NLP3
Information Extraction (IE)
- 抽取实体(entities)
- 人(person),地名(location),时间(time)
- 医疗领域: 蛋白质, 疾病, 药物
- 抽取关系(ontological relations)
- 位于(located in), 工作在(work at), 部分(is part of)
- IS-A (Hypernym Relation)
- Instance-of
应用 - 知识库搭建 - Google Scholar - 产品搜索 - 问答系统 - 粒度: 粗(Similarity) -> 细(Knowledge Graph) - 证券分析 - ….
三元组 (又称RDF store)
- (张三, 毕业于, 北大)
- (张三, 工作在, 北京)
与知识图谱的区别, 它没有存属性图(property graph)
Open Source Knowledge Base
- FreeBase
- WorldNet
- Yago
- Dpedia
- KnowledgeValut (Google)
Named Entity Recognition(NER)
Eng Toolkit
- NLTK NE
- Spacy
- Stanford Parser
CHI Toolkit
- HanNLP
- HIT NLP
- Fudan NLP
缺点: 只提供通用性(不适用与垂直领域, 最好自己构建)
Create NER Recognizer
- 定义实体种类
- E.g. Resume Analize
- 公司名字
- 技能
- 入职时间
- ….
- E.g. Resume Analize
- 准备训练数据
- 训练NER
Evaluate NER Recognizer
- Precision / Recall
- F1-score
Methods for NER
- 利用规则 (E.g.正则)
- 投票模型 (Majority Voting)
- 利用分类模型
- 非时序模型: 逻辑回归, SVM
- 时序模型: HMM, CRF, LSTM-CRF
Feature Encoding
常见特征种类
- 类别型(categorical)
- E.g. 词性 (0,0,..,1,0,0,…) <- one-hot
- 连续型(continnous)
- 直接用高斯分布 N(0,1)
- Discretize
- E.g.身高 1. 150-160 2.160-170 3. 170-180 ….
- 用1,2,3,4,…来取代身高
- Ordinal Feature
- E.g.成绩 A,B,C,D,…
- 直接使用 或 当成 categorical feature
关系抽取 Feature Extraction
- 基于规则的方法
