样本n,和C个通道里的每个样本c,其组合[n, c]求对应的所有值的均值和方差,所以得到的是N⋅C个均值和方差。
(4)Group Normalization
…
ref:
- https://charon.me/posts/dl6/#%E5%BD%92%E4%B8%80%E5%8C%96%E7%BD%91%E7%BB%9C%E7%9A%84%E6%BF%80%E6%B4%BB%E5%87%BD%E6%95%B0-normalizing-activations-in-a-network
- https://www.zhihu.com/question/38102762
- https://zhuanlan.zhihu.com/p/69431151
Visualization
以前一直用 matplotlib 来画图, 现在用了 tensorboardX 之后, 觉得以前写matplotlib code的时间都浪费了.
Tensorboard 是 TensorFlow 的一个附加工具,可以记录训练过程的数字、图像等内容,以方便研究人员观察神经网络训练过程。可是对于 PyTorch 等其他神经网络训练框架并没有功能像 Tensorboard 一样全面的类似工具,一些已有的工具功能有限或使用起来比较困难 (tensorboard_logger, visdom等). TensorboardX 这个工具使得 TensorFlow 外的其他神经网络框架也可以使用到 Tensorboard 的便捷功能
安装:
pip install tensorboardX使用, type:
tensorboard --logdir=<your_log_dir> to start the server, where your_log_dir is the parameter of the object constructor.
使用TensorboardX
首先,需要创建一个 SummaryWriter 的示例:
from tensorboardX import SummaryWriter
# Creates writer1 object.
# The log will be saved in 'runs/exp'
writer1 = SummaryWriter('runs/exp')
# Creates writer2 object with auto generated file name
# The log directory will be something like 'runs/Aug20-17-20-33'
writer2 = SummaryWriter()
# Creates writer3 object with auto generated file name, the comment will be appended to the filename.
# The log directory will be something like 'runs/Aug20-17-20-33-resnet'
writer3 = SummaryWriter(comment='resnet')以上展示了三种初始化 SummaryWriter 的方法:
- 提供一个路径,将使用该路径来保存日志
- 无参数,默认将使用 runs/日期时间 路径来保存日志
- 提供一个 comment 参数,将使用 runs/日期时间-comment 路径来保存日志
一般来讲,对于每次实验新建一个路径不同的 SummaryWriter,也叫一个 run,如 runs/exp1、runs/exp2
接下来,就可以调用 SummaryWriter 实例的各种 add_something 方法向日志中写入不同类型的数据了. 想要在浏览器中查看可视化这些数据,只要在命令行中开启 tensorboard 即可:
tensorboard --logdir=<your_log_dir>其中的 <your_log_dir> 既可以是单个 run 的路径,如上面 writer1 生成的 runs/exp;也可以是多个 run 的父目录,如 runs/ 下面可能会有很多的子文件夹,每个文件夹都代表了一次实验,令 --logdir=runs/ 就可以在 tensorboard 可视化界面中方便地横向比较 runs/ 下不同次实验所得数据的差异。
使用各种 add 方法记录数据
下面详细介绍 SummaryWriter 实例的各种数据记录方法,并提供相应的示例供参考.
数字 (scalar)
使用 add_scalar 方法来记录数字常量。
add_scalar(tag, scalar_value, global_step=None, walltime=None)参数
- tag (string): 数据名称,不同名称的数据使用不同曲线展示
- scalar_value (float): 数字常量值
- global_step (int, optional): 训练的 step
- walltime (float, optional): 记录发生的时间,默认为 time.time()
需要注意,这里的 scalar_value 一定是 float 类型,如果是 PyTorch scalar tensor,则需要调用 .item() 方法获取其数值. 一般会使用 add_scalar 方法来记录训练过程的 loss、accuracy、learning rate 等数值的变化,直观地监控训练过程.
