CS224n Week4
Lecture 07 Vanishing Gradients and Fancy RNNs
Vanishing Gradients
在训练RNN的时候可能会遇到vanishing gradient的现象, 如下图, 方框中的微分如果比较小, 那反向传播时梯度就会越来越小.
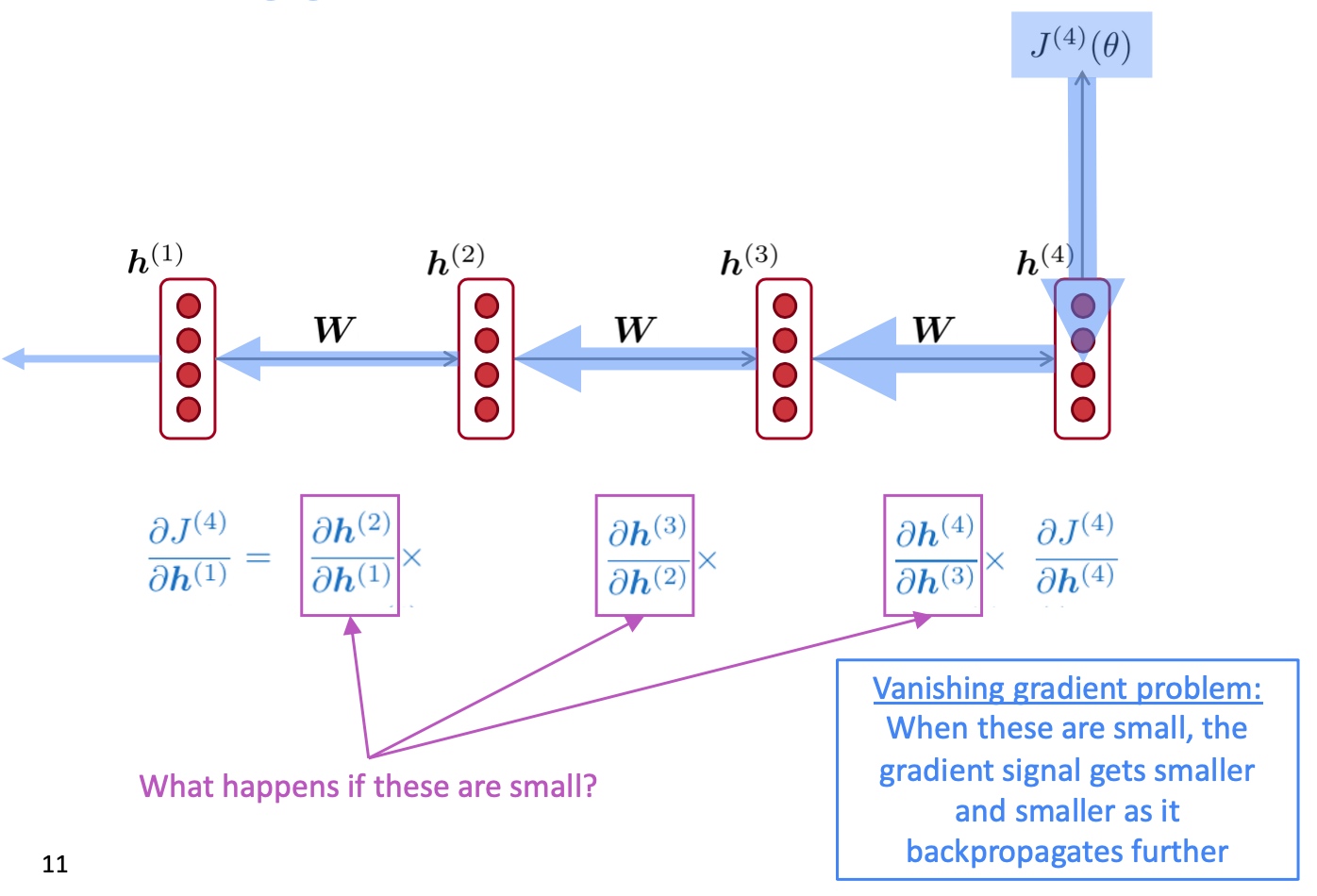
- Q: 为什么梯度消失是一个问题?