- 基于监督学习方法
- 基于半监督&无监督学习方法
- Bootstrap方法
- Distant-supervision方法
- 无监督学习方法
基于规则的方法
规则集 E.g.
- X(is a)Y
- Y(such as)X
- Y(including)X
- Y(, especially)X
优点:
- 比较准确
- 不需要训练数据
缺点:
- low recall rate
- 成本(人力)
- 规则难设计
基于监督学习方法
- 定义关系类型
- 定义实体类型
- 训练数据准备
- 实体标记好(类型)
- 实体之间的关系
Feature Engineering for Supervised Learning
输入 -特征工程-> 特征向量 -> 模型 -> 分类结果
The professor Colin proposed a model for NER in 1999
当前词: Colin
- Bag-of-word features
- 当前词: Colin
- 前后词: professor, proposed
- 前前,后后词: the, model
- bi-gram: professor Colin, Colin proposed, The professor, proposed model,…
- tri-gram ….
- 词性 features
- 当前词: 名
- 前后词: 名,动
- n-gram …
- 前缀&后缀
- 当前词: Co, in
- 前后词: pr, or, pr, ed
- 当前词的特性
- 词长
- 是否大写开头
- 是否数字
- 是否有有符号
- Stemming
Bootstrap方法
Bootstrap是一种抽样方法
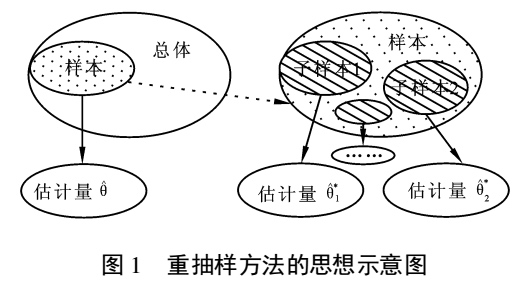 样本之于样本,可以类比样本之于总体
样本之于样本,可以类比样本之于总体
例子:我要统计鱼塘里面的鱼的条数,怎么统计呢?假设鱼塘总共有鱼1000条,我是开了上帝视角的,但是你是不知道里面有多少.
步骤:
- 承包鱼塘,不让别人捞鱼(规定总体分布不变)。
- 自己捞鱼,捞100条,都打上标签(构造样本)
- 把鱼放回鱼塘,休息一晚(使之混入整个鱼群,确保之后抽样随机)
- 开始捞鱼,每次捞100条,数一下,自己昨天标记的鱼有多少条,占比多少(一次重采样取分布)。
重复3,4步骤n次。建立分布。
假设,第一次重新捕鱼100条,发现里面有标记的鱼12条,记下为12%,放回去,再捕鱼100条,发现标记的为9条,记下9%,重复重复好多次之后,假设取置信区间95%,你会发现,每次捕鱼平均在10条左右有标记,所以,我们可以大致推测出鱼塘有1000条左右。其实是一个很简单的类似于一个比例问题。这也是因为提出者Efron给统计学顶级期刊投稿的时候被拒绝的理由–”太简单”。这也就解释了,为什么在小样本的时候,bootstrap效果较好,你这样想,如果我想统计大海里有多少鱼,你标记100000条也没用啊,因为实际数量太过庞大,你取的样本相比于太过渺小,最实际的就是,你下次再捕100000的时候,发现一条都没有标记...