Example
from tensorboardX import SummaryWriter
writer = SummaryWriter('runs/scalar_example')
for i in range(10):
writer.add_scalar('quadratic', i**2, global_step=i)
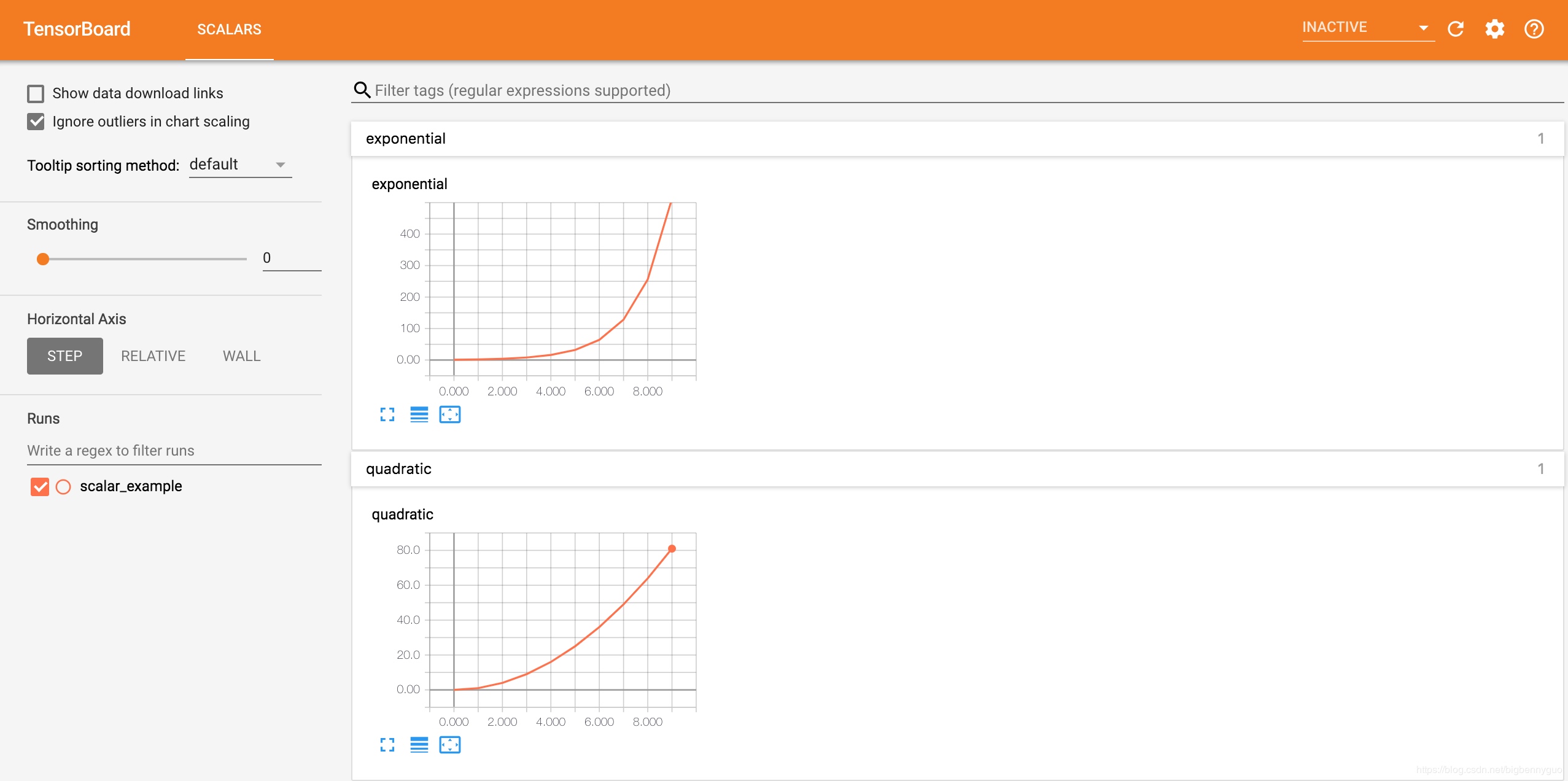
writer.add_scalar('exponential', 2**i, global_step=i)这里,在一个路径为 runs/scalar_example 的 run 中分别写入了二次函数数据 quadratic 和指数函数数据 exponential,在浏览器可视化界面中效果如下:
writer = SummaryWriter('runs/another_scalar_example')
for i in range(10):
writer.add_scalar('quadratic', i**3, global_step=i)
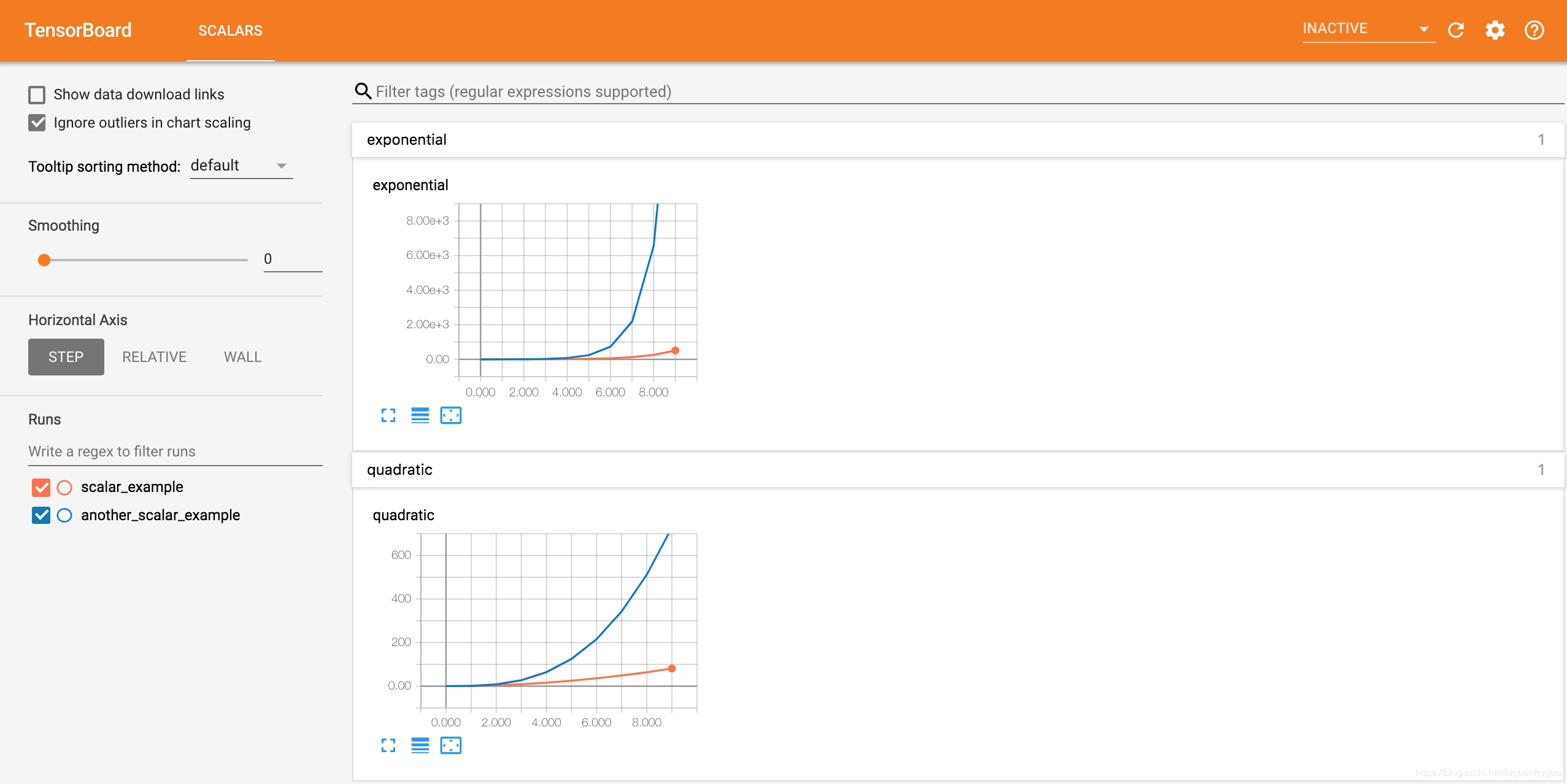
writer.add_scalar('exponential', 3**i, global_step=i)接下来在另一个路径为 runs/another_scalar_example 的 run 中写入名称相同但参数不同的二次函数和指数函数数据,可视化效果如下. 可以发现相同名称的量值被放在了同一张图表中展示,方便进行对比观察. 同时,还可以在屏幕左侧的 runs 栏选择要查看哪些 run 的数据.