- A: 因为它使得更新模型weight的时候, 距离越近的loss影响越大, 距离较远的loss影响越小, 这不符合实际情况(dependency parsing的时候远距离单词可能反而是dependence word)
- 例子: he writer of the books __ planning a sequel (答案是is)

- 梯度消失可能使得RNN更偏向于sequential recency(顺序近因), 因为它学习不到长距的dependency
Exploding Gradients
与梯度消失类似, 如果梯度太大, 则随着时间越远该梯度指数级增大,这又造成了另一问题exploding gradient梯度爆炸,这就会造成在更新时,步伐过大而越过了极值点(overshooting),无法达到收敛值.
一个简单的解决方案是gradient clipping,即如果梯度大于某一阈值,则在应用SGD更新之前按比例缩小梯度值,即仍然向梯度下降的方向行进但是其步长缩小,其伪代码如下:
 Intuition: take a step in the same direction, but a smaller step
Intuition: take a step in the same direction, but a smaller step
不进行clipping与进行clipping的学习过程对比如下:
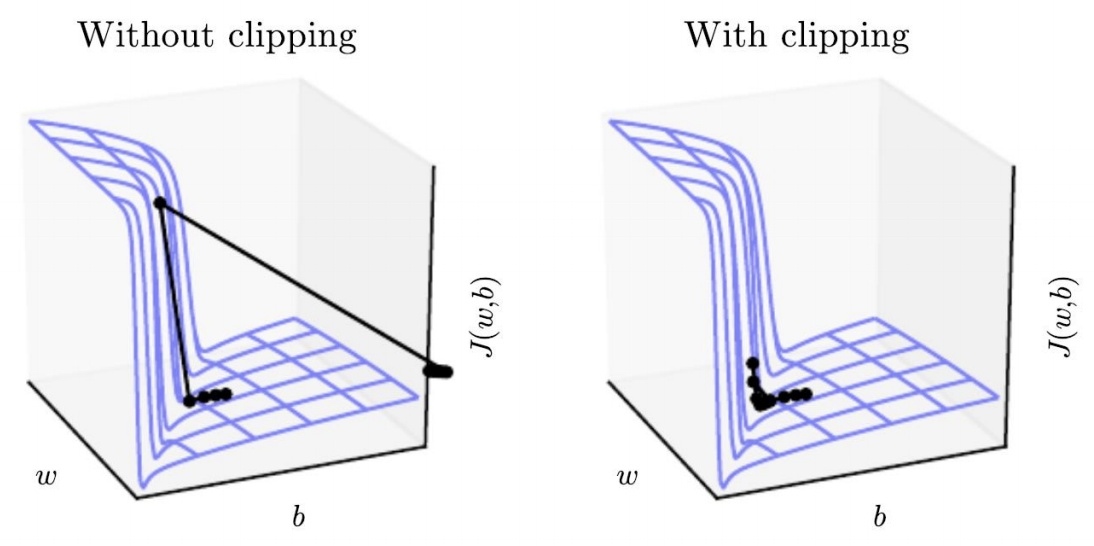
可见左图中由于没有进行clipping,步伐长度过大,导致损失函数更新到一个不理想的区域,而右图中进行clipping后每次步进减小,能更有效的达到极值点区域.
- 梯度爆炸问题, 可以通过简单的gradient clipping来解决.