seed tuple -> 生成规则 -> 生成tuple -> 生成规则 -> 生成tuple -> ….(repeat)
- 优点: 自动的算法
- 缺点: Error Accumulation
Bootstrap (snowball)
- 生成规则
- pattern representation (五元组)
- 生成tuple
- 评估规则准确+过滤
- 评估tuple准确+过滤
- repeat….

算法的大体思想如下:
- 根据已经得到元组(第一次迭代则是手工输入的种子元组),从语料库中找到这些种子元组共现的上下文
- 从这些上下文关系中,根据要求提取出这些种子元组共现时的模型
- 根据规则对模型进行筛选,确定出若干可用的模型
- 将这些模型投入到语料库中,与若干元组进行匹配,根据匹配结果,得到一些新的、满足所给的种子元组关系的元组对
- 如果已经得到足够数量的元组对,或者,多次迭代元组数量无显著增长,则停止算法,否则返回第一步
- 参考: https://blog.csdn.net/parasol5/article/details/49050537
 直接用内积表示相似度, 不需要除以模长, 因为L,M,R做了normalization => ||L||=1
直接用内积表示相似度, 不需要除以模长, 因为L,M,R做了normalization => ||L||=1
生成模板

生成tuple & 模板评估
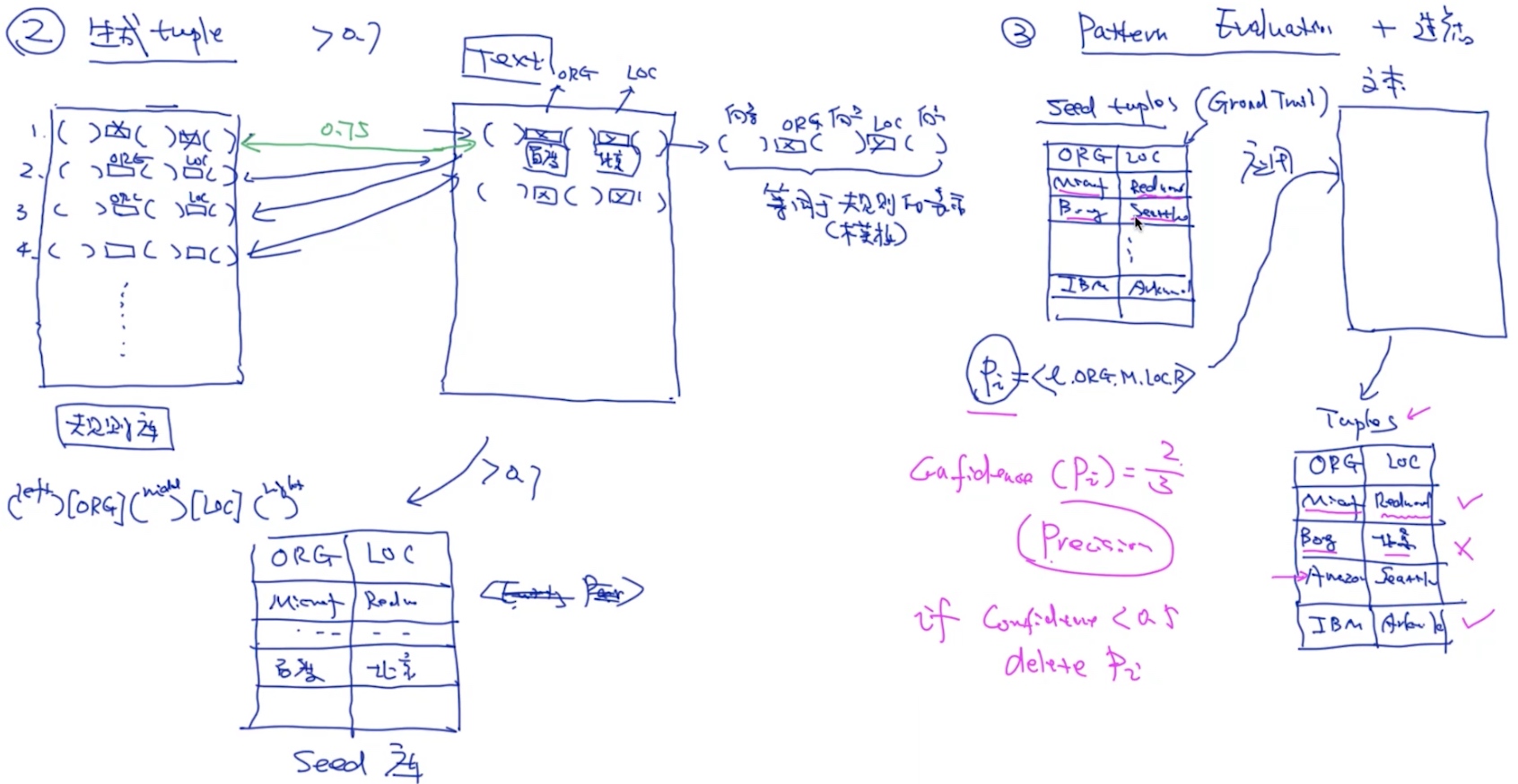
Tuple评估
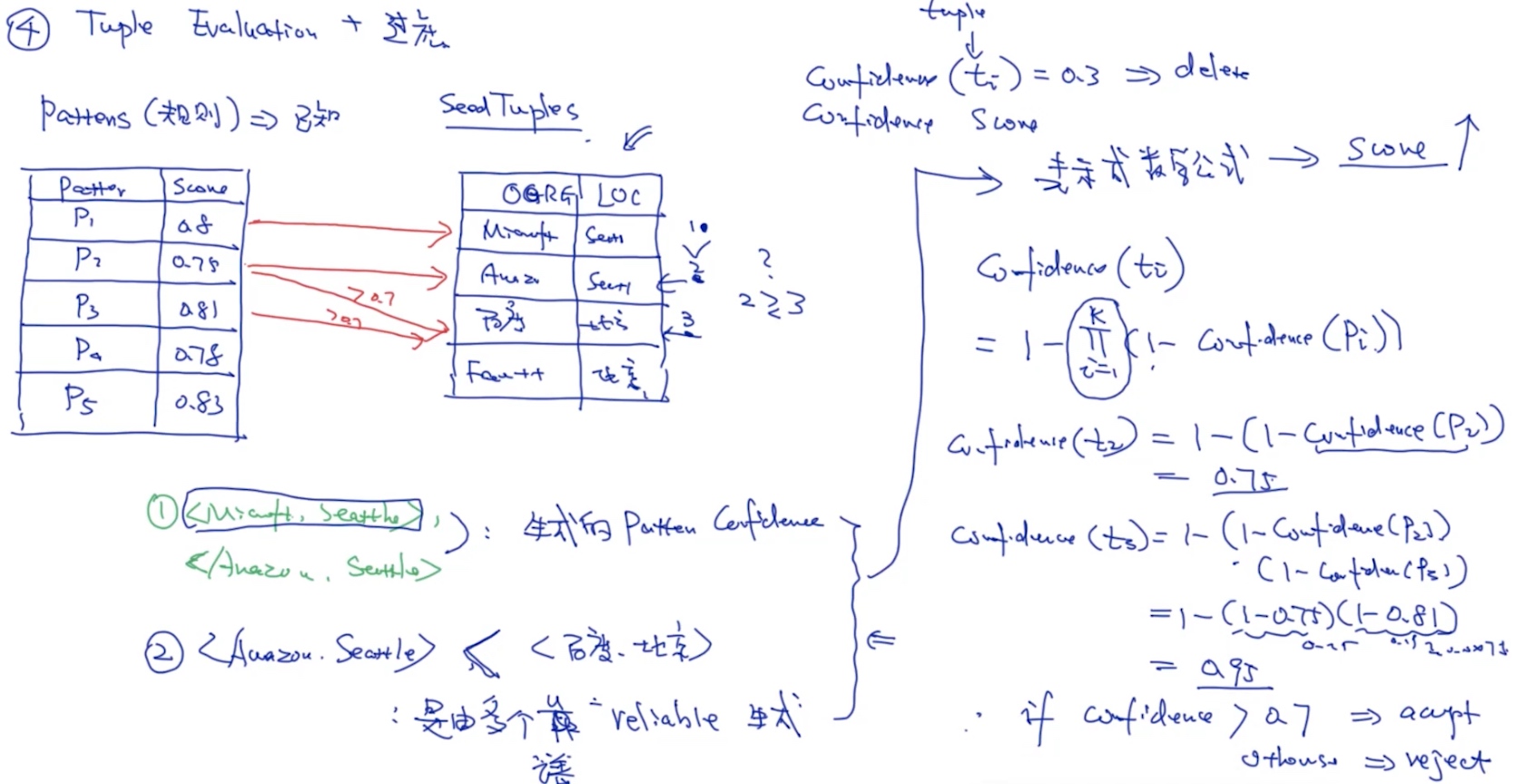
Distant-supervision
unsupervised
实体消歧 (Entity Disambiguiation)
实体消岐的本质在于一个词很可能有多个意思, 也就是在不同的上下文中所表达的含义不太一样. E.g. Apple -> 水果 or 苹果公司
维护一个实体库:
| 实体 | ID | 描述 |
|---|---|---|
| 苹果 | ID | 美国高科技公司… |
| 苹果 | ID | 水果中的一种… |
- 今天苹果发布了新的手机… ==> 取’苹果’两边的字符串转成tf-idf/wrd2vec/…
- 美国高科技公司… ==> 转成tf-idf
- 水果中的一种… ==> 转成tf-idf
- 通过consine similarity 进行比较
实体统一 (Entity Resolution)
多个实体的描述可能描述的是同一个实体 (给定两个实体, 判断是否指向同一个实体(二分类问题))