图片 (image)
使用 add_image 方法来记录单个图像数据。注意,该方法需要 pillow 库的支持.
add_image(tag, img_tensor, global_step=None, walltime=None, dataformats='CHW')参数
- tag (string): 数据名称
- img_tensor (torch.Tensor / numpy.array): 图像数据
- global_step (int, optional): 训练的 step
- walltime (float, optional): 记录发生的时间,默认为 time.time()
- dataformats (string, optional): 图像数据的格式,默认为 ‘CHW’,即 Channel x Height x Width,还可以是 ‘CHW’、’HWC’ 或 ‘HW’ 等
一般会使用 add_image 来实时观察生成式模型的生成效果,或者可视化分割、目标检测的结果,帮助调试模型.
Example
from tensorboardX import SummaryWriter
import cv2 as cv
writer = SummaryWriter('runs/image_example')
for i in range(1, 6):
writer.add_image('countdown',
cv.cvtColor(cv.imread('{}.jpg'.format(i)), cv.COLOR_BGR2RGB),
global_step=i,
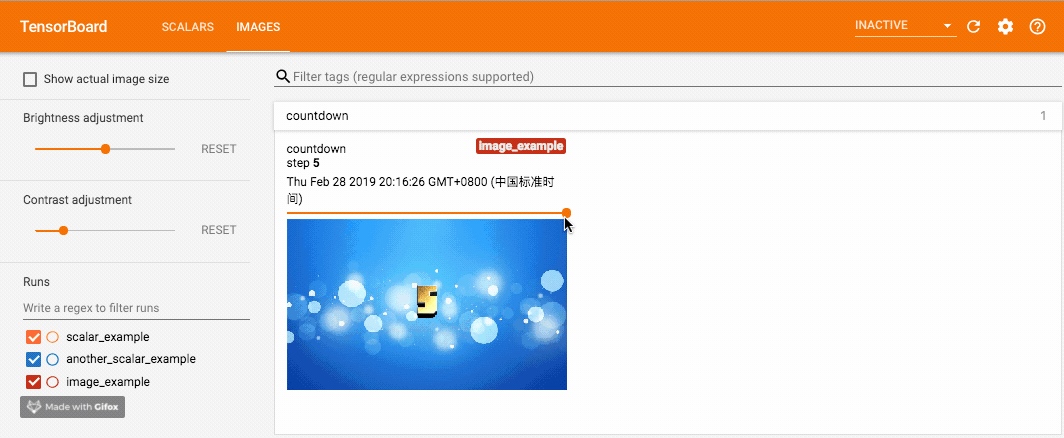
dataformats='HWC')这里分别使用 add_image 写入记录, 使用 opencv 读入图片, opencv 读入的图片通道排列是 BGR,因此需要先转成 RGB 以保证颜色正确,并且 dataformats 设为 ‘HWC’,而非默认的 ‘CHW’。调用这个方法一定要保证数据的格式正确,像 PyTorch Tensor 的格式就是默认的 ‘CHW’. 效果如下,可以拖动滑动条来查看不同 global_step 下的图片:
add_image 方法只能一次插入一张图片。如果要一次性插入多张图片,有两种方法:
- 使用 torchvision 中的 make_grid 方法 [官方文档] 将多张图片拼合成一张图片后,再调用 add_image 方法。
- 使用 SummaryWriter 的 add_images 方法 [官方文档],参数和 add_image 类似,在此不再另行介绍。
直方图 (histogram)
使用 add_histogram 方法来记录一组数据的直方图。
add_histogram(tag, values, global_step=None, bins='tensorflow', walltime=None, max_bins=None)参数
- tag (string): 数据名称
- values (torch.Tensor, numpy.array, or string/blobname): 用来构建直方图的数据
- global_step (int, optional): 训练的 step
- bins (string, optional): 取值有 ‘tensorflow’、‘auto’、‘fd’ 等, 该参数决定了分桶的方式,详见这里。
- walltime (float, optional): 记录发生的时间,默认为 time.time()
- max_bins (int, optional): 最大分桶数
可以通过观察数据、训练参数、特征的直方图,了解到它们大致的分布情况,辅助神经网络的训练过程.
