BERT (Word Embeddings)
How BERT works
BERT makes use of Transformer, an attention mechanism that learns contextual relations between words (or sub-words) in a text. In its vanilla form, Transformer includes two separate mechanisms — an encoder that reads the text input and a decoder that produces a prediction for the task. Since BERT’s goal is to generate a language model, only the encoder mechanism is necessary.
As opposed to directional models, which read the text input sequentially (left-to-right or right-to-left), the Transformer encoder reads the entire sequence of words at once. Therefore it is considered bidirectional, though it would be more accurate to say that it’s non-directional. This characteristic allows the model to learn the context of a word based on all of its surroundings (left and right of the word).
Bert + SQuAD
In Question Answering tasks (e.g. SQuAD v1.1), the software receives a question regarding a text sequence and is required to mark the answer in the sequence. Using BERT, a Q&A model can be trained by learning two extra vectors that mark the beginning and the end of the answer.
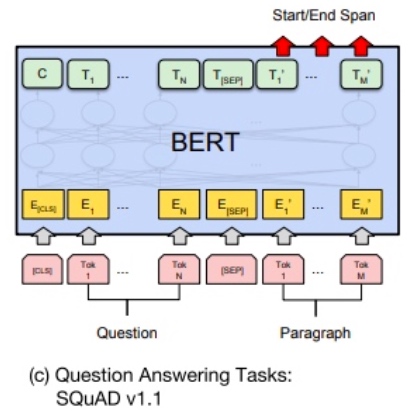 SQuAD v1.1:给定一个句子(通常是一个问题)和一段描述文本, 输出这个问题的答案, 类似于做阅读理解的简答题. 如图©表示的, SQuAD的输入是问题和描述文本的句子对. 输出是特征向量, 通过在描述文本上接一层激活函数为softmax的全连接来获得输出文本的条件概率, 全连接的输出节点个数是语料中Token的个数.
SQuAD v1.1:给定一个句子(通常是一个问题)和一段描述文本, 输出这个问题的答案, 类似于做阅读理解的简答题. 如图©表示的, SQuAD的输入是问题和描述文本的句子对. 输出是特征向量, 通过在描述文本上接一层激活函数为softmax的全连接来获得输出文本的条件概率, 全连接的输出节点个数是语料中Token的个数.
$P_i = \frac{e^{V \cdot C_i}}{\sum^4_{j=1}e^{V \cdot C_i}}$
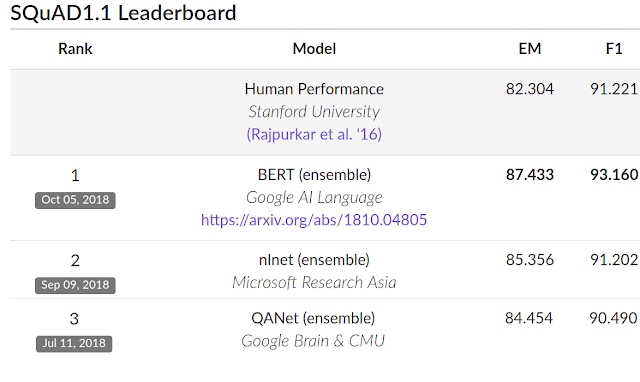
Performance
On SQuAD v1.1, BERT achieves 93.2% F1 score (a measure of accuracy), surpassing the previous state-of-the-art score of 91.6% and human-level score of 91.2%:
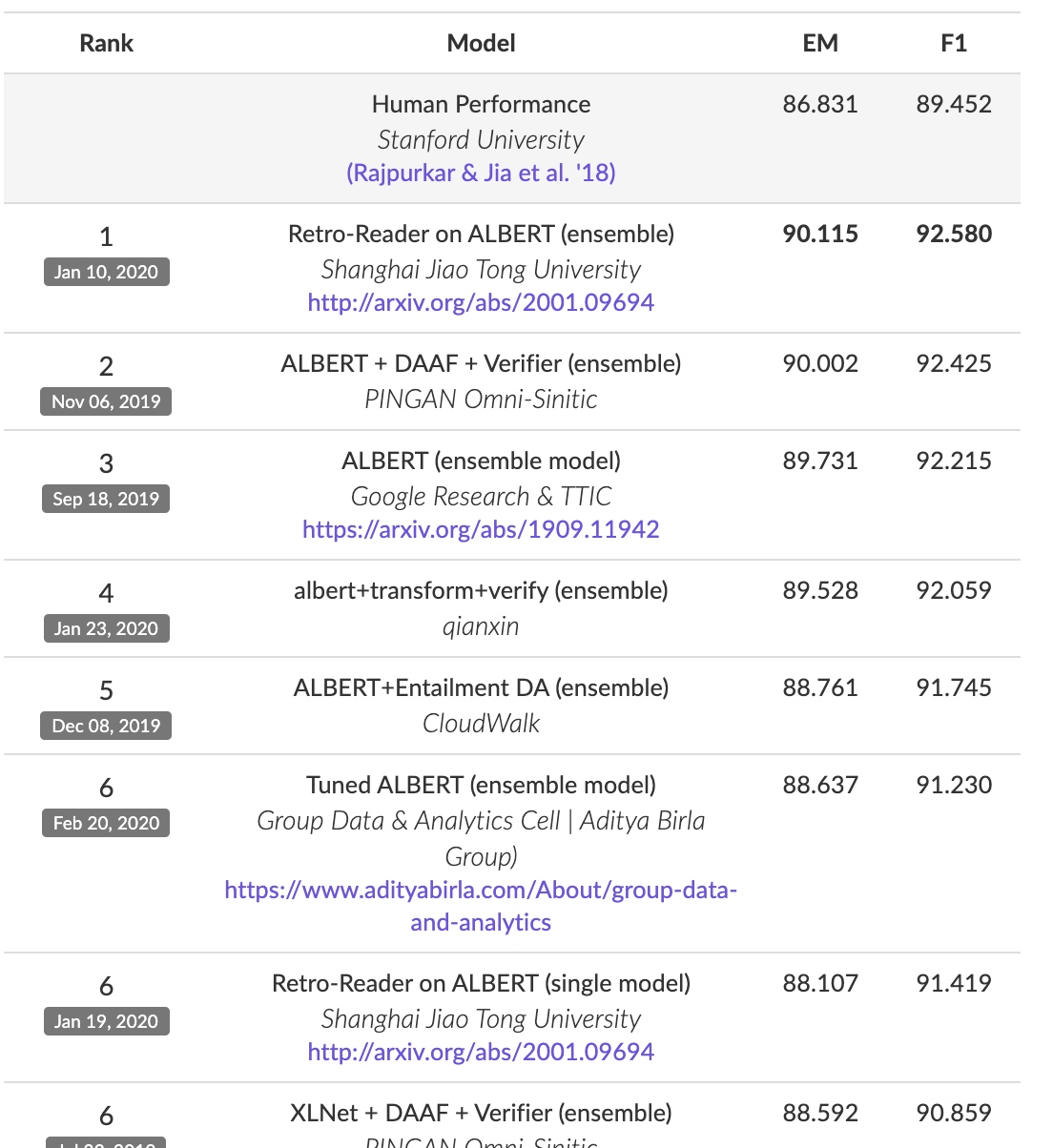
For SQuAD2.0:
Input Formatting
Because BERT is a pretrained model that expects input data in a specific format, we will need:
- special tokens to mark the beginning ([CLS]) and separation/end of sentences ([SEP])
- tokens that conforms with the fixed vocabulary used in BERT
- token IDs from BERT’s tokenizer
- mask IDs to indicate which elements in the sequence are tokens and which are padding elements
- segment IDs used to distinguish different sentences
- positional embeddings used to show token position within the sequence
Special Tokens
BERT can take as input either one or two sentences, and expects special tokens to mark the beginning and end of each one:
- 2 Sentence Input:
[CLS] The man went to the store. [SEP] He bought a gallon of milk. [SEP]
- 1 Sentence Input:
[CLS] The man went to the store. [SEP]
Tokenization
BERT provides its own tokenizer. Let’s see how it handles the below sentence.
text = "Here is the sentence I want embeddings for."
marked_text = "[CLS] " + text + " [SEP]"
# Tokenize our sentence with the BERT tokenizer.
tokenized_text = tokenizer.tokenize(marked_text)
# Print out the tokens.
print (tokenized_text)
['[CLS]', 'here', 'is', 'the', 'sentence', 'i', 'want', 'em', '##bed', '##ding', '##s', 'for', '.', '[SEP]']Notice how the word “embeddings” is represented:
['em', '##bed', '##ding', '##s']
The original word has been split into smaller subwords and characters. The two hash signs preceding some of these subwords are just our tokenizer’s way to denote that this subword or character is part of a larger word and preceded by another subword. So, for example, the ‘##bed’ token is separate from the ‘bed’ token; the first is used whenever the subword ‘bed’ occurs within a larger word and the second is used explicitly for when the standalone token ‘thing you sleep on’ occurs.