E.g. 一个地址的填法可能有数十种
算法:
1. Edit Distance => sim(str1, str2)
2. 基于规则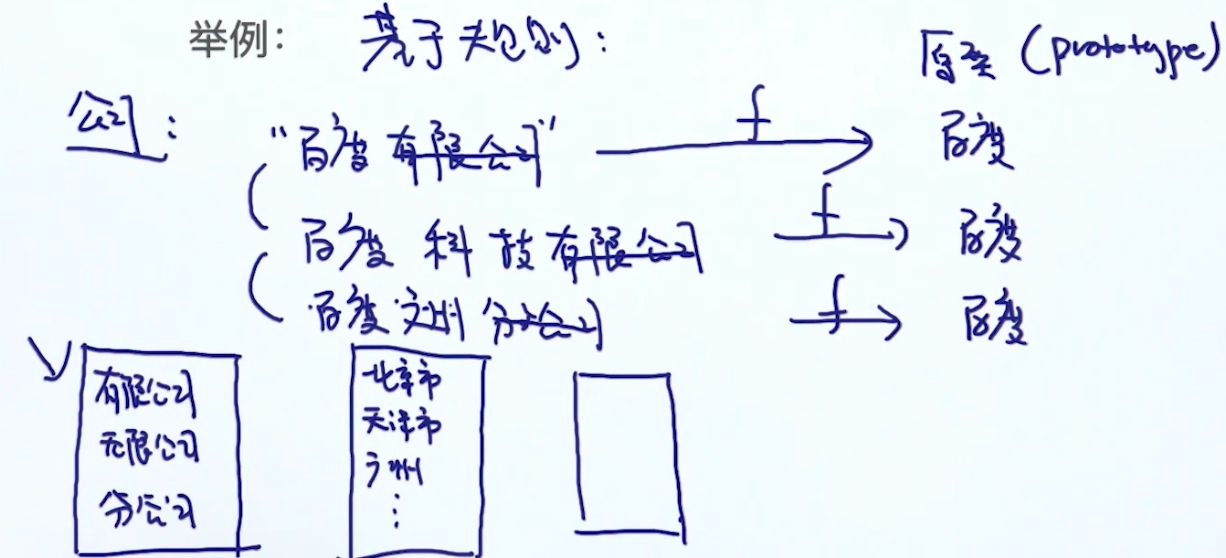 3. supervised
3. supervised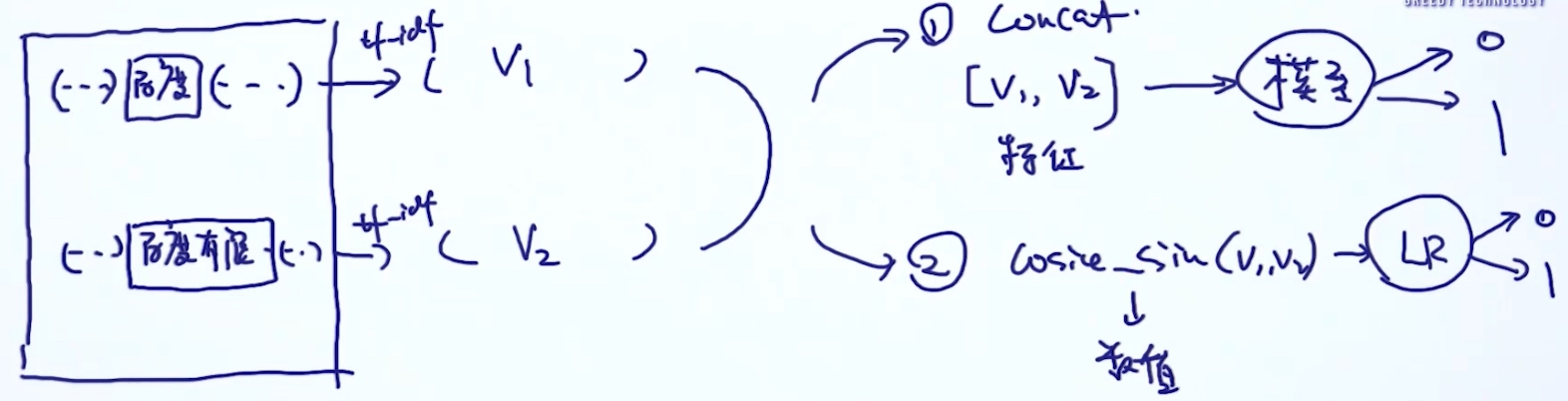 4. 基于图的实体统一, 关系图:
4. 基于图的实体统一, 关系图: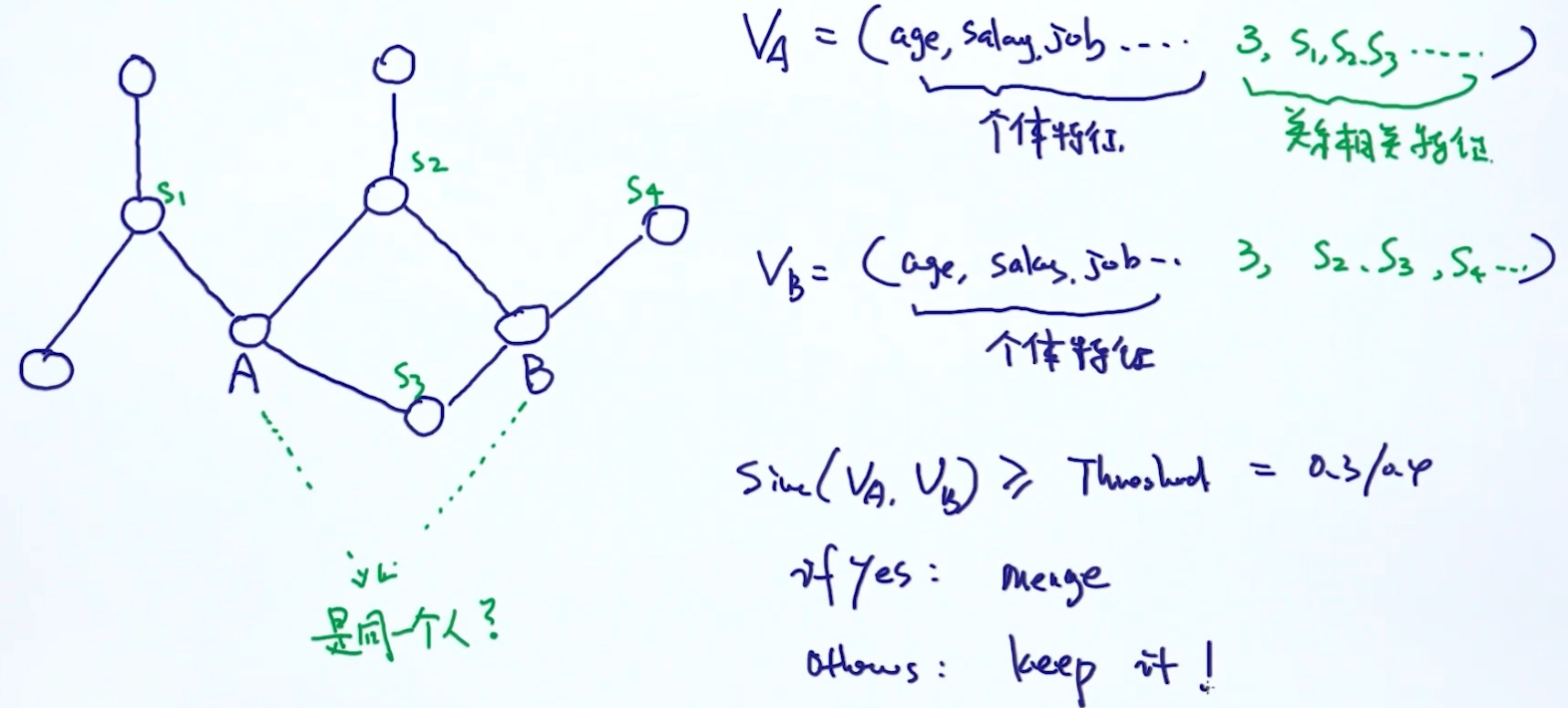 然后通过 个体特征,关系相关特征等, 进行相似度的运算
然后通过 个体特征,关系相关特征等, 进行相似度的运算
指代消解 (Co-reference Resolution)
he,she,it 指的是哪个实体, 本质仍是二分类问题
E.g. Alan didn’t work tdy. Charon checked his status. He is okay
算法:
- 指向最近的实体 (不准确)
- supervised learning
- collect data
- 样本
- (Alan, his) -> 1
- (Charon, his) -> 0
- (Alan, he) -> 1
- (Charon, he) -> 0
- 在词的周围提取关键词, 构造向量
- 放入模型
句法分析 (Parsing)
理解句子的两种方法:
- 句法分析 (主谓宾…)
- 大量阅读后, 凭感觉 <- 语言模型
E.g. Microsoft is located in Redmond
Syntax Tree:
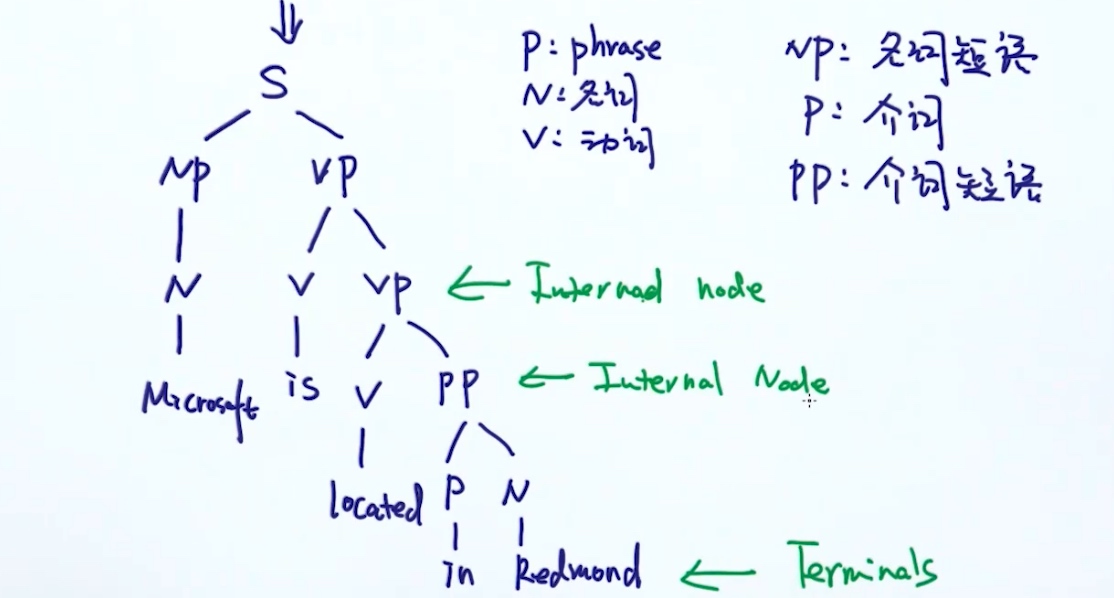
提取与 树/图 的相关特征 (重要性可能不高, 适用于短句子)
- 最短路径
- 各种POS的数量
- …
From CFG to PCFG (probabilistic context free grammars)
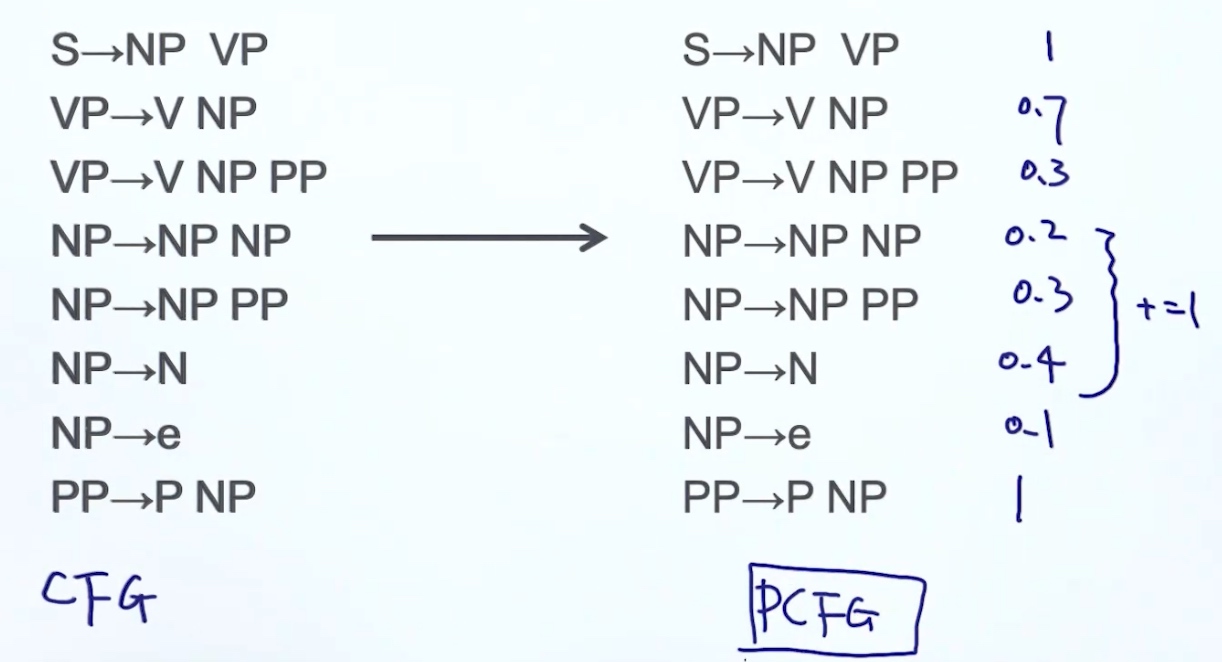
Evaluate Syntax tree: 一个句子可以拆分成多种不同的语法树, 而每个树的每个结点都有相应的概率(通过统计获得, 每个语法出现的概率), 将所有概率相乘, 选择概率最高的语法树
Fine the best syntax tree:
- 枚举所有可能的语法树 (时间复杂度高)
- CKY算法
CKY算法
(基于动态规划的算法) https://blog.csdn.net/Chase1998/article/details/84504191
transform to CNF
- 必须要binarization
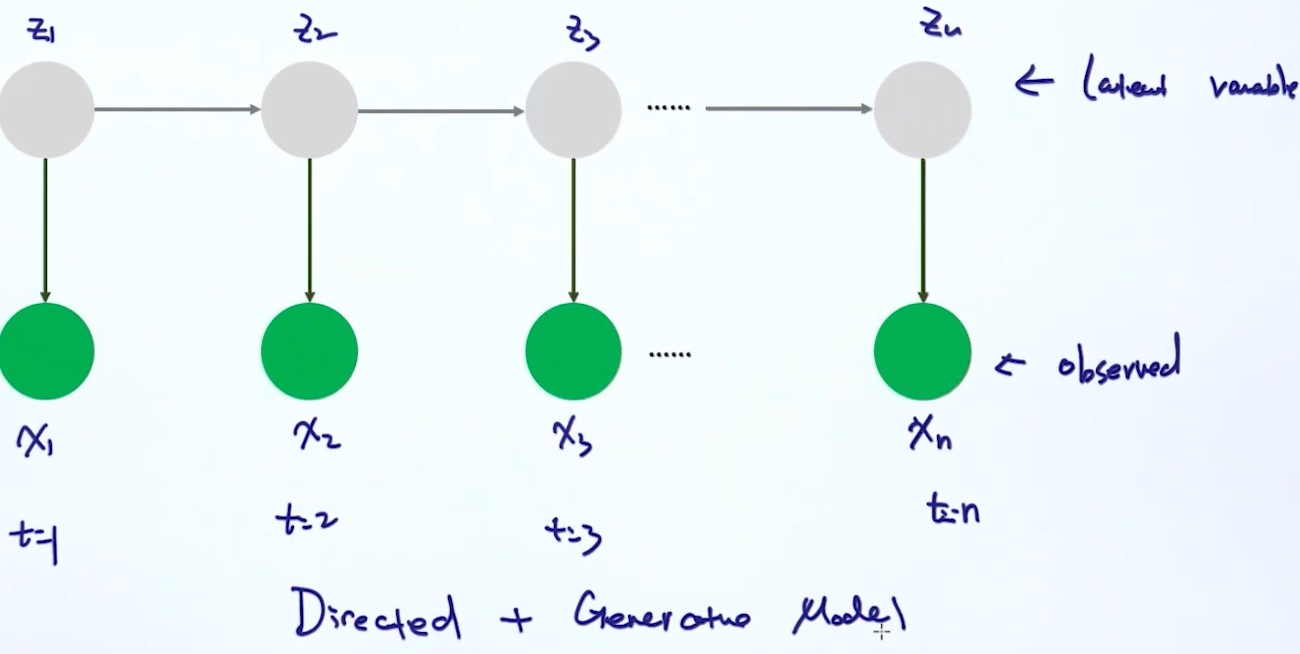