Example
from tensorboardX import SummaryWriter
import numpy as np
writer = SummaryWriter('runs/embedding_example')
writer.add_histogram('normal_centered', np.random.normal(0, 1, 1000), global_step=1)
writer.add_histogram('normal_centered', np.random.normal(0, 2, 1000), global_step=50)
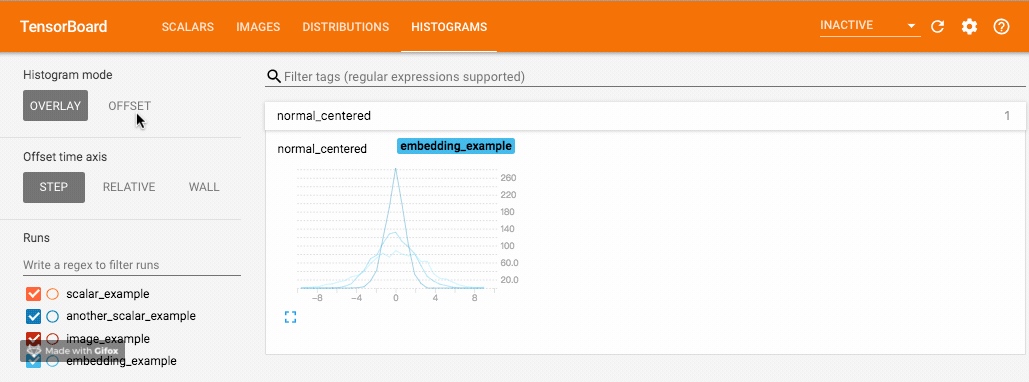
writer.add_histogram('normal_centered', np.random.normal(0, 3, 1000), global_step=100)使用 numpy 从不同方差的正态分布中进行采样. 打开浏览器可视化界面后,会发现多出了”DISTRIBUTIONS”和”HISTOGRAMS”两栏,它们都是用来观察数据分布的. 其中在”HISTOGRAMS”中,同一数据不同 step 时候的直方图可以上下错位排布 (OFFSET) 也可重叠排布 (OVERLAY). 上下两图分别为”DISTRIBUTIONS”界面和”HISTOGRAMS”界面.