- 梯度消失问题(梯度消失的出现有一个关键的原因就是训练信息不会被记录, 在训练的时候hidden state一直再被更新, 所以要做的就是防止这一点), 则可以通过设置一些存储单元来更有效的进行长程信息的, 再加一些门(gate)来控制信息的流入流出(就可以选择遗忘哪些信息, 记住哪些信息), LSTM与GRU都是基于此基本思想设计的
LSTM
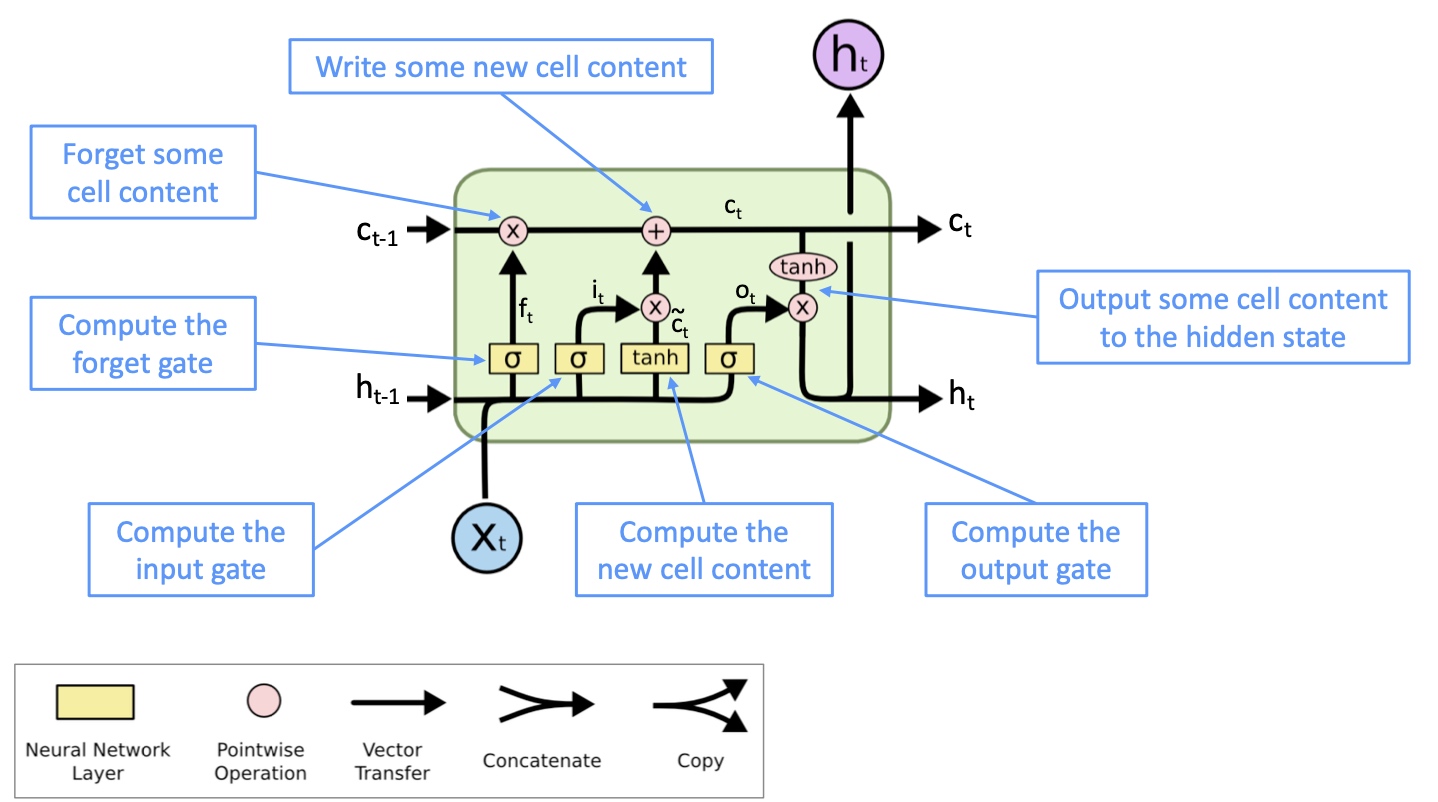
LSTM, 全称Long Short Term Memory。其基本思路是除了hidden state $h_t$ 之外,引入cell state $c_t$ 来存储长程信息,LSTM可以通过控制gate来消除,存储或写入cell state.
LSTM的公式如下:
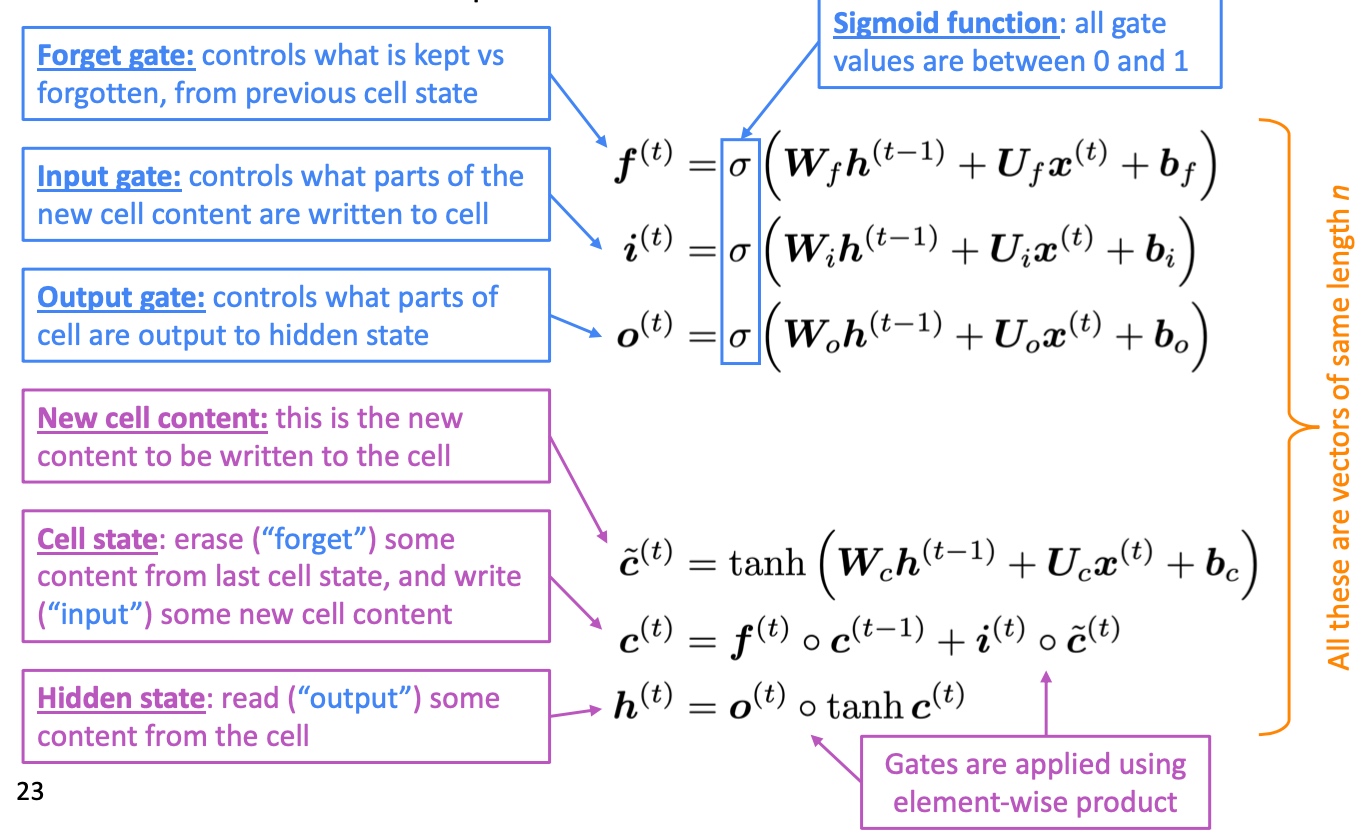
- New Memory cell
$\hat{c}_t$通过将新的输入$x_t$与代表之前的context的hidden state$h_{t-1}$结合生成新的memory - Input gate
$i_t$决定了新的信息是否有保留的价值 - Forget gate
$f_t$决定了之前的cell state有多少保留的价值 - Final memory cell
$c_t$通过将forget gate与前memory cell作元素积得到了前memory cell需要传递下去的信息,并与input gate和新的memory cell的元素积求和. 极端情况是forget gate值为1,则之前的memory cell的全部信息都会传递下去,使得梯度消失问题不复存在 - output gate
$o_t$决定了memory cell 中有多少信息需要保存在hidden state中
GRU
GRU(gated recurrent unit)可以看做是将LSTM中的forget gate和input gate合并成了一个update gate,即下式中的$u_t$,同时将cell state也合并到hidden state中.