WordPiece
Why does it look this way? This is because the BERT tokenizer was created with a WordPiece model.
WordPiece原理
现在基本性能好一些的NLP模型,例如OpenAI GPT,google的BERT,在数据预处理的时候都会有WordPiece的过程.
WordPiece字面理解是把word拆成piece一片一片.
WordPiece的一种主要的实现方式叫做BPE(Byte-Pair Encoding)双字节编码.
BPE的过程可以理解为把一个单词再拆分,使得词表会变得精简,并且寓意更加清晰. 比如"loved","loving","loves"这三个单词. 其实本身的语义都是“爱”的意思,但是如果以单词为单位,那它们就算不一样的词,在英语中不同后缀的词非常的多,就会使得词表变的很大,训练速度变慢,训练的效果也不是太好。BPE算法通过训练,能够把上面的3个单词拆分成"lov","ed","ing","es"几部分,这样可以把词的本身的意思和时态分开,有效的减少了词表的数量.
This model greedily creates a fixed-size vocabulary of individual characters, subwords, and words that best fits our language data. Since the vocabulary limit size of our BERT tokenizer model is 30,000, the WordPiece model generated a vocabulary that contains all English characters plus the ~30,000 most common words and subwords found in the English language corpus the model is trained on. This vocabulary contains four things:
- Whole words
- Subwords occuring at the front of a word or in isolation (“em” as in “embeddings” is assigned the same vector as the standalone sequence of characters “em” as in “go get em” )
- Subwords not at the front of a word, which are preceded by ‘##’ to denote this case
- Individual characters
To tokenize a word under this model, the tokenizer first checks if the whole word is in the vocabulary. If not, it tries to break the word into the largest possible subwords contained in the vocabulary, and as a last resort will decompose the word into individual characters. Note that because of this, we can always represent a word as, at the very least, the collection of its individual characters.
As a result, rather than assigning out of vocabulary words to a catch-all token like ‘OOV’(Out-of-vocabulary) or ‘UNK’(Unknown), words that are not in the vocabulary are decomposed into subword and character tokens that we can then generate embeddings for.
So, rather than assigning “embeddings” and every other out of vocabulary word to an overloaded unknown vocabulary token, we split it into subword tokens [‘em’, ‘##bed’, ‘##ding’, ‘##s’] that will retain some of the contextual meaning of the original word. We can even average these subword embedding vectors to generate an approximate vector for the original word.
Here are some examples of the tokens contained in our vocabulary. Tokens beginning with two hashes are subwords or individual characters.
list(tokenizer.vocab.keys())[5000:5020]['knight',
'lap',
'survey',
'ma',
'##ow',
'noise',
'billy',
'##ium',
'shooting',
'guide',
'bedroom',
'priest',
'resistance',
'motor',
'homes',
'sounded',
'giant',
'##mer',
'150',
'scenes']After breaking the text into tokens, we then have to convert the sentence from a list of strings to a list of vocabulary indeces.
Example
From here on, we’ll use the below example sentence, which contains two instances of the word “bank” with different meanings.
# Define a new example sentence with multiple meanings of the word "bank"
text = "After stealing money from the bank vault, the bank robber was seen " \
"fishing on the Mississippi river bank."
# Add the special tokens.
marked_text = "[CLS] " + text + " [SEP]"
# Split the sentence into tokens.
tokenized_text = tokenizer.tokenize(marked_text)
# Map the token strings to their vocabulary indeces.
indexed_tokens = tokenizer.convert_tokens_to_ids(tokenized_text)
# Display the words with their indeces.
for tup in zip(tokenized_text, indexed_tokens):
print('{:<12} {:>6,}'.format(tup[0], tup[1]))[CLS] 101
after 2,044
stealing 11,065
money 2,769
from 2,013
the 1,996
bank 2,924
vault 11,632
, 1,010
the 1,996
bank 2,924
robber 27,307
was 2,001
seen 2,464
fishing 5,645
on 2,006
the 1,996
mississippi 5,900
river 2,314
bank 2,924
. 1,012
[SEP] 102Segment ID
BERT is trained on and expects sentence pairs, using 1s and 0s to distinguish between the two sentences. That is, for each token in “tokenized_text,” we must specify which sentence it belongs to: sentence 0 (a series of 0s) or sentence 1 (a series of 1s). For our purposes, single-sentence inputs only require a series of 1s, so we will create a vector of 1s for each token in our input sentence.