运行图 (graph)
使用 add_graph 方法来可视化一个神经网络。
add_graph(model, input_to_model=None, verbose=False, **kwargs)参数
- model (torch.nn.Module): 待可视化的网络模型
- input_to_model (torch.Tensor or list of torch.Tensor, optional): 待输入神经网络的变量或一组变量
该方法可以可视化神经网络模型,TensorboardX 给出了一个官方样例尝试. 样例运行效果如下:
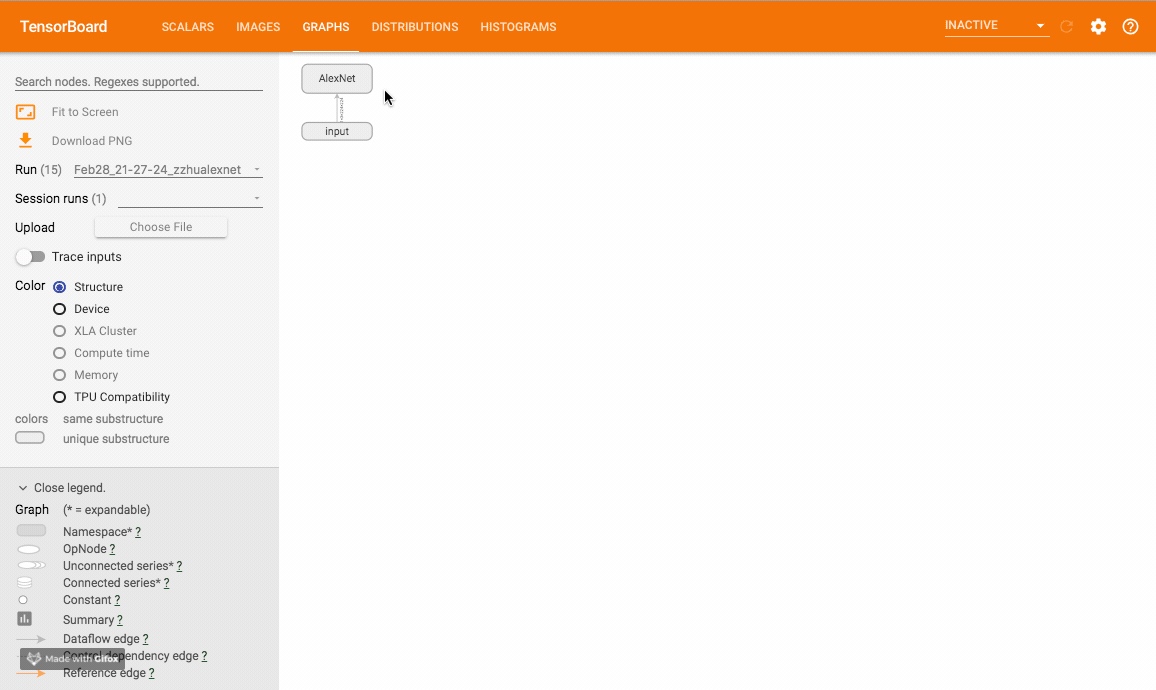
嵌入向量 (embedding)
使用 add_embedding 方法可以在二维或三维空间可视化 embedding 向量.
add_embedding(mat, metadata=None, label_img=None, global_step=None, tag='default', metadata_header=None)参数
- mat (torch.Tensor or numpy.array): 一个矩阵,每行代表特征空间的一个数据点
- metadata (list or torch.Tensor or numpy.array, optional): 一个一维列表,mat 中每行数据的 label,大小应和 mat 行数相同
- label_img (torch.Tensor, optional): 一个形如 NxCxHxW 的张量,对应 mat 每一行数据显示出的图像,N 应和 mat 行数相同
- global_step (int, optional): 训练的 step
- tag (string, optional): 数据名称,不同名称的数据将分别展示