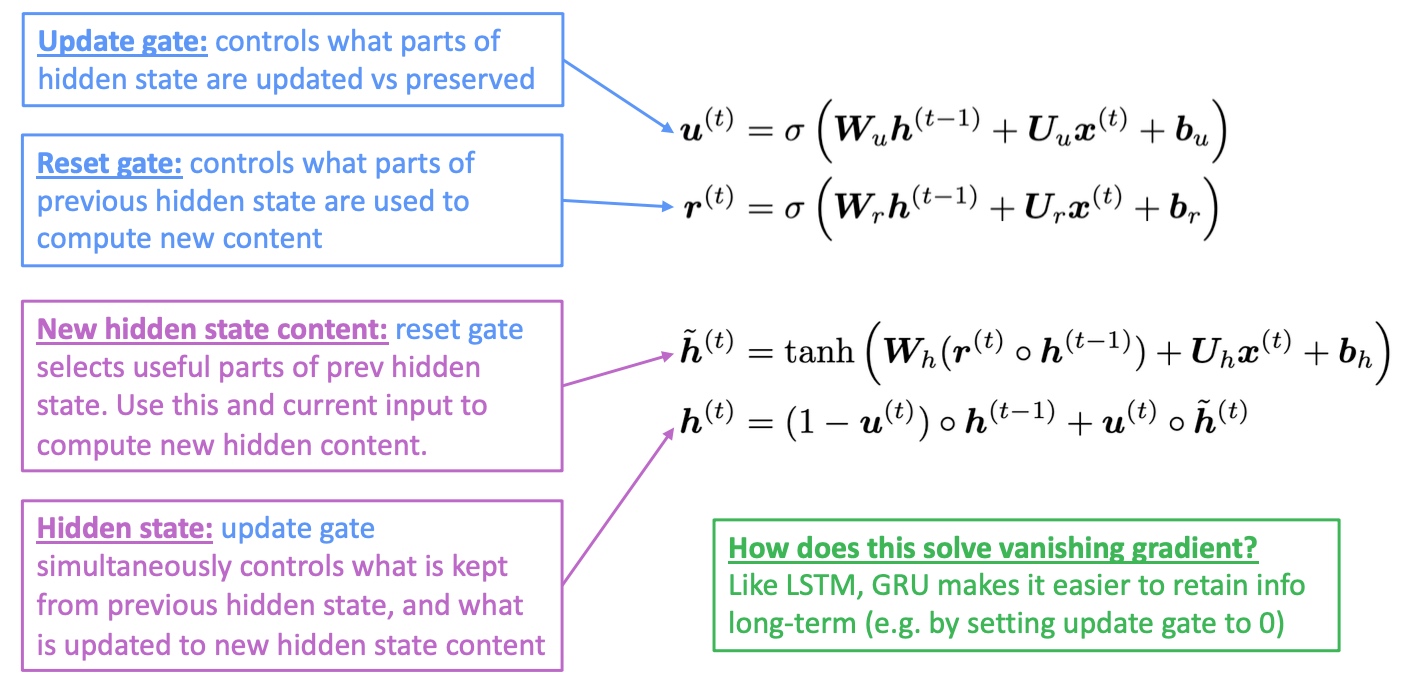
- update gate决定了前一时刻的hidden state有多少可以保留到下一时刻的hidden state
- reset gate决定了在产生新的memory
$uh_t$时前一时刻hidden state有多少贡献
虽然还存在RNN的很多其他变种,但是LSTM与GRU是最广泛应用的.
- Difference: 最大的区别就是GRU有更少的参数,更便于计算,对于模型效果方面,两者类似.
- Rule of thumb: 通常可以从LSTM开始(特别是针对那些有长依赖的数据),如果需要提升效率的话再准换成GRU.
Is vanishing/exploding gradient just a RNN problem?
实际上对于深度神经网络,尤其层数较多时,梯度消散/爆炸的问题就会出现:
- 由于链式法则以及非线性函数的选择,梯度消失问题也会出现
- 导致底层的layer学习速度很慢,只不过由于RNN中由于不断的乘以相同的权重矩阵导致其梯度消失问题更显著
对于非RNN的深度神经网络如前馈神经网络与卷积神经网络,为了解决梯度消失问题,通常可以引入更直接的联结(add more direct connections)使得梯度更容易传递:
- 使用ResNet(Residual connections/Skip connections), 通过引入与前层输入一样的联结(The identity connection preserves information by default)使得信息更有效的流动,这能够训练更深层的模型.
- 使用DenseNet(Dense connections), 可以将几层之间全部建立直接联结,形成dense connection.
- 使用HighwayNet(Highway connections), 与ResNet类似, 但是通过动态的gate(dynamic gate)来控制identity connection和transformation layer
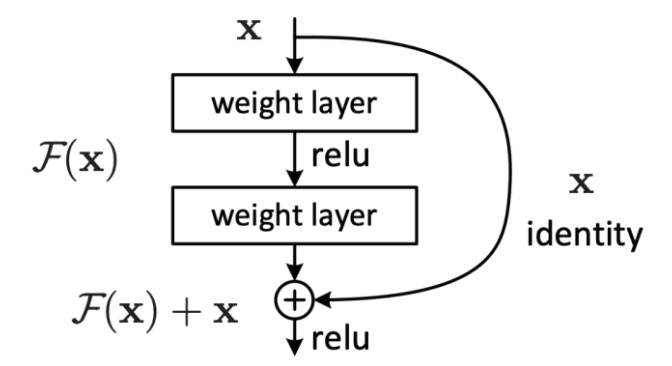
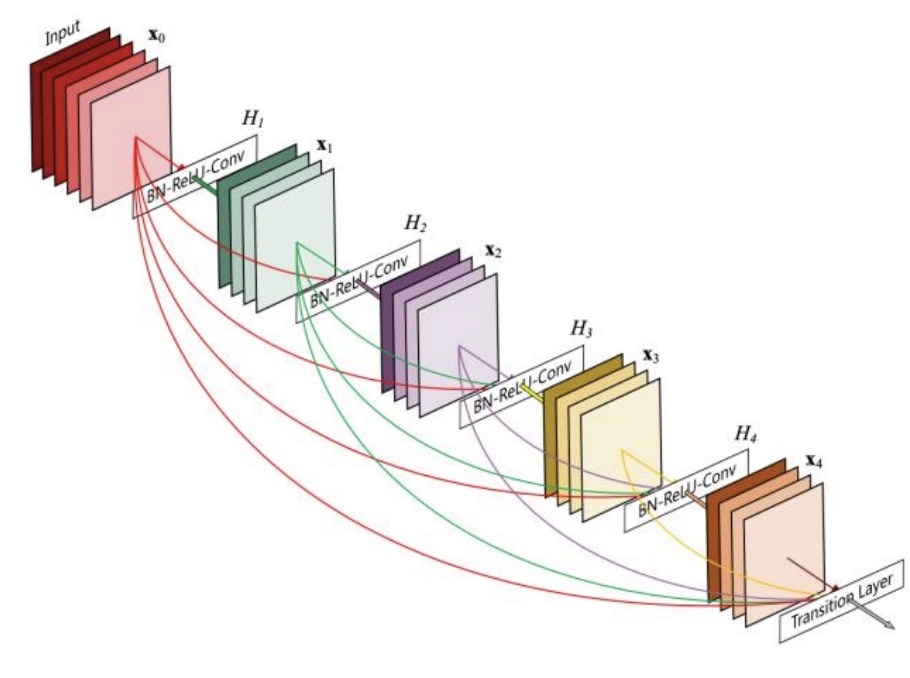
RNN使用同一個權重矩陣是导致它不稳定(梯度爆炸/消散)的主要原因
Bidirectional RNNs & Multi-layer RNNs
Bidirectional RNNs:
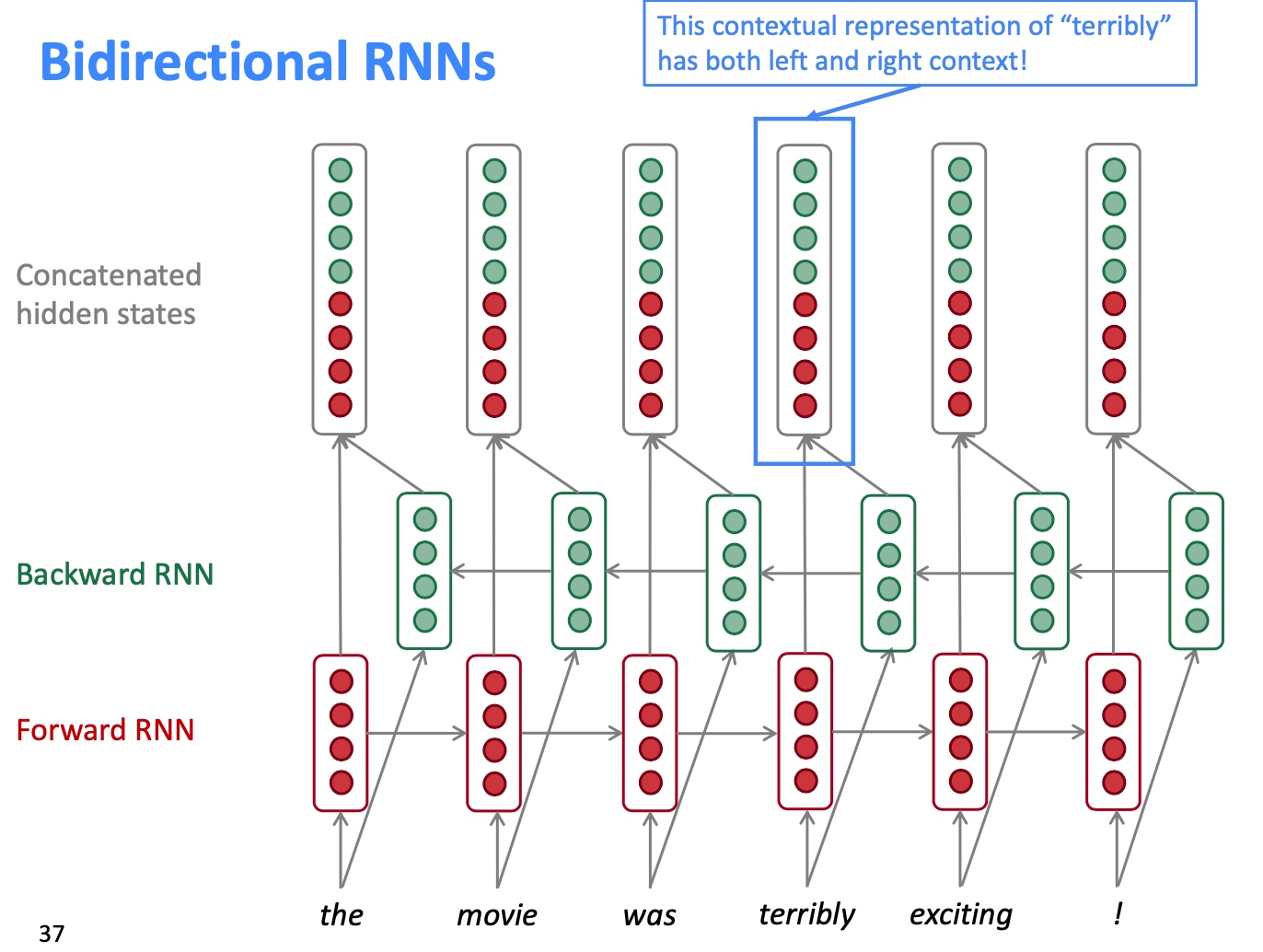
- bidirectional RNNs are only applicable if you have access to the entire input sequence (它不适用于Language Model, 因为LM只需要左边的context)
- BERT (Bidirectional Encoder Representations from Transformers) is a powerful pretrained contextual representation system built on bidirectionality
Multi-layer RNNs (stacked RNNs):
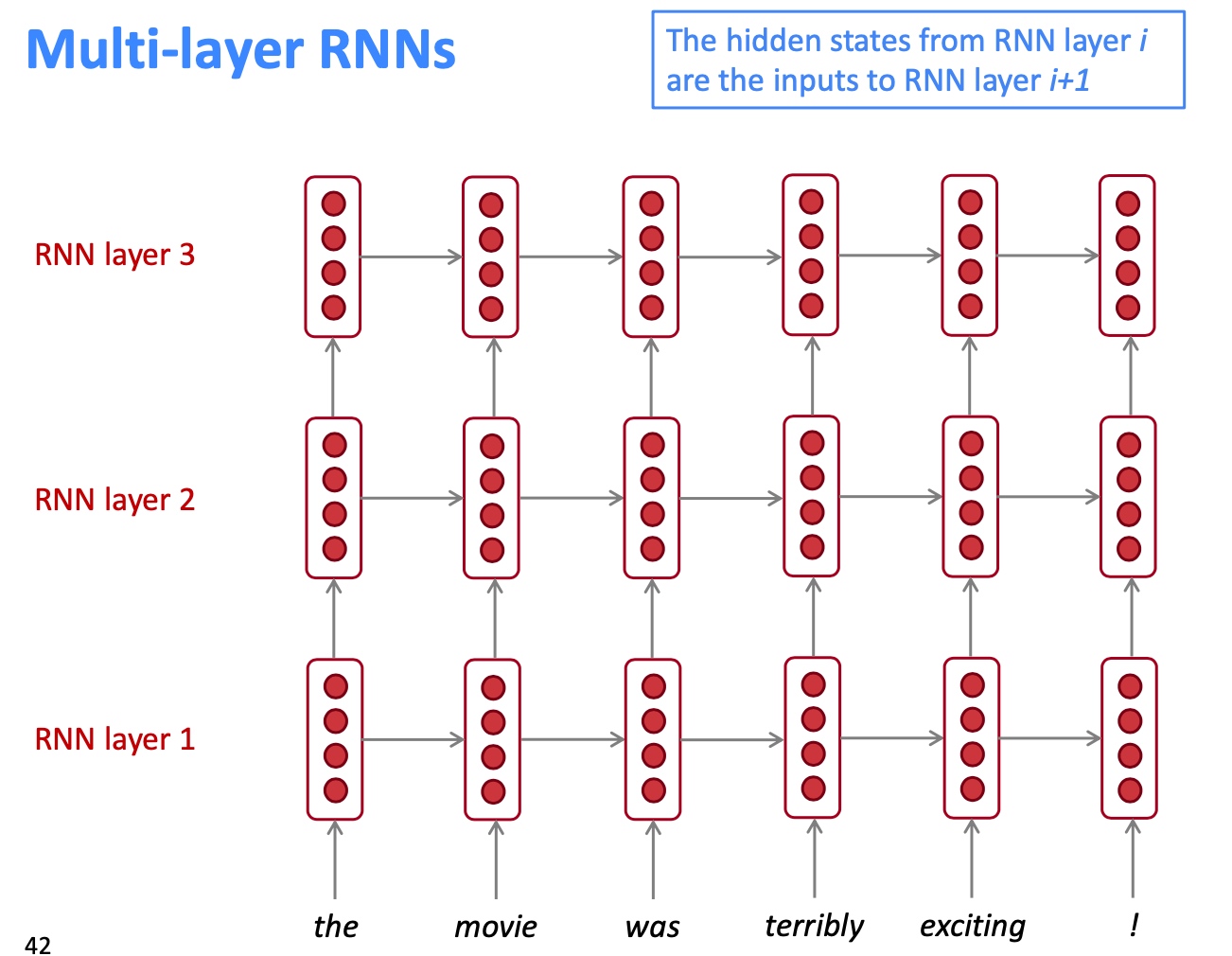
- This allows the network to compute more complex representations
- The lower RNNs should compute lower-level features and the higher RNNs should compute higher-level features
- High-performing RNNs are often multi-layer
- Neural Machine Translation, 2 to 4 layers is best for the encoder RNN, and 4 layers is best for the decoder RNN
- However,skip-connections/dense-connectionsareneededtotrain deeper RNNs (e.g. 8 layers)
- Transformer-based networks (e.g. BERT) are frequently deeper, like 12 or 24 layers