If you want to process two sentences, assign each word in the first sentence plus the ‘[SEP]’ token a 0, and all tokens of the second sentence a 1.
# Mark each of the 22 tokens as belonging to sentence "1".
segments_ids = [1] * len(tokenized_text)
print (segments_ids)[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]Out-of-memory issues
All experiments in the paper were fine-tuned on a Cloud TPU, which has 64GB of device RAM. Therefore, when using a GPU with 12GB - 16GB of RAM, you are likely to encounter out-of-memory issues if you use the same hyperparameters described in the paper.
The factors that affect memory usage are:
- max_seq_length: The released models were trained with sequence lengths up to 512, but you can fine-tune with a shorter max sequence length to save substantial memory. This is controlled by the max_seq_length flag in our example code.
- train_batch_size: The memory usage is also directly proportional to the batch size.
- Model type, BERT-Base vs. BERT-Large: The BERT-Large model requires significantly more memory than BERT-Base.
- Optimizer: The default optimizer for BERT is Adam, which requires a lot of extra memory to store the m and v vectors. Switching to a more memory efficient optimizer can reduce memory usage, but can also affect the results. We have not experimented with other optimizers for fine-tuning.
Using the default training scripts (run_classifier.py and run_squad.py), we benchmarked the maximum batch size on single Titan X GPU (12GB RAM) with TensorFlow 1.11.0:
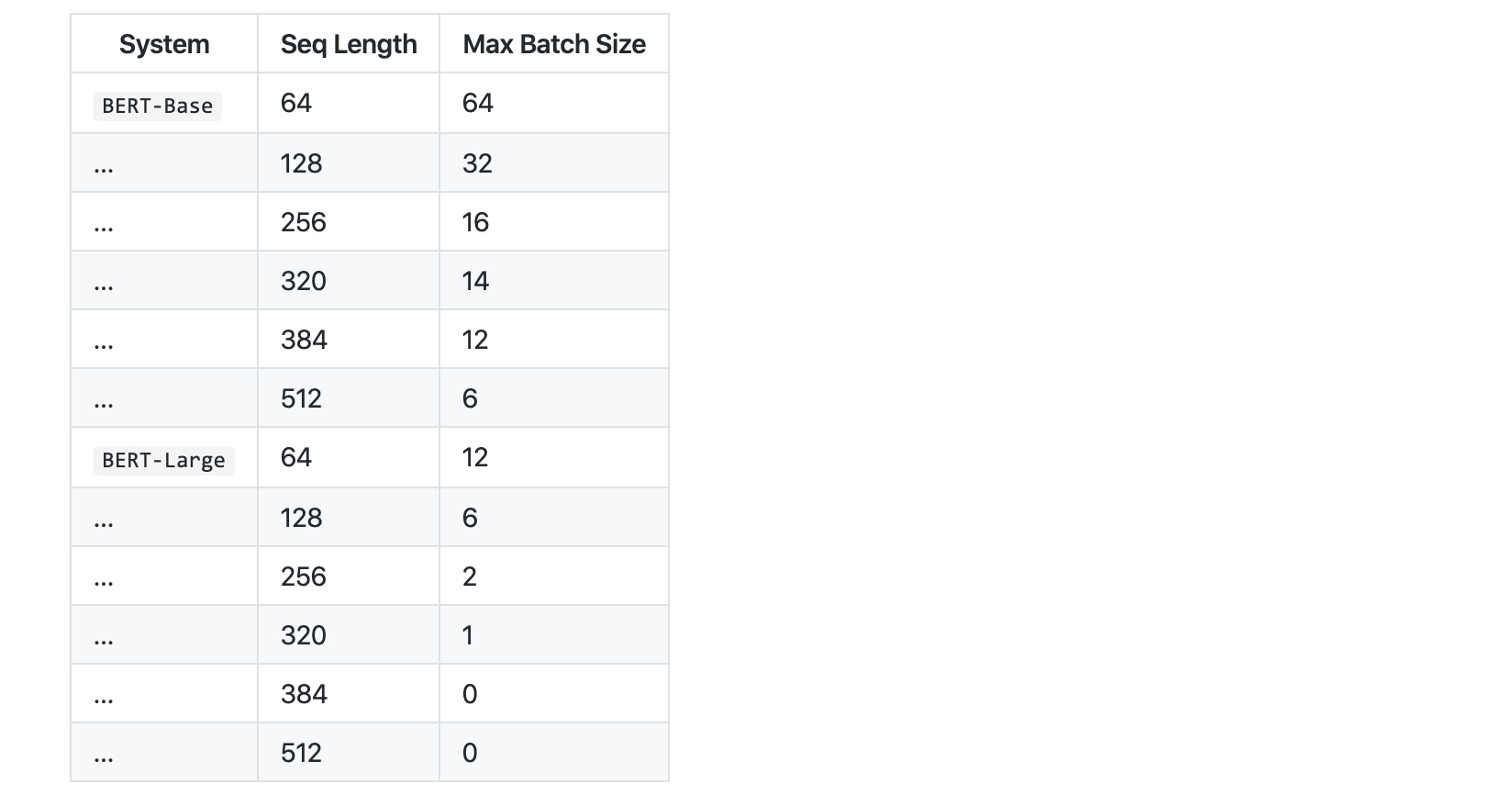
Unfortunately, these max batch sizes for BERT-Large are so small that they will actually harm the model accuracy, regardless of the learning rate used. We are working on adding code to this repository which will allow much larger effective batch sizes to be used on the GPU. The code will be based on one (or both) of the following techniques:
- Gradient accumulation: The samples in a minibatch are typically independent with respect to gradient computation (excluding batch normalization, which is not used here). This means that the gradients of multiple smaller minibatches can be accumulated before performing the weight update, and this will be exactly equivalent to a single larger update.
- Gradient checkpointing: The major use of GPU/TPU memory during DNN training is caching the intermediate activations in the forward pass that are necessary for efficient computation in the backward pass. “Gradient checkpointing” trades memory for compute time by re-computing the activations in an intelligent way.
Summary
SQuAD Example:
{
"data":[
{
"title":"Super_Bowl_50",
"paragraphs":[
{
"context":"Super Bowl 50 was an American football game to determine the champion of the National Football League (NFL) for the 2015 season. The American Football Conference (AFC) champion Denver Broncos defeated the National Football Conference (NFC) champion Carolina