时序模型
- HMM / CRF <= traditional method
- RNN / LSTM <= deep learning
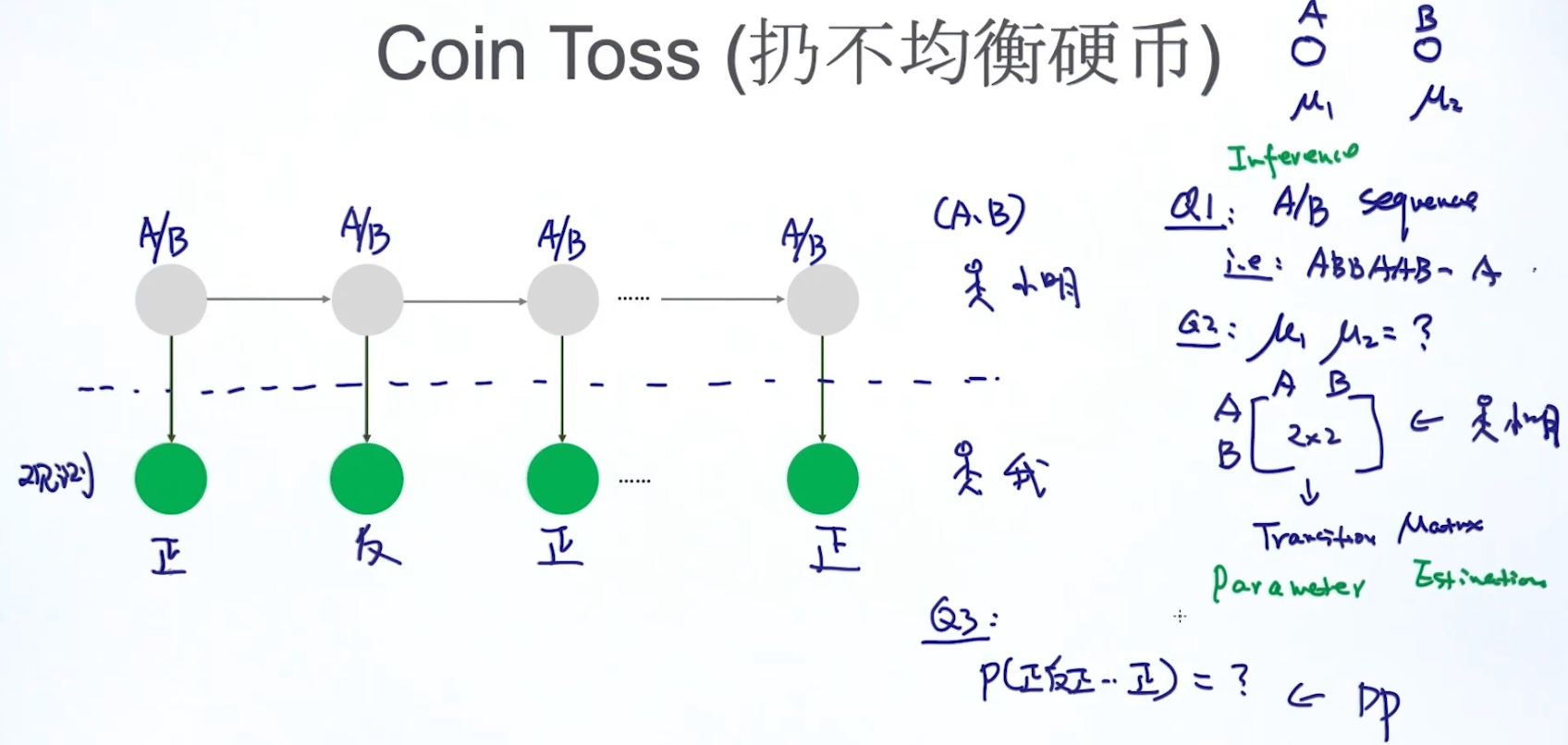
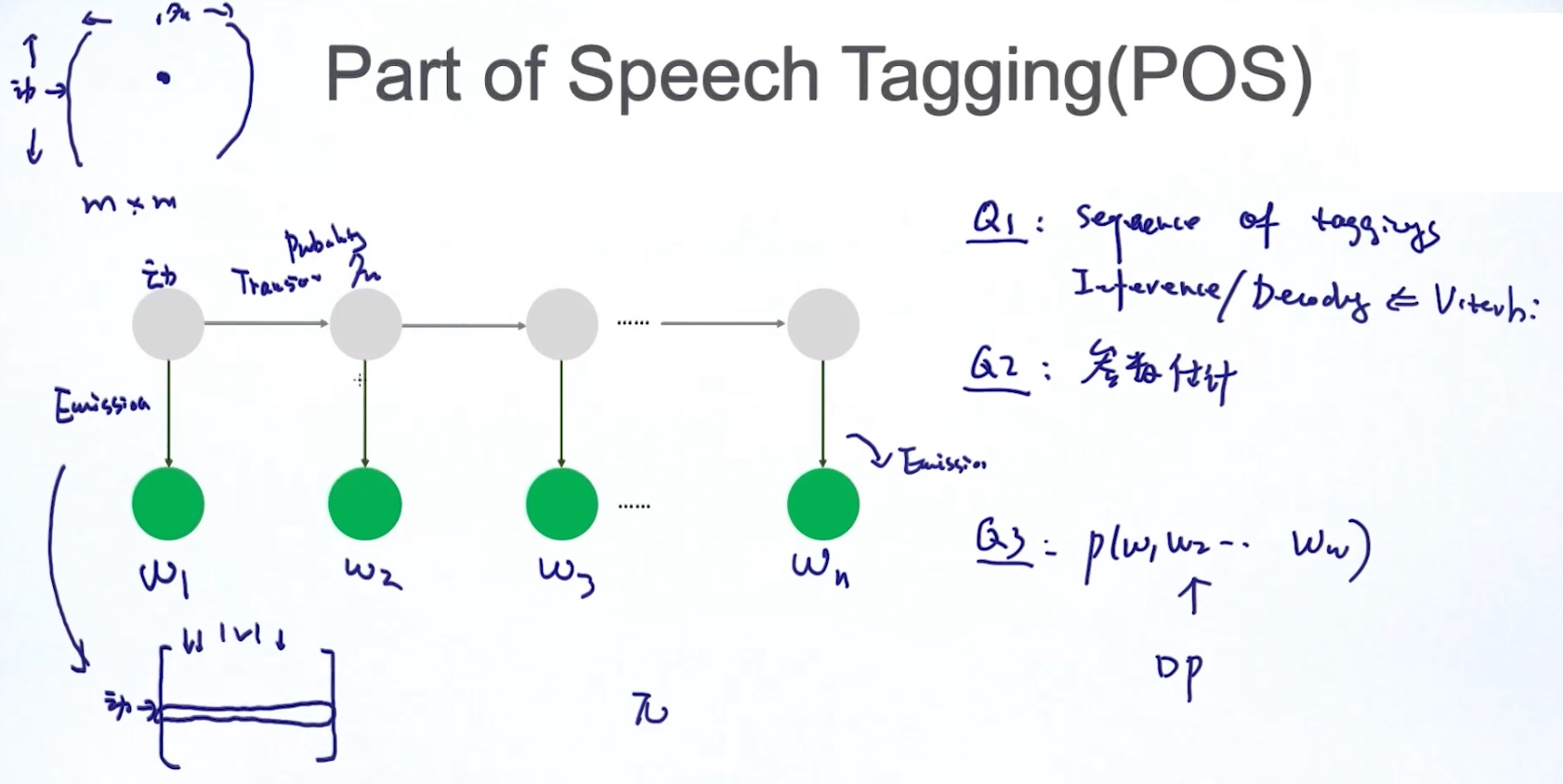
Hidden Markov Model (HMM)
 E.g.
E.g.
Parameters of HMM: $\theta = (A,B,\pi)$
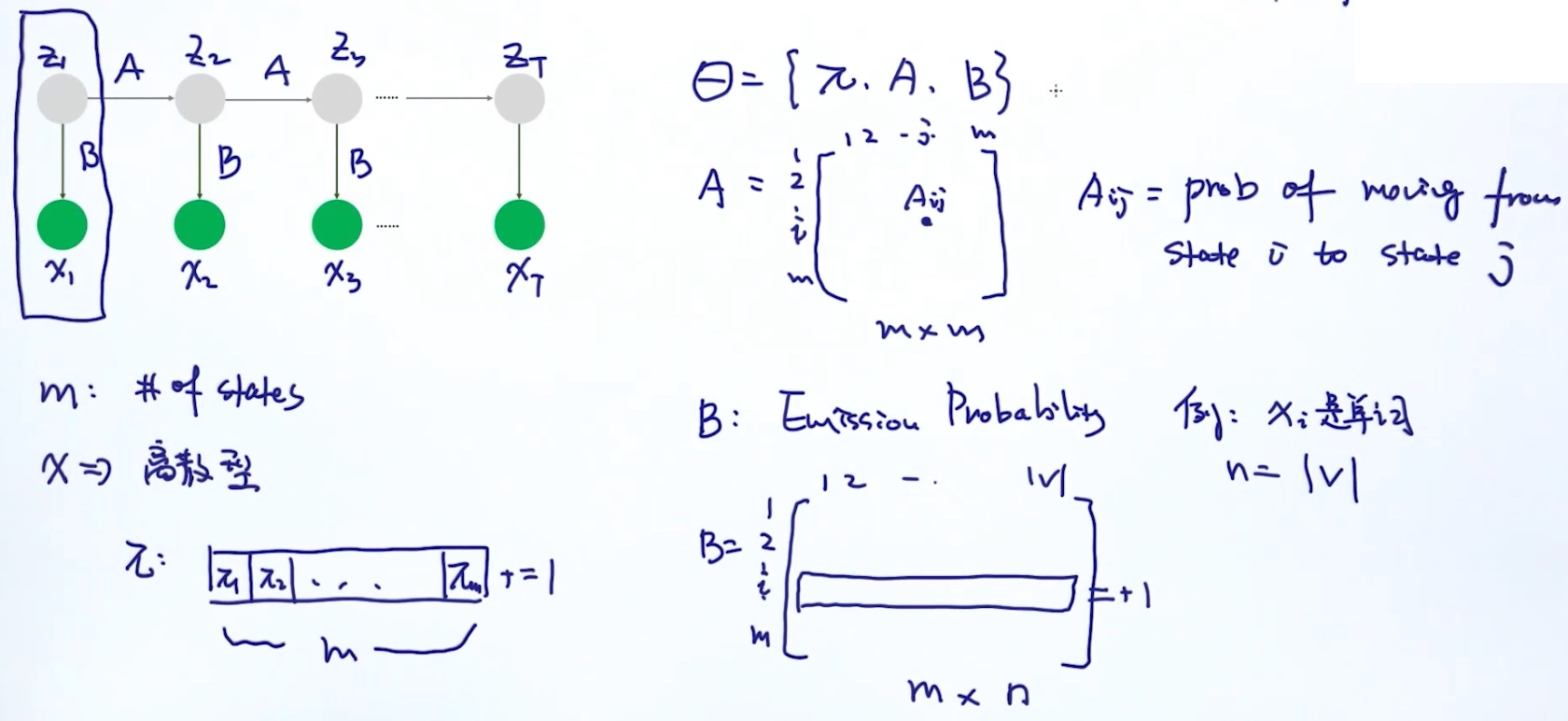 - A: transition probability 状态转移概率
- B: emission probability 生成/输出概率
- Pi: 某一个状态, 在第一个位置的概率
- A: transition probability 状态转移概率
- B: emission probability 生成/输出概率
- Pi: 某一个状态, 在第一个位置的概率
Two Major Tasks
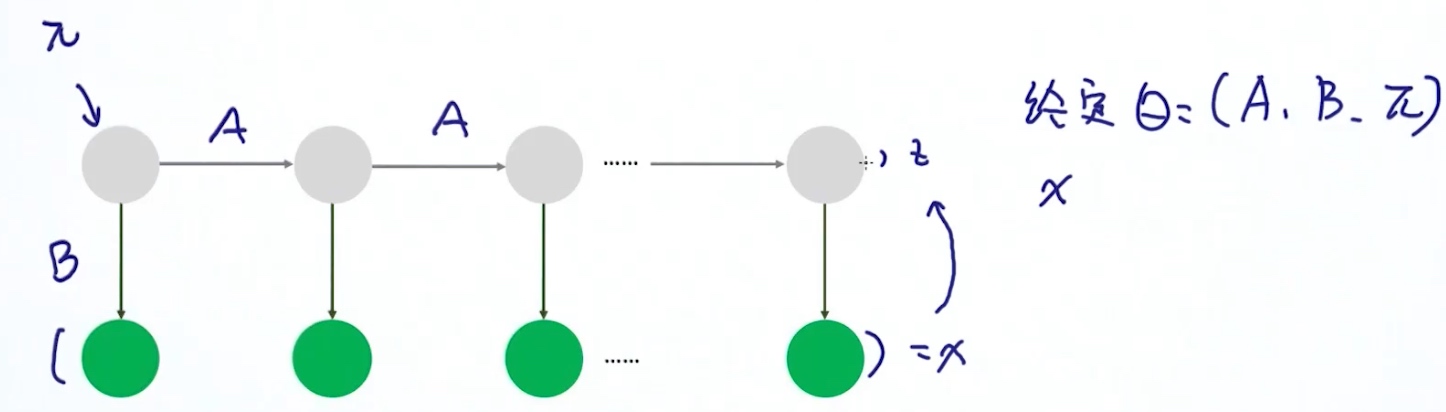 1. 给定模型参数theta, 找出最适合的Z (隐藏状态) Inference / Decoding
2. 估计模型的参数theta
1. complete case: 知道x,z => 最大似然估计(MLE)
2. Incomplete case: 知道x, 不知道z => EM算法
1. 给定模型参数theta, 找出最适合的Z (隐藏状态) Inference / Decoding
2. 估计模型的参数theta
1. complete case: 知道x,z => 最大似然估计(MLE)
2. Incomplete case: 知道x, 不知道z => EM算法
Case1 Finding best Z (维特比算法)
- 枚举所有可能的隐藏状态组合, 算出概率最高的组合
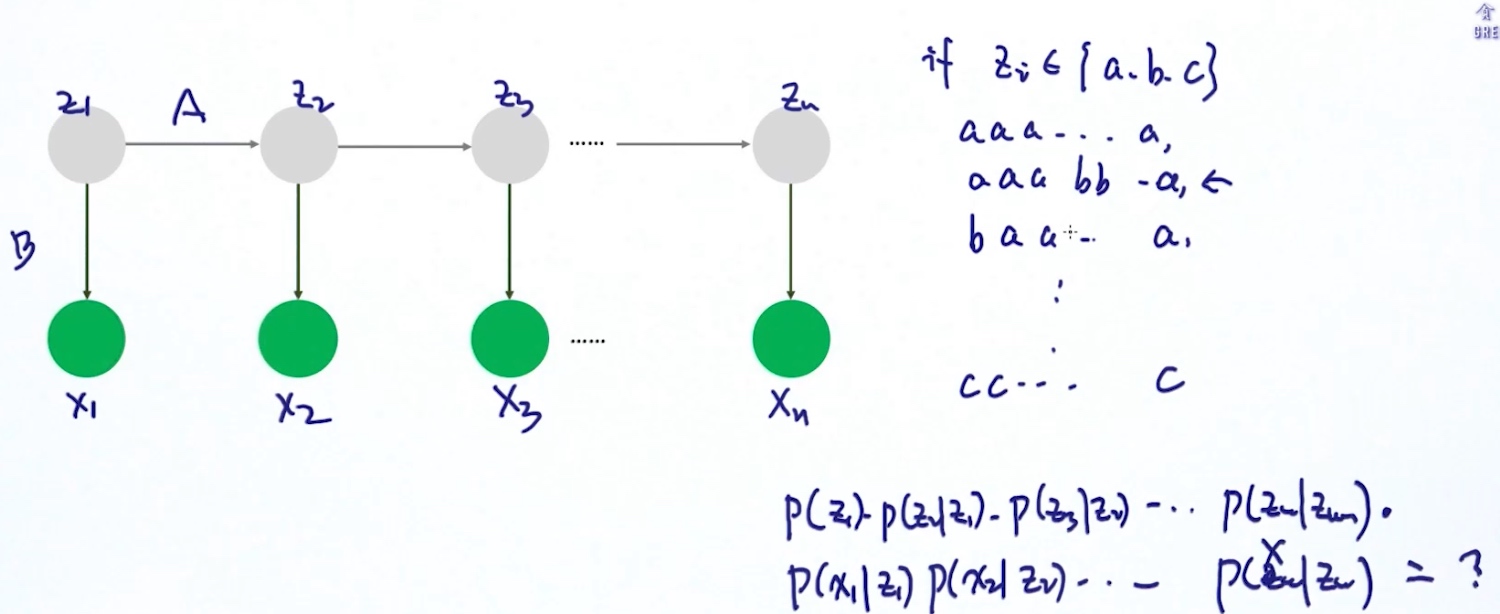 指数级的复杂度
指数级的复杂度 - 维特比算法
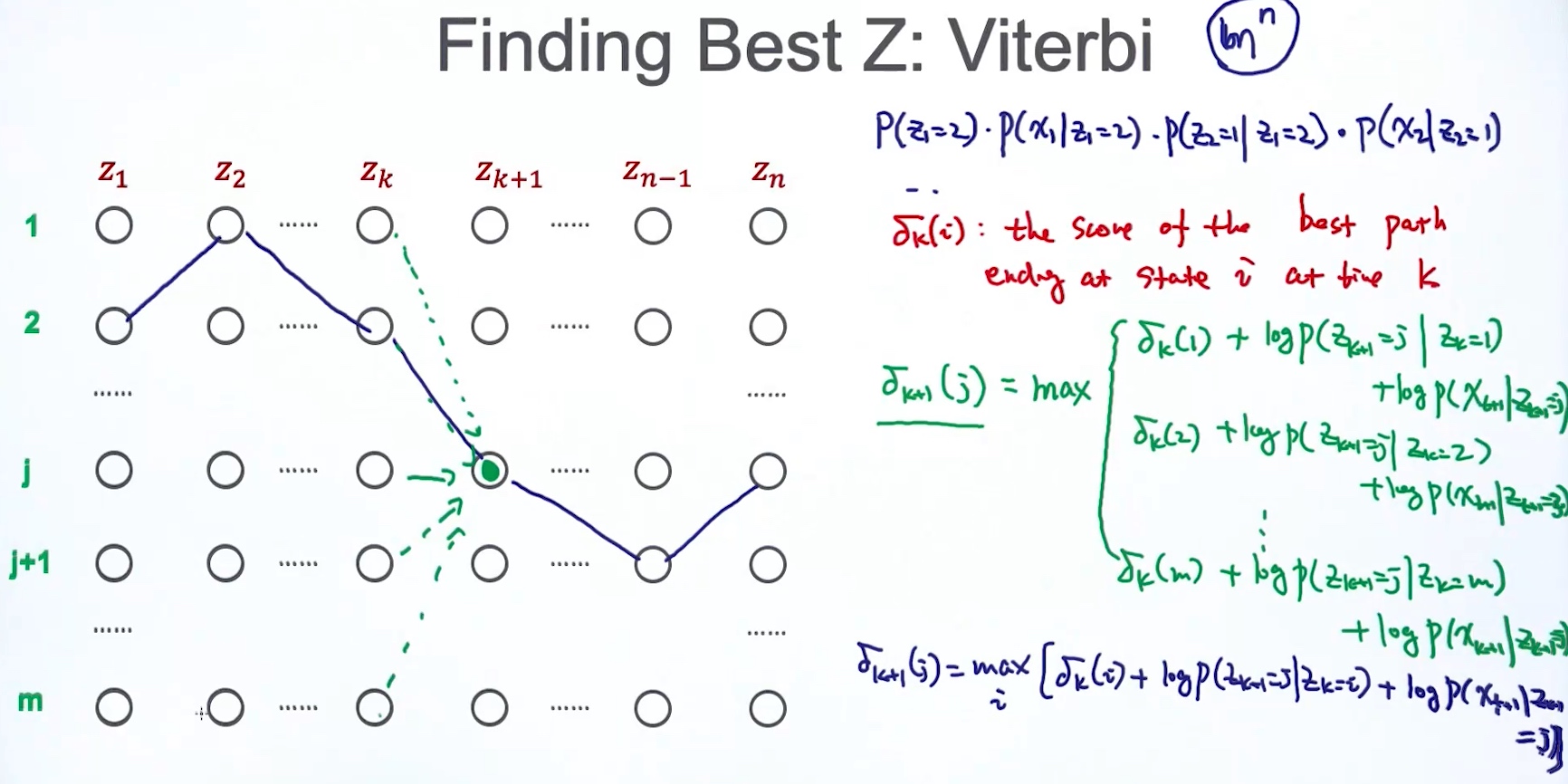 加上一个log, 就有连乘变成连加
$\delta_{k+1}(j) = max_i [\deltak(i)+logP(Z{k+1}=j|Zk = i) + logP(x{k+1}|Z_{k+1}=j)]$ 当前时刻的best score = max(上一个时刻的best score + log当前时刻的转移概率 + log当前时刻的输出概率)
加上一个log, 就有连乘变成连加
