Retriever
BM25
计算关键/搜索句和内容的相关性 - via 权重度量方法:TF-IDF和BM25算法, 通常用来作搜索相关性平分.
相似度, 就是关键/搜索句中每个词与文本计算后的TF-IDF/BM25分数相加
BM25(BM是Best Matching的意思), 是基于TF-IDF并做了改进的算法
公式解析
BM25算法通常用来做搜索相关性评分的, 通常用来计算query和文本集合D中每篇文本之间的相关性.
- 用Q表示query (Q一般是一个句子)
- 对Q进行语素解析 (一般是分词), 得到$q_1, q_2,……, q_t$这样一个词序列
- 给定文本$d \in D$,现在以计算Q和d之间的分数(相关性), 其表达式如下:
$Score(Q, d) = \sum_{i = 1}^t w_i * R(q_i, d)$
- 上面式子中$w_i$表示$q_i$的权重
- $R(q_i, d)$为$q_i$和$d$的相关性,
- $Score(Q, d)$就是每个语素$q_i$和$d$的相关性的加权和
$w_i$的计算方法有很多,一般是用IDF来表示的,但这里的IDF计算和上面的有所不同,具体的表达式如下:
$w_i = IDF(q_i) = \log \frac {N - n(q_i) + 0.5} {n(q_i) + 0.5}$
- 上面式子中$N$表示文本集合中文本的总数量,
- $n(q_i)$表示包含$q_i$这个词的文本的数量,
- 0.5主要是做平滑处理
$R(q_i, d)$的计算公式如下:
$R(q_i, d) = \frac {f_i * (k_1 + 1)} {f_i + K} * \frac {qf_i * (k_2 + 1)} {qf_i + k_2}$ 其中 $K = k_1 * (1 - b + b * \frac {dl} {avg dl})$
- 上面式子中$f_i$为$q_i$在文本$d$中出现的频率(tf, term-frequency)
- $qf_i$为$q_i$在$Q$中出现的频率,
- $k_1$, $k_2$, $b$都是可调节的参数,
- $dl$, $avgdl$分别为文本$d$的长度和文本集$D$中所有文本的平均长度
一般$qf_i = 1$,取$k_2 = 0$,则可以去除后一项,将上面式子改写成:
$R(q_i, d) = \frac {f_i * (k_1 + 1)} {f_i + K}$ 通常设置$k_1 = 2$, $b = 0.75$。参数b的作用主要是调节文本长度对相关性的影响.
BM25中的TF
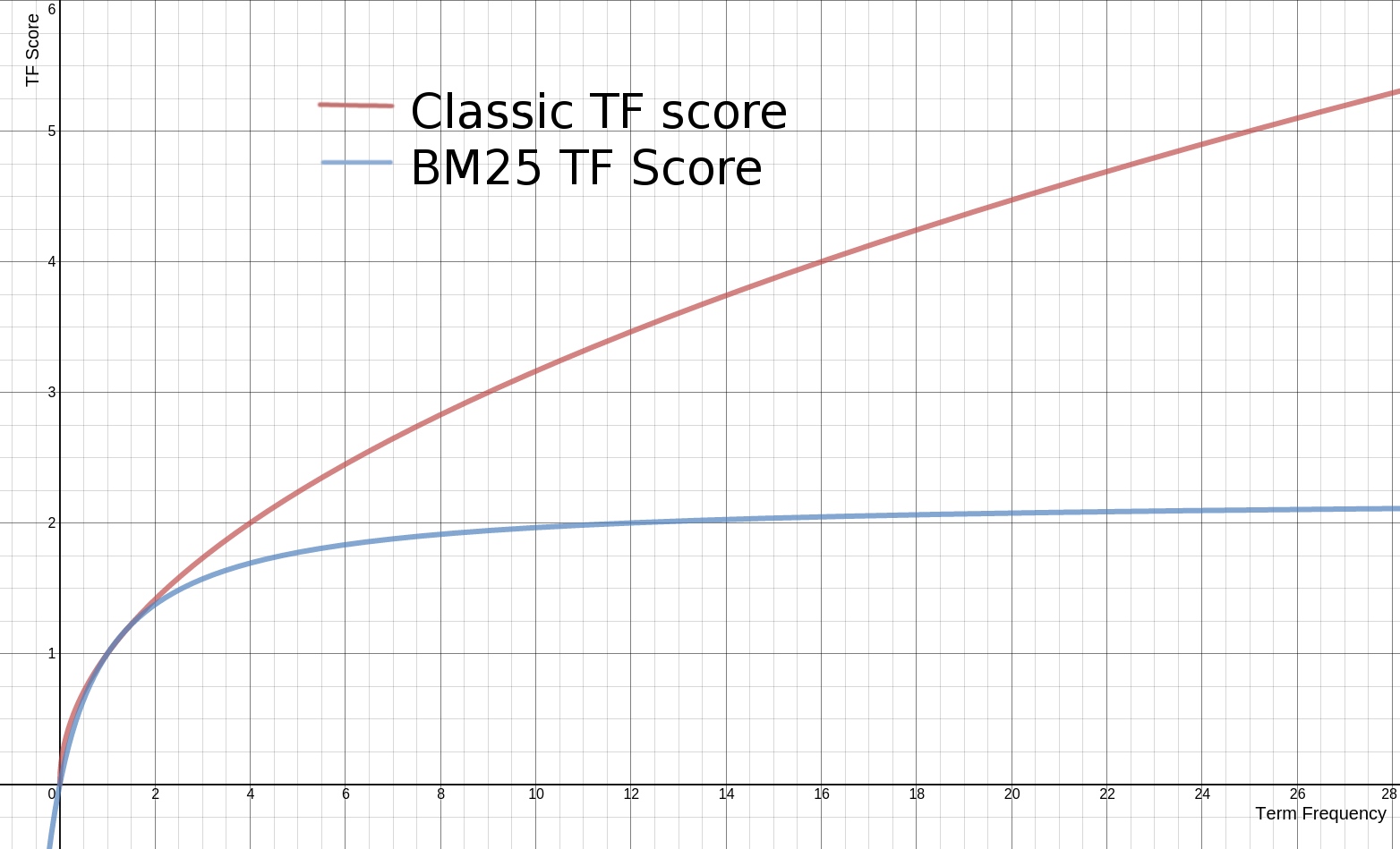
传统的TF值理论上是可以无限大的。而BM25与之不同,它在TF计算方法中增加了一个常量$k_1$,用来限制TF值的增长极限。下面是两者的公式:
传统 TF Score = tf
BM25的 TF Score = ((k1 + 1) * tf) / (k1 + tf)下面是两种计算方法中,词频对TF Score影响的走势图。从图中可以看到,当tf增加时,TF Score跟着增加,但是BM25的TF Score会被限制在0~k1+1之间。它可以无限逼近k1+1,但永远无法触达它。这在业务上可以理解为某一个因素的影响强度不能是无限的,而是有个最大值,这也符合我们对文本相关性逻辑的理解。
BM25如何对待文档长度
BM25还引入了平均文档长度的概念,单个文档长度对相关性的影响力与它和平均长度的比值有关系。BM25的TF公式里,除了k1外,引入另外两个参数:K和b。K是文档长度与平均长度的比值。如果文档长度是平均长度的2倍,则K=2。b是一个常数,它的作用是规定K对评分的影响有多大。加了K和b的公式变为:
TF Score = ((k1 + 1) * tf) / (k1 * (1.0 - b + b * K) + tf)下面是不同L的条件下,词频对TFScore影响的走势图: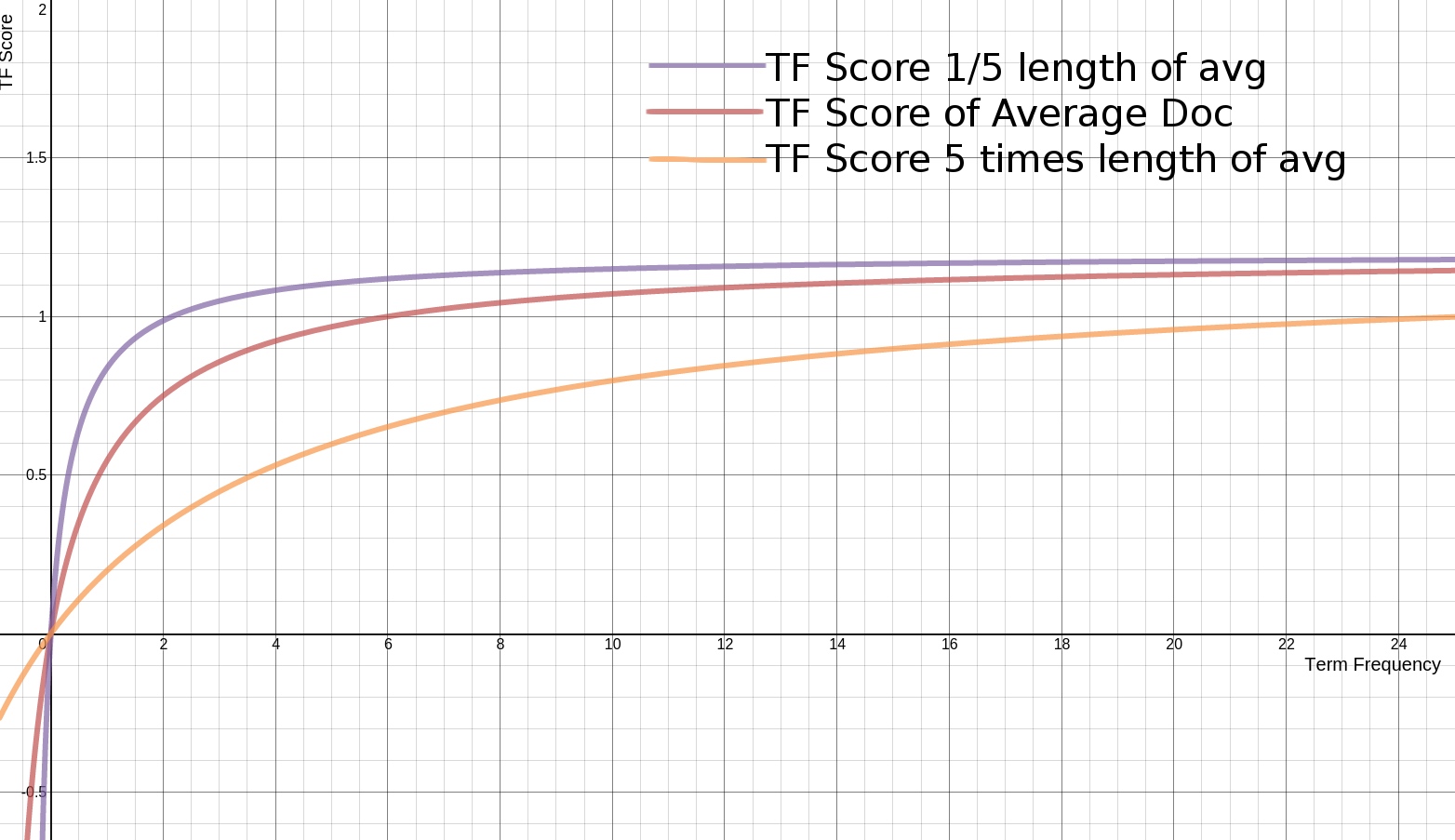
从图上可以看到,文档越短,它逼近上限的速度越快,反之则越慢。这是可以理解的,对于只有几个词的内容,比如文章“标题”,只需要匹配很少的几个词,就可以确定相关性。而对于大篇幅的内容,比如一本书的内容,需要匹配很多词才能知道它的重点是讲什么。
上文说到,参数b的作用是设定K对评分的影响有多大。如果把b设置为0,则K完全失去对评分的影响力。b的值越大,K对总评分的影响力越大。此时,相似度最终的完整公式为:simlarity = IDF * ((k1 + 1) * tf) / (k1 * (1.0 - b + b * (|d|/avgDl)) + tf)Code
import math
import jieba
# 测试文本
text = '''
自然语言处理是计算机科学领域与人工智能领域中的一个重要方向。
它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。
自然语言处理是一门融语言学、计算机科学、数学于一体的科学。
因此,这一领域的研究将涉及自然语言,即人们日常使用的语言,
所以它与语言学的研究有着密切的联系,但又有重要的区别。
自然语言处理并不是一般地研究自然语言,
而在于研制能有效地实现自然语言通信的计算机系统,
特别是其中的软件系统。因而它是计算机科学的一部分。
'''
# 分段再分词后的结果
doc = [{'中': 1, '计算机科学': 1, '领域': 2, '一个': 1, '人工智能': 1, '方向': 1, '自然语言': 1},
{'之间': 1, '方法': 1, '理论': 1, '通信': 1, '计算机': 1, '人': 1, '研究': 1, '自然语言': 1},
{'融': 1, '一门': 1, '一体': 1, '数学': 1, '科学': 1, '计算机科学': 1, '语言学': 1, '自然语言': 1},
{},
{'领域': 1, '这一': 1, '涉及': 1, '研究': 1, '自然语言': 1},
{'日常': 1, '语言': 1},
{'语言学': 1, '研究': 1},
{'区别': 1},
{'研究': 1, '自然语言': 2},
{'通信': 1, '计算机系统': 1, '研制': 1, '在于': 1, '自然语言': 1},
{'软件系统': 1, '特别': 1},
{'一部分': 1, '计算机科学': 1}]
class BM25(object):
def __init__(self, docs):
self.D = len(docs)
self.avgdl = sum([len(doc)+0.0 for doc in docs]) / self.D
self.docs = docs
self.f = [] # 列表的每一个元素是一个dict,dict存储着一个文档中每个词的出现次数
self.df = {} # 存储每个词及出现了该词的文档数量
self.idf = {} # 存储每个词的idf值
self.k1 = 1.5
self.b = 0.75
self.init()
def init(self):
for doc in self.docs:
tmp = {}
for word in doc:
tmp[word] = tmp.get(word, 0) + 1 # 存储每个文档中每个词的出现次数
self.f.append(tmp)
for k in tmp.keys():
self.df[k] = self.df.get(k, 0) + 1
for k, v in self.df.items():
self.idf[k] = math.log(self.D-v+0.5)-math.log(v+0.5)
def sim(self, doc, index):
score = 0
for word in doc:
if word not in self.f[index]:
continue
d = len(self.docs[index])
score += (self.idf[word]*self.f[index][word]*(self.k1+1)
/ (self.f[index][word]+self.k1*(1-self.b+self.b*d
/ self.avgdl)))
return score
def simall(self, doc):
scores = []
for index in range(self.D):
score = self.sim(doc, index)
scores.append(score)
return scores
if __name__ == '__main__':
# print(doc)
s = BM25(doc)
print(s.f)
print(s.idf)
print(s.simall(['自然语言', '计算机科学', '领域', '人工智能', '领域']))s.f - 列表的每一个元素是一个dict,dict存储着一个文档中每个词的出现次数
[{'中': 1, '计算机科学': 1, '领域': 2, '一个': 1, '人工智能': 1, '方向': 1, '自然语言': 1},
{'之间': 1, '方法': 1, '理论': 1, '通信': 1, '计算机': 1, '人': 1, '研究': 1, '自然语言': 1},
{'融': 1, '一门': 1, '一体': 1, '数学': 1, '科学': 1, '计算机科学': 1, '语言学': 1, '自然语言': 1},
{},
{'领域': 1, '这一': 1, '涉及': 1, '研究': 1, '自然语言': 1},
{'日常': 1, '语言': 1},
{'语言学': 1, '研究': 1},
{'区别': 1},
{'研究': 1, '自然语言': 2},
{'通信': 1, '计算机系统': 1, '研制': 1, '在于': 1, '自然语言': 1},
{'软件系统': 1, '特别': 1},
{'一部分': 1, '计算机科学': 1}]s.df - 存储每个词及出现了该词的文档数量
{'在于': 1, '人工智能': 1, '语言': 1, '领域': 2, '融': 1, '日常': 1, '人': 1, '这一': 1, '软件系统': 1, '特别': 1, '数学': 1, '通信': 2, '区别': 1, '之间': 1, '计算机科学': 3, '科学': 1, '一体': 1, '方向': 1, '中': 1, '理论': 1, '计算机': 1, '涉及': 1, '研制': 1, '一门': 1, '研究': 4, '语言学': 2, '计算机系统': 1, '自然语言': 6, '一部分': 1, '一个': 1, '方法': 1}s.idf - 存储每个词的idf值
{'在于': 2.0368819272610397, '一部分': 2.0368819272610397, '一个': 2.0368819272610397, '语言': 2.0368819272610397, '领域': 1.4350845252893225, '融': 2.0368819272610397, '日常': 2.0368819272610397, '人': 2.0368819272610397, '这一': 2.0368819272610397, '软件系统': 2.0368819272610397, '特别': 2.0368819272610397, '数学': 2.0368819272610397, '通信': 1.4350845252893225, '区别': 2.0368819272610397, '之间': 2.0368819272610397, '一门': 2.0368819272610397, '科学': 2.0368819272610397, '一体': 2.0368819272610397, '方向': 2.0368819272610397, '中': 2.0368819272610397, '理论': 2.0368819272610397, '计算机': 2.0368819272610397, '涉及': 2.0368819272610397, '研制': 2.0368819272610397, '计算机科学': 0.9985288301111273, '研究': 0.6359887667199966, '语言学': 1.4350845252893225, '计算机系统': 2.0368819272610397, '自然语言': 0.0, '人工智能': 2.0368819272610397, '方法': 2.0368819272610397}s.simall([‘自然语言’, ‘计算机科学’, ‘领域’, ‘人工智能’, ‘领域’]) [‘自然语言’, ‘计算机科学’, ‘领域’, ‘人工智能’, ‘领域’]这句关键/搜索句与每一句的相似度
[5.0769919814311475, 0.0, 0.6705449078118518, 0, 2.5244316697250033, 0, 0, 0, 0.0, 0.0, 0, 1.2723636062357853]