add_embedding 是一个很实用的方法,不仅可以将高维特征使用PCA、t-SNE等方法降维至二维平面或三维空间显示,还可观察每一个数据点在降维前的特征空间的K近邻情况。下面例子中取 MNIST 训练集中的 100 个数据,将图像展成一维向量直接作为 embedding,使用 TensorboardX 可视化出来。
from tensorboardX import SummaryWriter
import torchvision
writer = SummaryWriter('runs/embedding_example')
mnist = torchvision.datasets.MNIST('mnist', download=True)
writer.add_embedding(
mnist.train_data.reshape((-1, 28 * 28))[:100,:],
metadata=mnist.train_labels[:100],
label_img = mnist.train_data[:100,:,:].reshape((-1, 1, 28, 28)).float() / 255,
global_step=0
)采用 PCA 降维后在三维空间可视化效果如下:
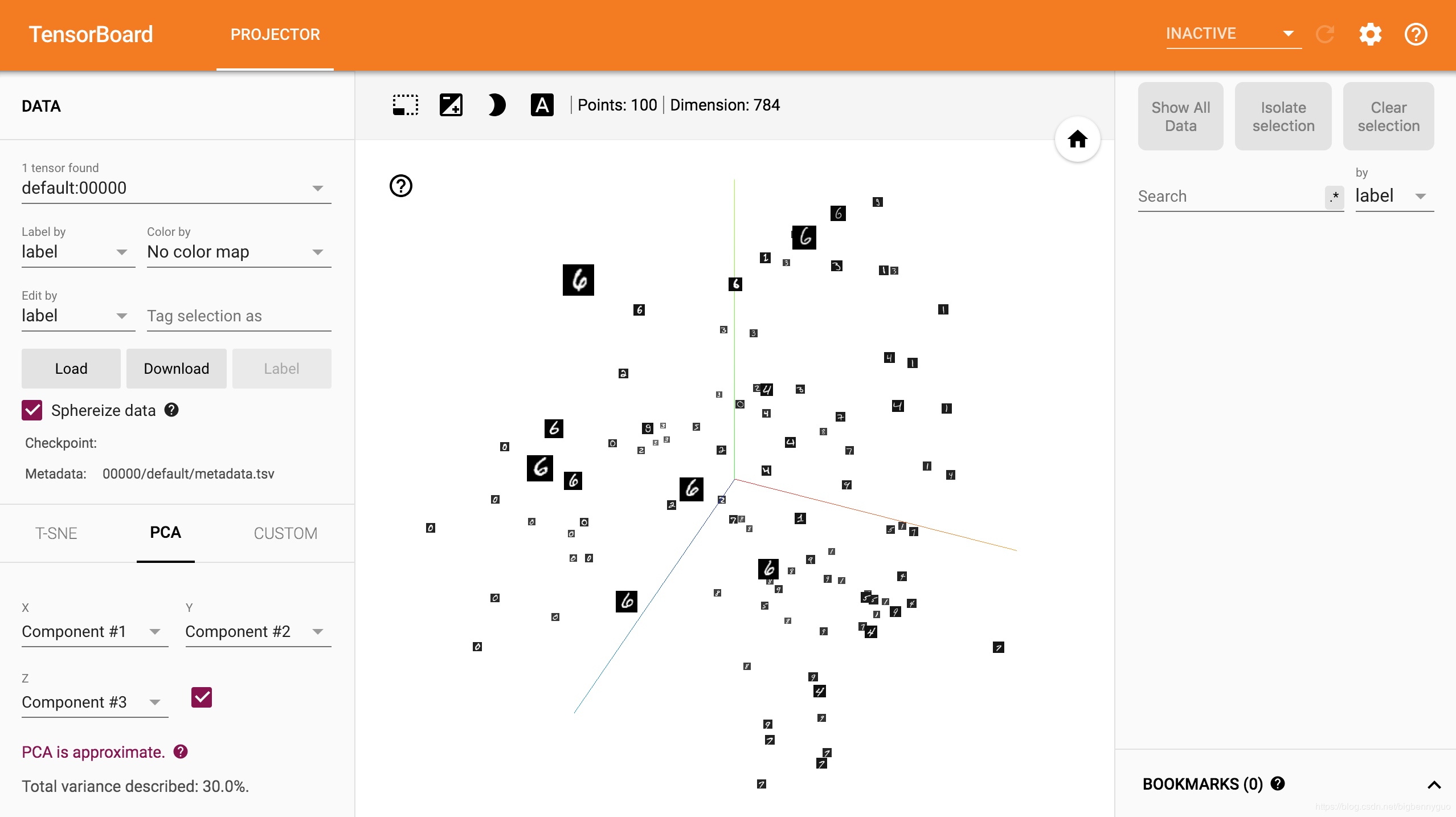
可以发现,虽然还没有做任何特征提取的工作,但 MNIST 的数据已经呈现出聚类的效果,相同数字之间距离更近一些(有没有想到 KNN 分类器). 还可以点击左下方的 T-SNE,用 t-SNE 的方法进行可视化.
add_embedding 方法需要注意的几点:
mat是二维 MxN,metadata是一维 N,label_img是四维 N x C x H x Wlabel_img记得归一化为 0-1 之间的 float 值
Ref: