GPT-2
LM
A language model is a model which learns to predict the probability of a sequence of words. In simpler words, language models essentially predict the next word given some text. By training language models on specific texts, it is possible to make the model learn the writing style of that text
Perplexity Intuition (and its derivation)
https://towardsdatascience.com/perplexity-intuition-and-derivation-105dd481c8f3
In general, perplexity is a measurement of how well a probability model predicts a sample. In the context of Natural Language Processing, perplexity is one way to evaluate language models
$$PP(W) = P(w_1w_2...w_N)^{-\frac{1}{N}}$$
perplexity of a discrete probability distribution:
$$2^{H(p)} = 2^{-\sum_xp(x)log_2p(x)}$$
where H(p) is the entropy of the distribution p(x) and x is a random variable over all possible events. H(p) =-Σ p(x) log p(x)
!!!perplexity is just an exponentiation of the entropy!!!
- Entropy is the average number of bits to encode the information contained in a random variable, so the exponentiation of the entropy should be the total amount of all possible information, or more precisely, the weighted average number of choices a random variable has.
- For example, if the average sentence in the test set could be coded in 100 bits, the model perplexity is 2¹⁰⁰ per sentence
Definition:
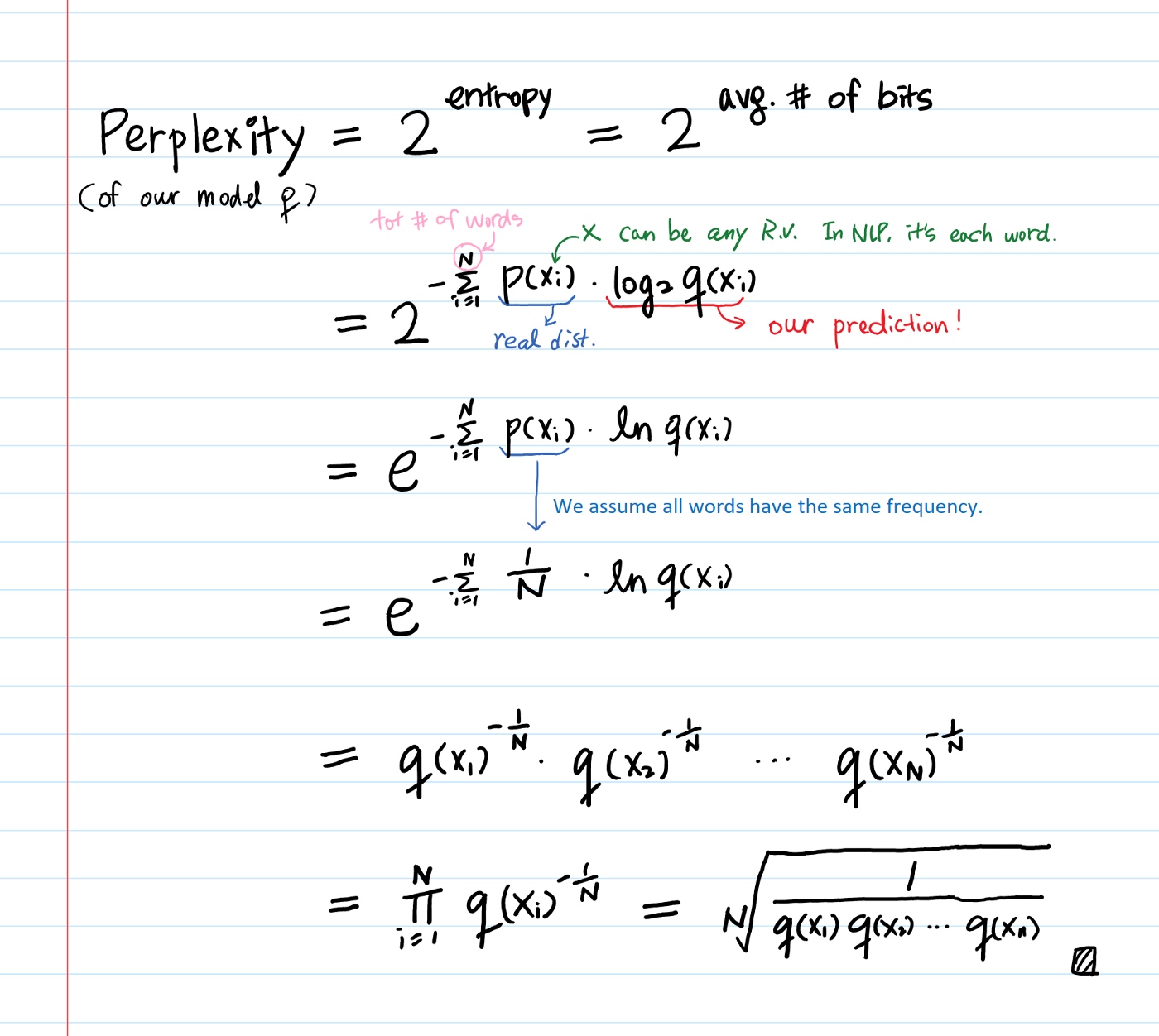 Where
Where
- p : A probability distribution that we want to model. A training sample is drawn from p and it’s unknown distribution.
- q : A proposed probability model. Our prediction
Can evaluate prediction q by testing against samples drawn from p. Then it’s basically calculating the cross-entropy. In the derivation above, we assumed all words have the same probability (1 / # of words) in p.
Takeaway:
- Less entropy (or less disordered system) is favorable over more entropy. Because predictable results are preferred over randomness. This is why people say low perplexity is good and high perplexity is bad since the perplexity is the exponentiation of the entropy.
- A language model is a probability distribution over sentences. And the best language model is one that best predicts an unseen test set.
- Why do we use perplexity instead of entropy?
- If we think of perplexity as a branching factor (the weighted average number of choices a random variable has), then that number is easier to understand than the entropy.
code
In this blog, we will leverage the awesome HuggingFace’s transformer repository to train our own GPT-2 model on text from Harry Potter books. We will provide a sentence prompt to the model and the model will complete the text. In order to train the model, we will feed all Harry Potter books for the model to learn from them. We have cloned the huggingface repo and updated the code to correctly perform language model training and inference. Please follow along on my Github repo.
Downloading Harry Potter books and preprocessing the text
The first step is downloading all the harry potter books and preprocessing the text. We scraped the text from the first 4books and merged it together. Then we wrote a short piece of code to remove unnecessary text like the page numbers from the merged text. Finally the GPT-2 model needs both train and validation text. So we take first 90% of the data as training sample and the remaining as validation sample. The preprocessing code is here.
Training a GPT-2 model
To train the model we use the script — run_lm_finetuning.py. The script takes as input the model type and its size, as well as the preprocessed text. The script also provides a bunch of hyperparameters that can be tweaked in order to customize the training process. The code snippet for training is:
cd examples ## Move to examples directory
python run_lm_finetuning.py \
--output_dir=output \
--model_type=gpt2 \
--model_name_or_path=gpt2-medium \
--do_train \
--train_data_file='input_data/train_harry.txt' \
--do_eval \
--eval_data_file='input_data/val_harry.txt'\
--overwrite_output_dir\
--block_size=200\
--per_gpu_train_batch_size=1\
--save_steps 5000\
--num_train_epochs=2The parameters used here are explained as follows:
- Output_dir is the name of the folder where the model weights are stored.
- Model_type is the name of the model. In our case we are training on the gpt-2 architecture, we use ‘gpt-2’.
- Model_name_or_path is where we define the model size to be used.(’gpt2’ for small, ‘gpt2-medium’ for a medium model and ‘gpt2-large’ for a large model)
- Do_train is essentially a flag which we define to train the model.
- train_data_file is used to specify the training file name.
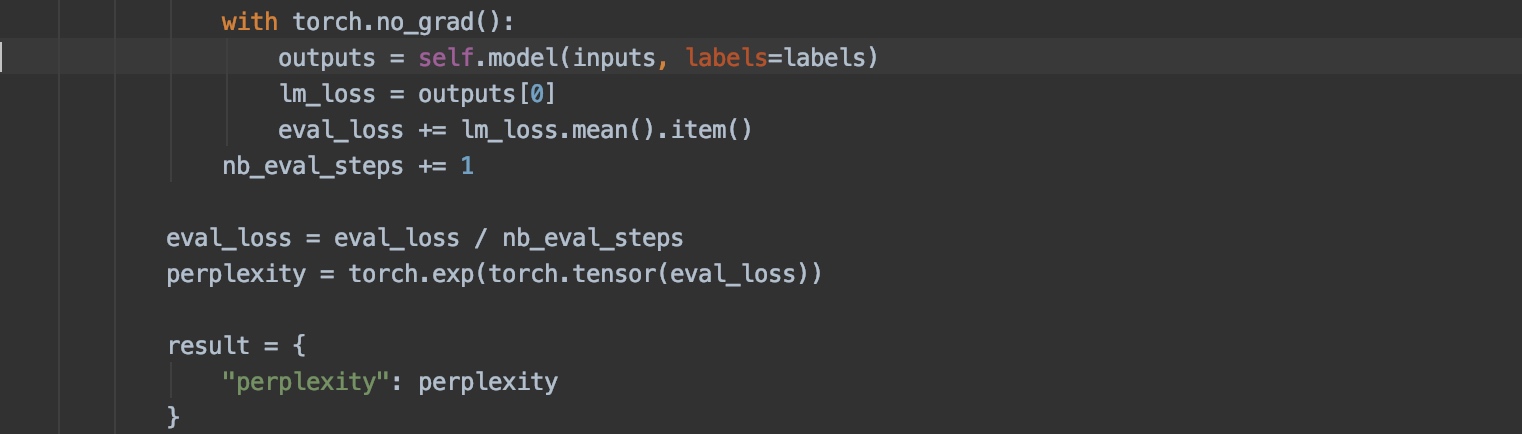
- Do_eval is a flag which we define whether to evaluate the model or not, if we don’t define this, there would not be a perplexity score calculated.
- Eval_data_file is used to specify the test file name.
- gradient_accumulation_steps is a parameter used to define the number of updates steps to accumulate before performing a backward/update pass.
- Overwrite_output_dir is a parameter which when specified overwrites the output directory with new weights.
- block_size is a parameter according to which the training dataset will be truncated in block of this size for training.
- Per_gpu_train_batch_size is the batch size per GPU/CPU for training.
- Save steps — allows you to periodically save weights before the final set of weights
- num_epochs — Determines how many epochs are run.
We trained a medium GPT-2 model on the text of 4harry potter books. This model took only 10 min to train on a GTX 1080 Ti. The perplexity score of the trained model was 12.71. Read this blog to learn more about Perplexity score. But remember, lower the score, the better the model is.
Inference Script
Once the model is trained, we can run inference using it. The inference script is run_generation.py
For doing inference, the input text is first encoded through the tokenizer , then the result is passed through a generate function where the generation of text happens based on parameters like temperature, top-p and k values.
The code snippet for doing inference is:
cd examples
python run_generation.py --model_type gpt2 --model_name_or_path output --length 300 --prompt "Malfoy hadn’t noticed anything."These parameters are explained below:
- model_name_or_path : This is the folder path where the weights of the trained model are stored.
- Prompt: This is the input prompt based on which the rest of the text will be generated.
- Length: This parameter controls the length of characters to be generated in the output.
Some additional parameters that can be tweaked are:
- Temperature: This parameter decides how adventurous the model gets with its word selection.

- p : This parameter controls how broad a range of continuations are considered. Set it high to consider all continuations. Set it low to just consider likely continuations. The overall effect is similar to temperature, but more subtle.
- k: This parameter controls the number of beams or parallel searches through the sequence of probabilities. Higher the value, better the accuracy , but slower the speed.
- Seed: This parameter helps in setting the seed.
- Repetition_penalty: This parameter penalizes the model for repeating the words chosen.
Conclusion
The advent of transformers has truly revolutionized many Natural language processing tasks, and language generation is one of them. The potential of a language generation model is huge and can be leveraged in many applications like chatbots, long answer generation, writing automated reports and many more. In this blog, we understood the working of transformers, how they are used in language generation and some examples of how anyone can leverage these architectures to train their own language model and generate text.
I am extremely passionate about NLP, Transformers and deep learning in general. I have my own deep learning consultancy and love to work on interesting problems. I have helped many startups deploy innovative AI based solutions
GPT-2 Chinese
总结如下:
- 模型的收敛取决于词嵌入的维度,维度越大收敛越快越好
- head与隐藏层数可以适当裁剪,隐藏层可以设置高一些,multi-head感觉超过5层之后似乎对于生成的结果影响并不大
- 模型长度不影响训练,但与学习效果有很大关联,能大些就大些。
- 训练效率问题,模型参数与训练效率息息相关,合理的batch数量、GPU显存、适当的模型参数(multi-head拉低,layer尽量比head大),100%使用率还是能达到的
- 参数与batch设置为双数
一句话:
降低multi-head,适当保持layer层,embed越大越好,ctx,学习长度当然大了好了,数据集交叉学习收敛更快,最终生成效果更好,loss压到0.3以下,基本可以生成十分通顺的文章了
参数表:
- ctx:512
- embed:800
- head:10
- layer:10
- positions:512
/usr/local/lib/python3.6/dist-packages/torch/optim/lr_scheduler.py:231: UserWarning: To get the last learning rate computed by the scheduler, please use get_last_lr().
warnings.warn(“To get the last learning rate computed by the scheduler, “
ctx可长可短,短了epoch就多些,模型内存少一些,batch就能大一些,要根据自己显卡配置跟模型需求来。head跟layer小,训练效率就高,单卡TITAN V改水冷,超频到极限,跑起来GPU利用率可以达到92以上,最高98,温度能达到80摄氏度。
词嵌入向量大一些好,不要超过1000,不要低于500,是比较适合的,超过1000虽然下降稍快一些,但提升很小开销太大,没价值。
LR不能大于0.0004,超过这个值后loss会在某个值震荡无法继续下降,我使用的最佳LR是0.0003,能够得到0.2的loss,是否能够再低,没有再做尝试。
调节学习率,从大向小调,建议每次除以5;我的项目即是因为学习率过大过小都不收敛引起的; 如果学习率调好后,需要调节batchsize大小,如batchsize调大2倍,则将学习率对应调大(项目测试调大2~3倍OK),反之,学习率对应调小
想要达到显卡性能最大化,DataLoader是很重要的一个环节,prefetch_generator是必不可少的,我是将训练集直接加载到内存。prefetch_generator 包会自动在后台加载下一个step所需的数据,大家可以加缩进改目录地址直接用。为什么要self.char_len//2呢,比如ctx是1024,每次取1024个字符用作训练,那么对于上一个1024中的某些句子与下一个1024中的某些句子的关联就不能很好的学习到,所以,这样操作,第一个epoch,我的loss就能下降到4以下,梯度累加20个step,1.0的梯度裁剪上限,梯度裁剪上限不要调高,很容易过度学习,后期会在某个区间持续震荡。
另外,print操作对显卡利用率影响太大,本质上print属于IO操作,非常耗时,我是用jupyter训练的,livelossplot了解一下。
可能有些同学会问,我这个模型参数量已经很小了,最终生成效果是不是会有影响? 调参是很玄学的过程,本身就是黑箱操作,我追求的是最大化训练效率(相比于原有的train_single.py,训练速度能提升60%左右,显卡利用率高了。),参数量小,epoch也会加大,相对好训练些,每个人的配置不同,参数调整是无法直接复制黏贴使用的。 而且我已经反复训练超过300次了,不断调整参数,以最终生成质量来看,小模型未必不能生成高质量文章,取决于你的loss(但想要生成万字长文,ctx同样需要万字以上,否则超出模型长度之后的内容内容无法扩散(斗破为例,超出512长度后,不断的花式秀“异火”,句句不重样,句句是“异火”),loss再低都没用,这样应该能够明白吧?)。 目前已经上云训练我的26G超大数据集,4X2080Ti,模型参数有些变化,ctx加长到3072,head跟layer为6,embed是768,等训练好了再看看生成效果如何。 fp16,放弃吧,误差问题,loss就是过山车,O1O2都是这样,O3直接就是在玩耍,根本不是在学习。
pretrain的话,要禁用掉动态学习率,否则loss不降反升
以下是我的DataLoader:
from prefetch_generator import BackgroundGenerator
class MyDataset(Dataset):
def init(self,num):
self.char_len=num
self.char=[]
self.get_text()
self.sector=0
def getitem(self, index):
self.sector=(index+1)*self.char_len
#data=Variable(torch.LongTensor(self.char[self.sector:self.sector+self.char_len])).to(device)
data=Variable(torch.LongTensor(self.char[(self.sector-(self.char_len//2)):(self.sector+(self.char_len//2))])).to(device)
#label=Variable(torch.LongTensor(self.char[(self.sector-(self.char_len//2)):(self.sector+(self.char_len//2))])).to(device)
return data
def get_text(self):
for e in range(100):
with open('E:/jupyter/gptch/data/tokenized/tokenized_train_{}.txt'.format(e), 'r') as f:
self.char.extend([int(x) for x in f.read().replace('\n','').strip().split()])
#self.section=[n for n in [self.char[i:i+self.char_len] for i in range(0,len(self.char),self.char_len//2)] if len(n)==self.char_len]
def len(self):
return (len(self.char)-(self.char_len//2))//self.char_len
def char_len(self):
return len(self.char)
class DataLoaderX(DataLoader):
def iter(self):
return BackgroundGenerator(super().iter())
train_loader = DataLoaderX(dataset=MyDataset(n_ctx),shuffle=True,pin_memory=False, batch_size=batch_size)Ref
https://towardsdatascience.com/train-a-gpt-2-transformer-to-write-harry-potter-books-edf8b2e3f3db
https://github.com/priya-dwivedi/Deep-Learning/tree/master/GPT2-HarryPotter-Training
- https://github.com/interactive-fiction-class/interactive-fiction-class.github.io/blob/master/homeworks/language-model/hw4_transformer.ipynb
- https://colab.research.google.com/github/interactive-fiction-class/interactive-fiction-class.github.io/blob/master/homeworks/language-model/hw4_transformer.ipynb#scrollTo=8VzV8iTrphJl