$\delta_{k+1}(j) = max_i [\deltak(i)+logP(Z{k+1}=j|Zk = i) + logP(x{k+1}|Z_{k+1}=j)]$ 当前时刻的best score = max(上一个时刻的best score + log当前时刻的转移概率 + log当前时刻的输出概率)
Case2 估计模型参数
Case2.1 Complete Case
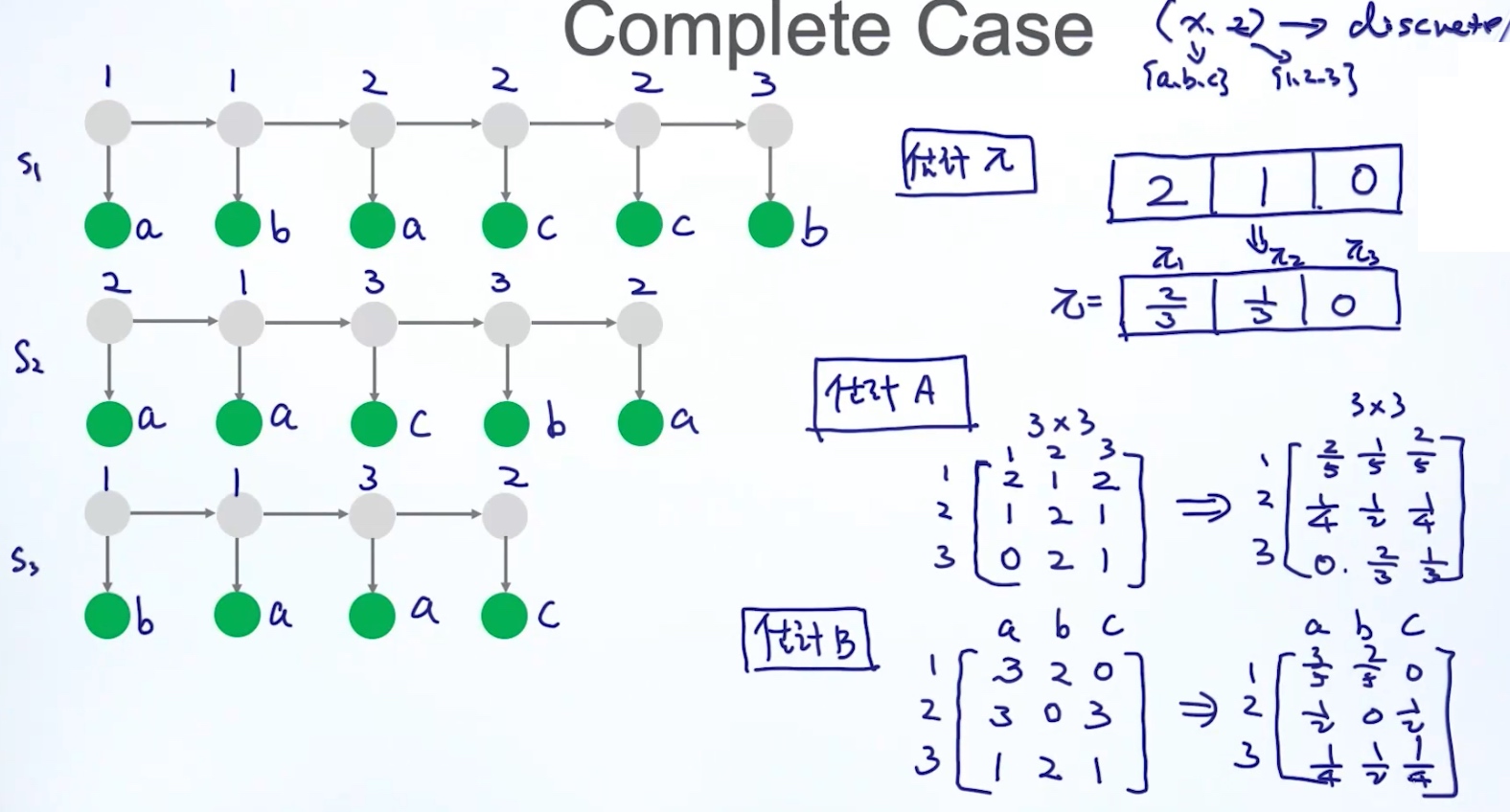
Case2.2 Incomplete Case
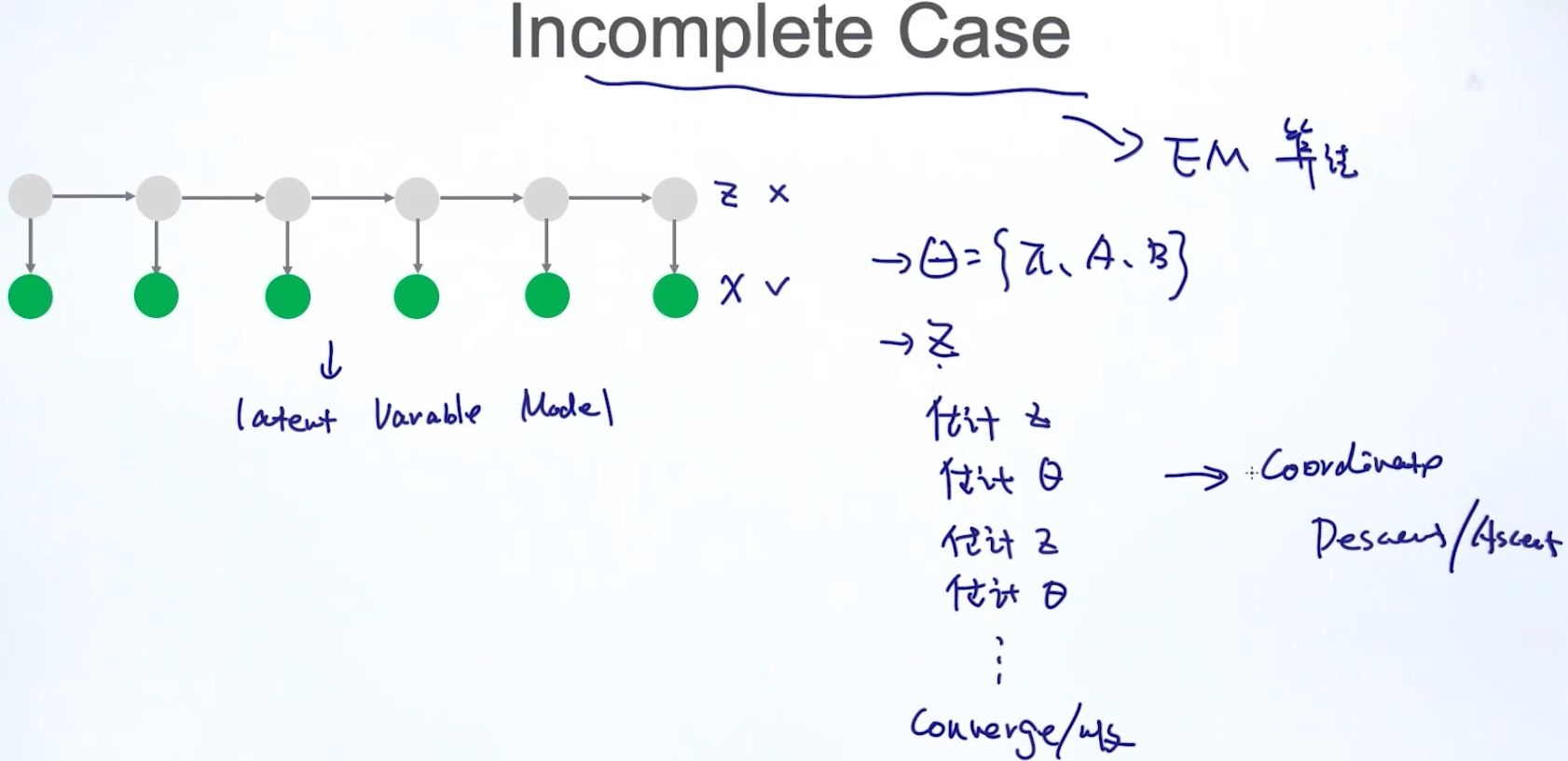 EM算法
$argmax\theta {E{Z|X,\theta} {lnP(X,Z | \theta)}}$
- E-steps: 求Z的期望 (theta已知)
- M-steps: 最大化lnP(X,Z | \theta), 求theta (Z已知)
- repeat…until converge
EM算法
$argmax\theta {E{Z|X,\theta} {lnP(X,Z | \theta)}}$
- E-steps: 求Z的期望 (theta已知)
- M-steps: 最大化lnP(X,Z | \theta), 求theta (Z已知)
- repeat…until converge
while (not converge)
1. compute Z(expectation)
2. update \pi,A,BF/B算法 (Forward/Backward Algorithm)
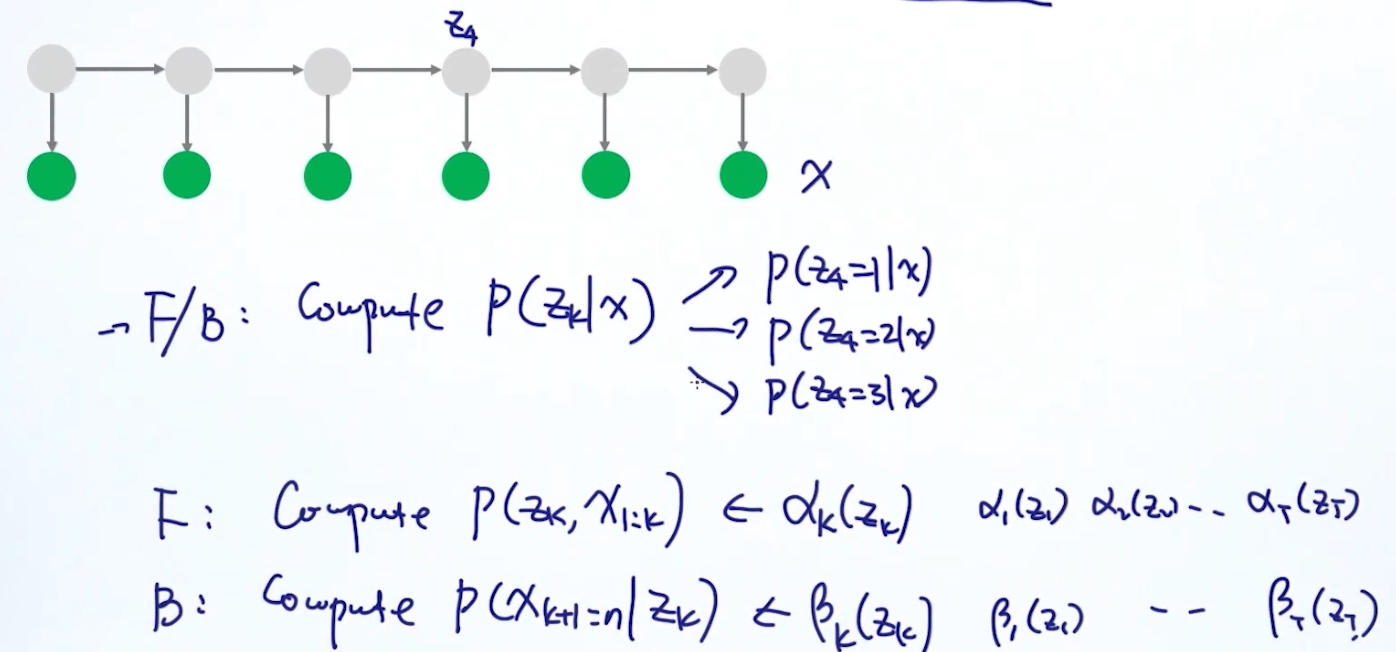 用做参数优化,计算pi,A,B
用做参数优化,计算pi,A,B
估计pi
估计A
估计B
EM算法
表示学习(representation Learning)
E.g.人 -> 年龄, 收入, 性别…(特征); 但是这些信息/特征是目标的最好表达方法? (不是)
- 多余信息
- Nosing
Better Representation: 在Low Dimension中可以找到更好的表示方法 i.e. PCA/ICA/LDA, DL,…
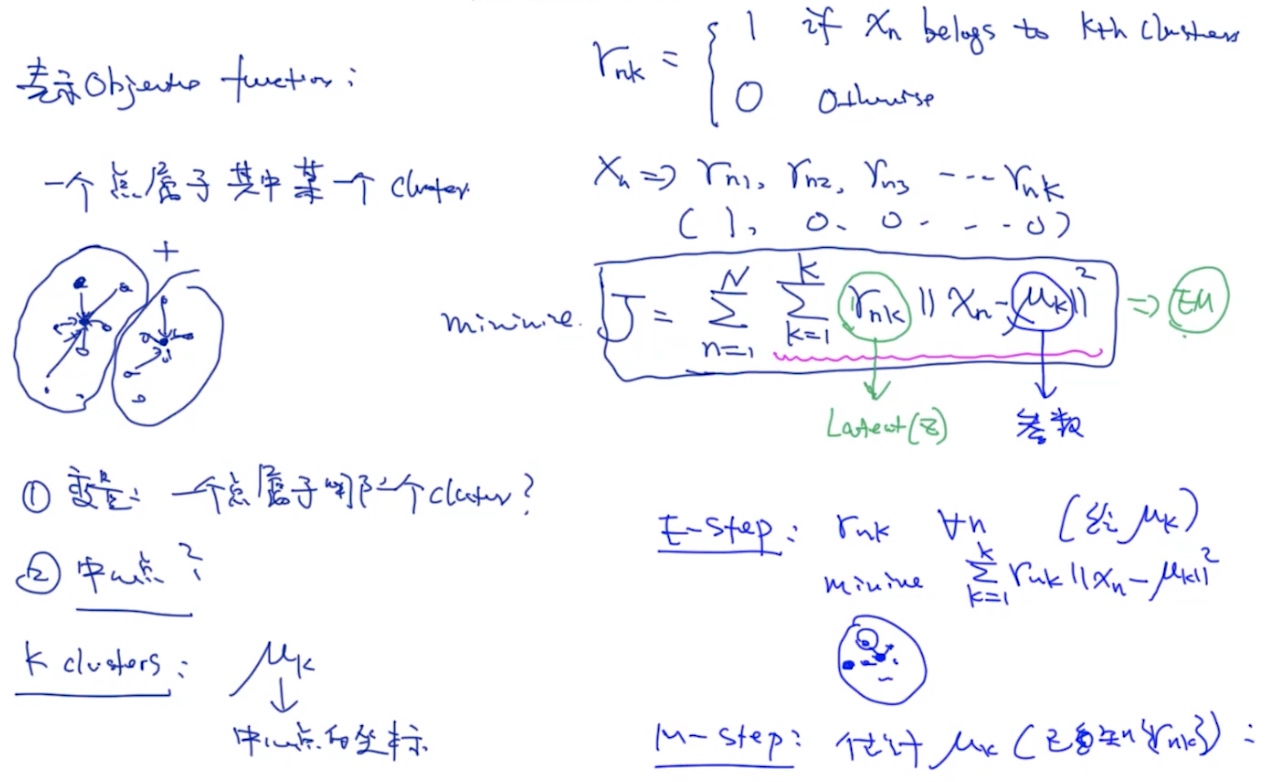
Latent Variable Model (隐变量模型 <- 通过EM算法解决) E.g. K-means (GMM的特例)
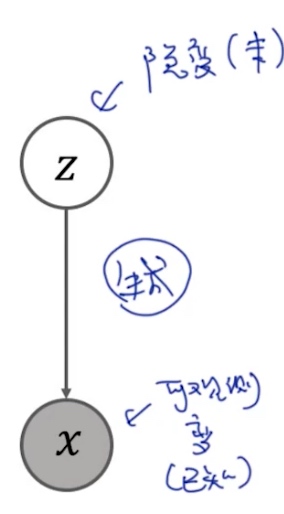 - complete case: (z,x) is observable -> MLE,SGD,…
- incomplete case: (x) is observable, (z) is unobservable -> EM算法
- complete case: (z,x) is observable -> MLE,SGD,…
- incomplete case: (x) is observable, (z) is unobservable -> EM算法
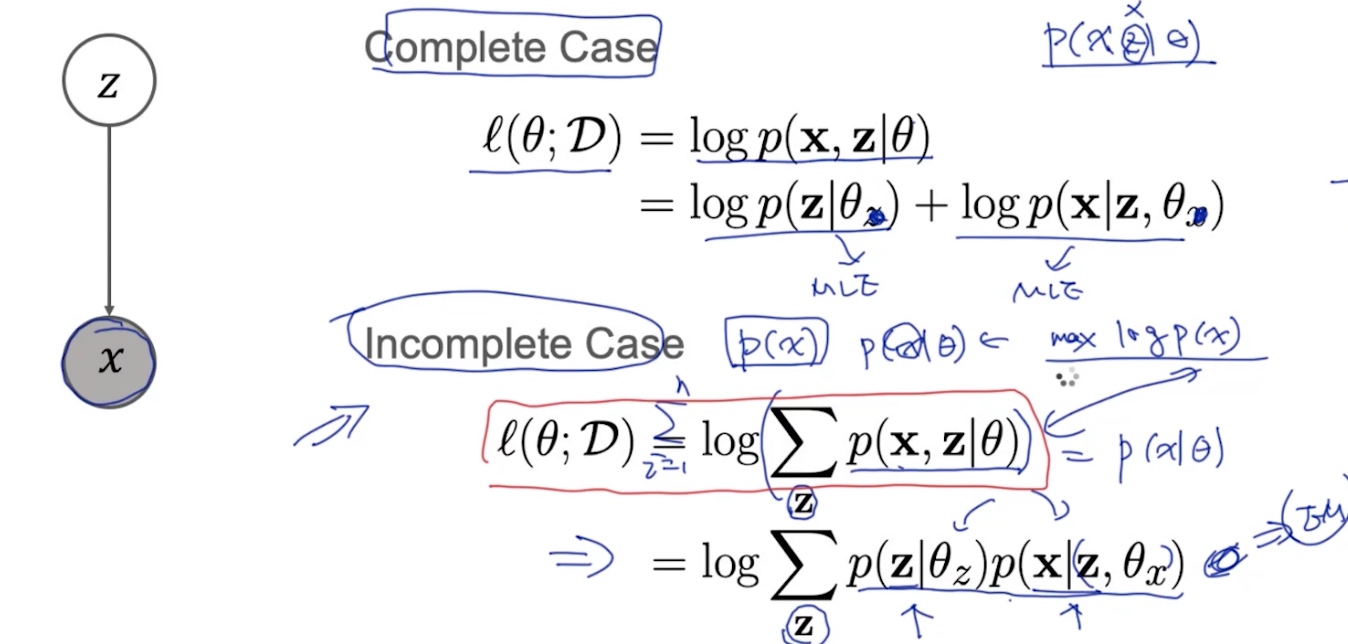
EM Derivation
通过MLE 去推导EM
 Jensen’s inequality
Jensen’s inequality
 x(可观察,已知),z(隐变量,未知),theta(参数)
x(可观察,已知),z(隐变量,未知),theta(参数)
- E-steps: 求Z (theta已知)
- M-steps: 求theta (Z已知)
Remarks on EM:
- 不能保证Global optimal (local optimal), 所以需要重复几次(使用不同的初始化)
- EM算法严格递增
K-means
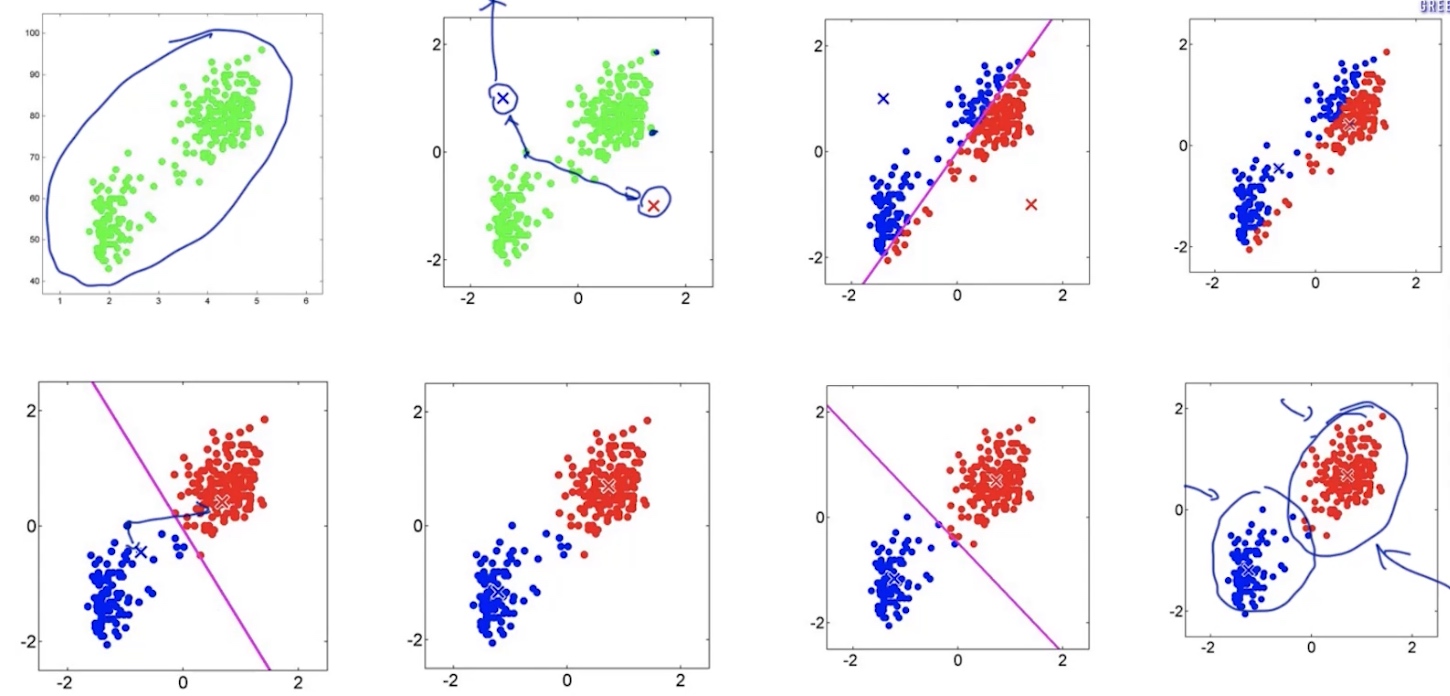
K-means cost function
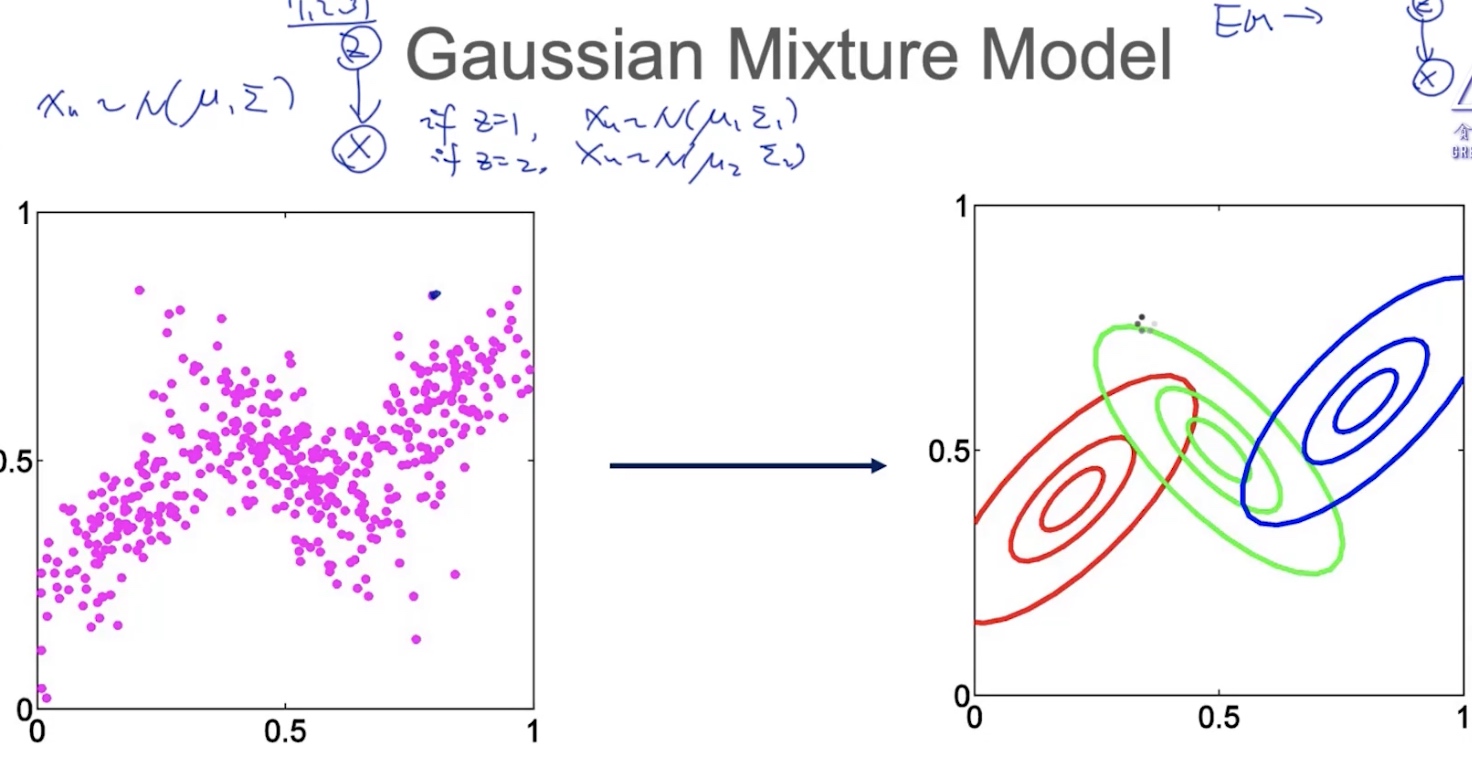
GMM 高斯混合模型
每个点都是通过某个高斯分布$X_n \thicksim (\mu,\sum)$生成出来的
 MLE for GMM
MLE for GMM
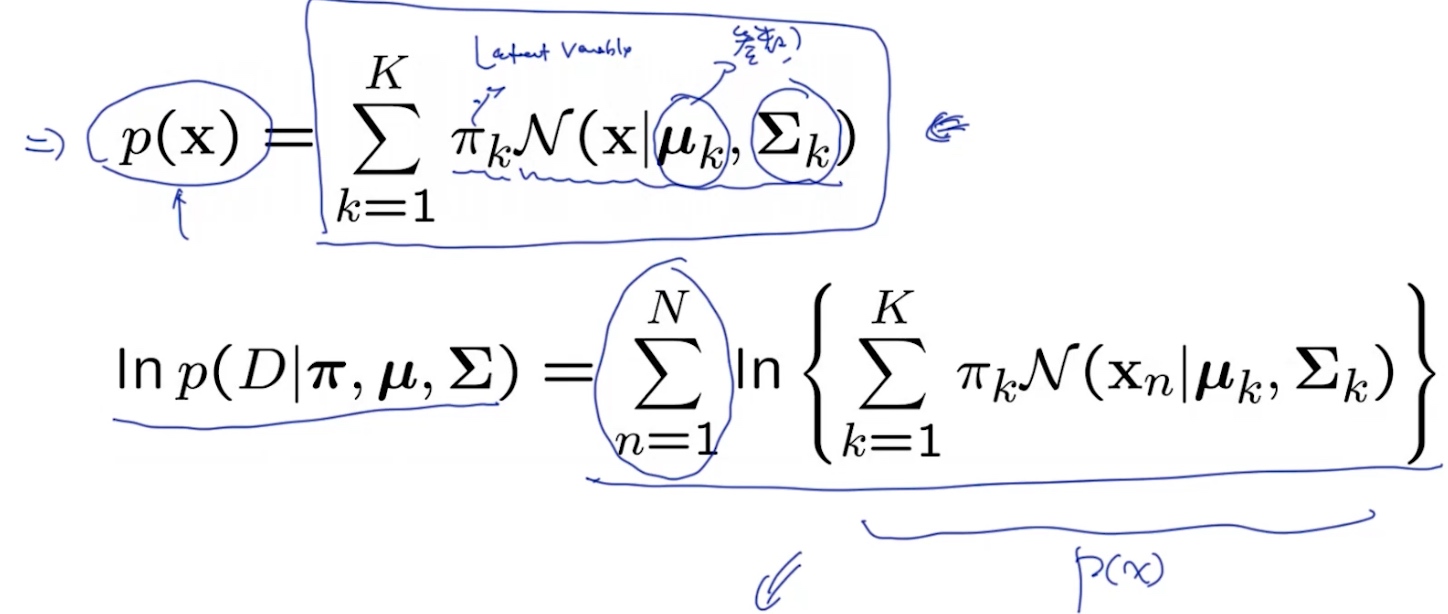
CRF
Directed Graph & Undirected Graph
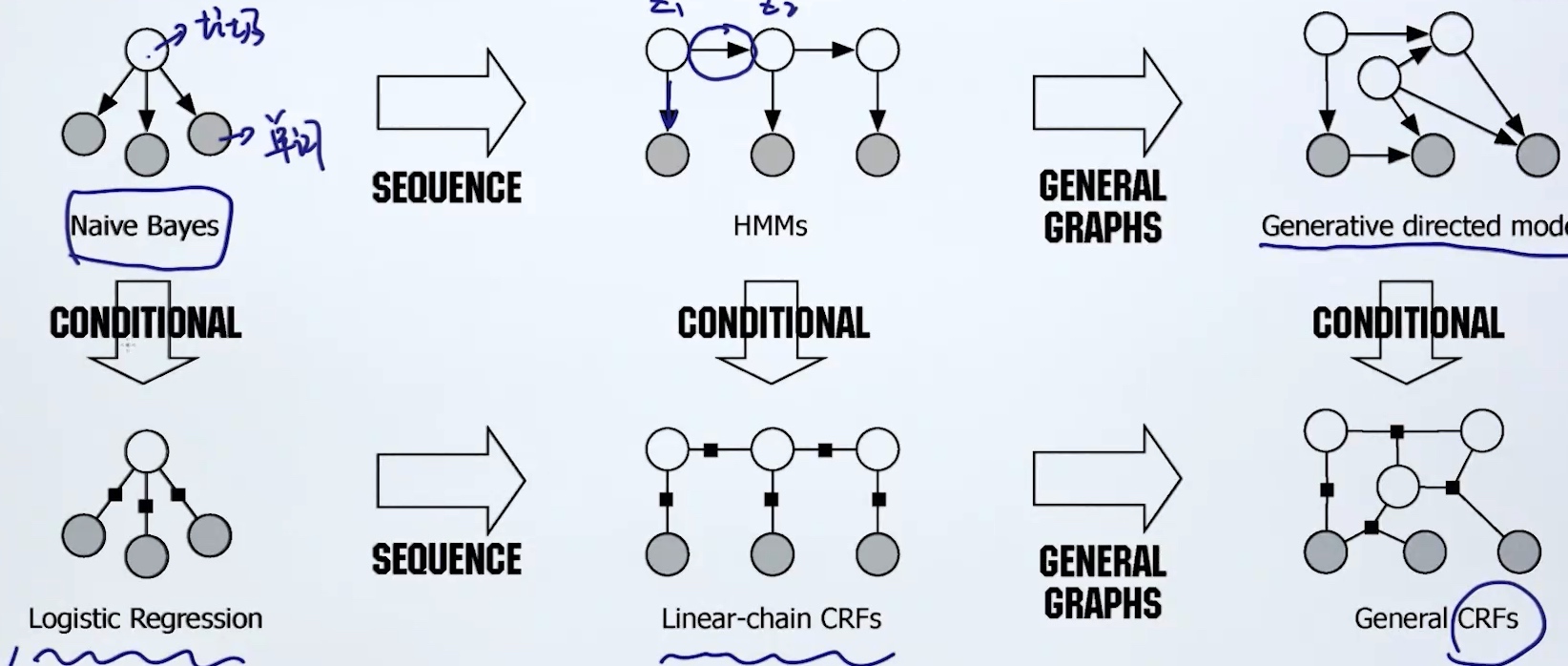 1. 横向: 贝叶斯模型 -> 时序模型 -> 图模型
2. 纵向: 有向 -> 无向
1. 横向: 贝叶斯模型 -> 时序模型 -> 图模型
2. 纵向: 有向 -> 无向
Joint Probability
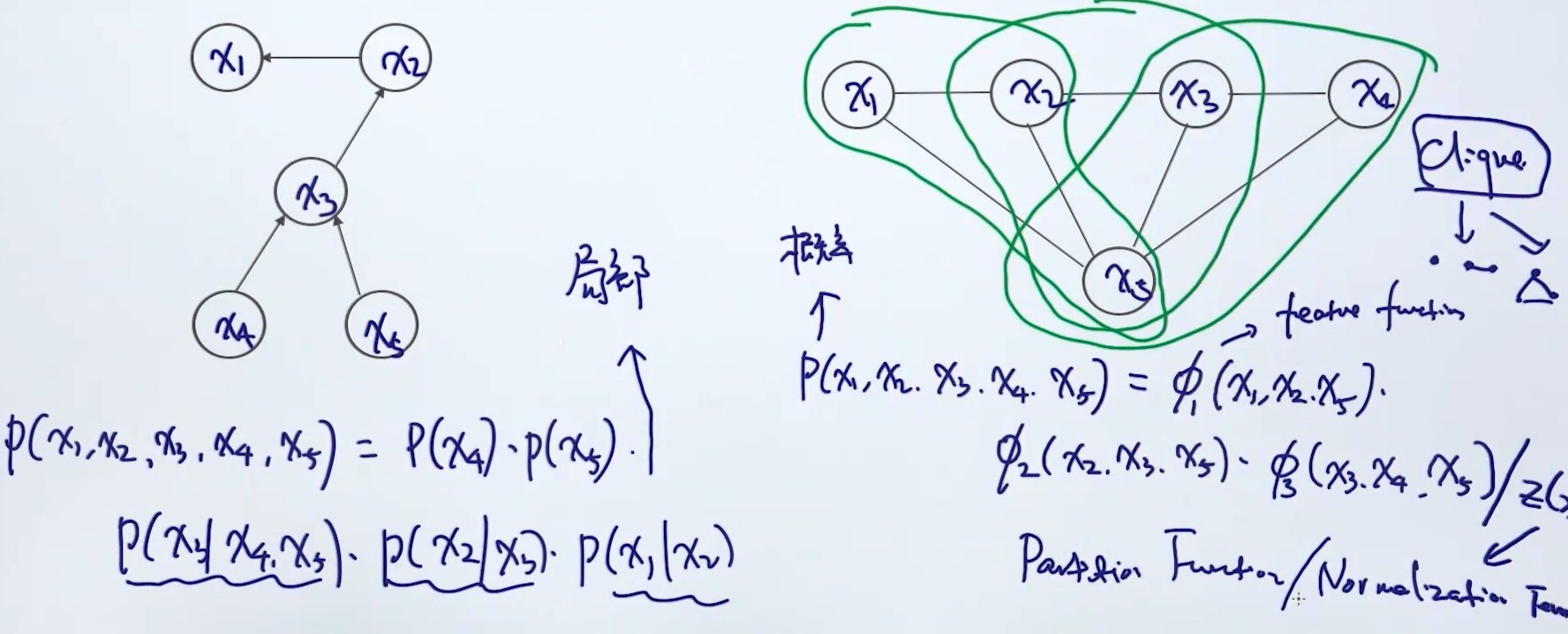
性质:
- Clique: 两两连接
- 概率性质
- $0 \leq p(x) \leq 1$
- $\sum_x p(x) = 1$
- 三个clique相乘, 为了保持概率的性质, 需要normalization
Generative VS Discriminative Model
- P(x,y) VS P(y|x)
- CRF isDiscriminative Model
Log-linear Model
对数线性模型
- 被广泛应用于NLP中,对数线性模型的一个关键优点在于它的灵活性:它允许非常丰富的特征集合被用于模型中.
- Logistic Regression
- Conditional Random Field
- General Formula:
- $p(y|x;w) = \frac{exp \sum^J_{j=1} w_j F_j(x,y)}{Z(x,w)}$
- $w_j$是模型参数
- $F_j(x,y)$是feature function, 表示x和y的关系
- $Z(x,w)$是Normalization / Partition function
Multinomial Logistic Regression
- $p(y|x;w) = \frac{exp \sum^J_{j=1} w_j F_j(x,y)}{Z(x,w)}$
- $F_j(x,y) = X_i \cdot I(y=c) ~~~~x \in R^d, y \in {1,2,..,c}$
- I: Indicator function
- y =c => I=1
- y!=c => I=0


CRF: Log-linear Model for sequential data
Conditional Random Field
 - feature function 被重新定义得跟时序有关
- i代表每个时间步(时刻)
- 把整个时序拆分成多个clique, 每个clique只依赖于x(观测值),当前时刻和下个时刻的tag
- feature function 被重新定义得跟时序有关
- i代表每个时间步(时刻)
- 把整个时序拆分成多个clique, 每个clique只依赖于x(观测值),当前时刻和下个时刻的tag
Inference Problem
- Given model parameter & x to predict y
- $\hat{y}$
词向量
one-hot encoding
- sparse representation
- similarity (无法表达单词相似度 => 导致无法表达语义)
- 表达能力弱
word2vec - distributed representation(把词的信息分布到各个向量中)
- Dense
- meaning (semantic space)
- capacity 表达能力
- Global generation(泛化能力)
Skip-Gram Model
离得越近, 相似度越高
- CBOW: XXOXX 通过左边两个单词和右边两个单词, 去预测中间那个单词
- Skip-Gram: OOXOO 通过中间那个单词, 去左边两个单词和右边两个单词 (常用)
Skim-Gram Model Formulation
- $argmax{\theta} \prod{w \in text} \prod_{c \in context(w)} p(c|w;\theta)$
- w是中心词, context(w)是上下文词
- 简化: $argmax{\theta} \sum{w \in text} \sum_{c \in context(w)} log p(c|w;\theta)$

原本的方程要考虑整个词库, 复杂度太高, need Another formulation