Panthers 24–10 to earn their third Super Bowl title. The game was played on February 7, 2016, at Levi\\'s Stadium in the San Francisco Bay Area at Santa Clara, California. As this was the 50th Super Bowl, the league emphasized the \"golden anniversary\" with various gold-themed initiatives, as well as temporarily suspending the tradition of naming each Super Bowl game with Roman numerals (under which the game would have been known as \"Super Bowl L\"), so that the logo could prominently feature the Arabic numerals 50.",
"qas":[
{
"answers":[
{
"answer_start":177,
"text":"Denver Broncos"
},
{
"answer_start":177,
"text":"Denver Broncos"
},
{
"answer_start":177,
"text":"Denver Broncos"
}
],
"question":"Which NFL team represented the AFC at Super Bowl 50?",
"id":"56be4db0acb8001400a502ec"
}
]
}
]
}
],
"version":"1.1"
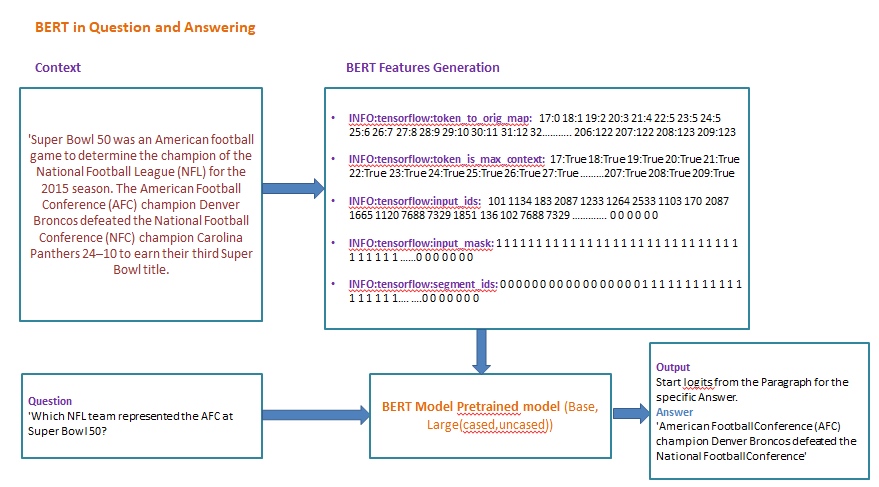
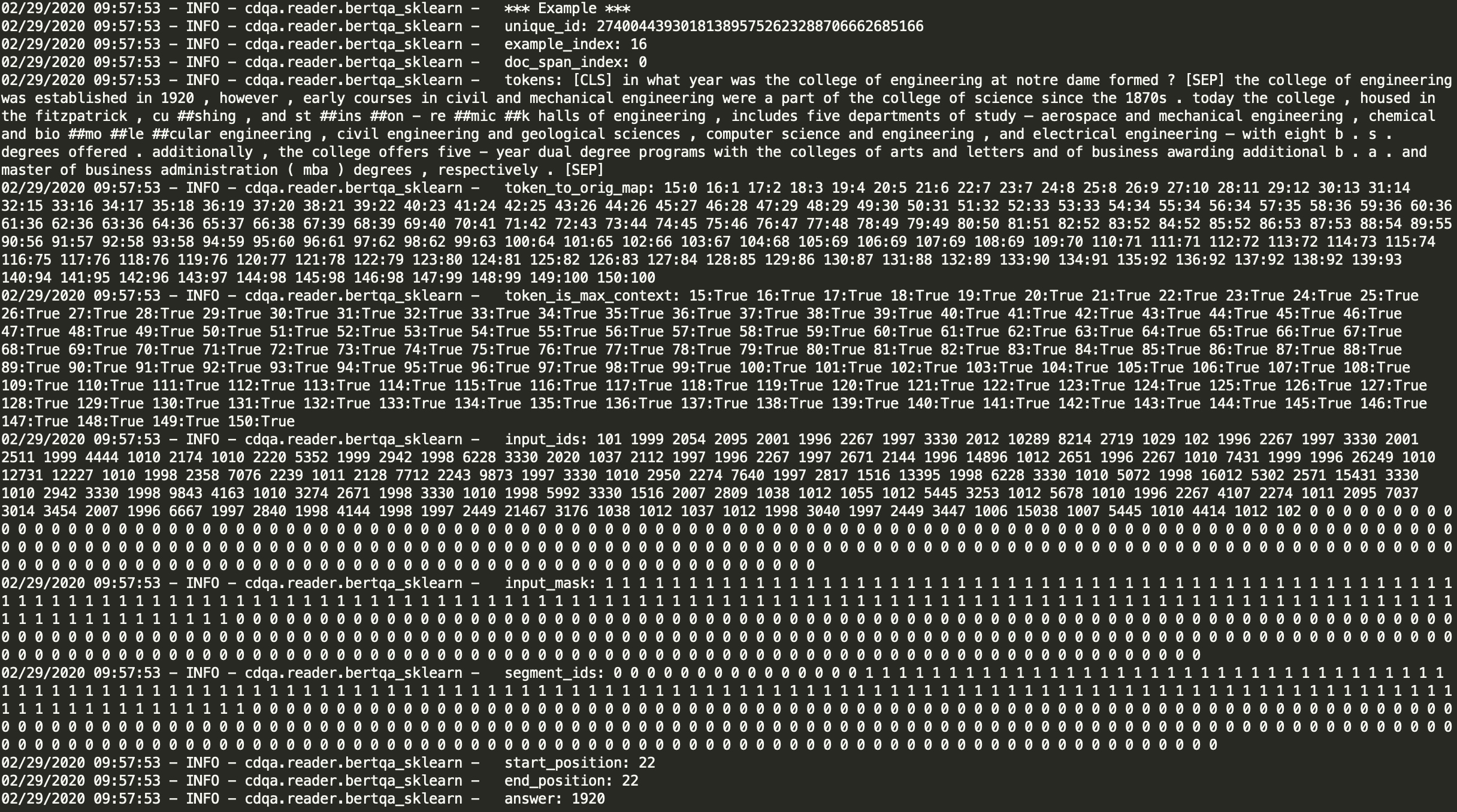
}Basic structure: [CLS]+query tokens+[SEP]+context tokens+[SEP]
- token_to_orig_map : Considering the index of each word as a feature integer
INFO:tensorflow:token_to_orig_map: 17:0 18:1 19:2 20:3 21:4 22:5 23:5 24:5 25:6 26:7 27:8 28:9 29:10 30:11 31:12 32:13 33:14 34:15 35:16 36:17 37:17 38:17 39:17 ...............................196:115 197:116 198:117 199:118 200:119 201:120 202:121 203:121 204:121 205:122 206:122 207:122 208:123 209:123- 17 represents that the context tokens starts at 17th (before that, are [CLS]+query tokens+[SEP] - 0 represents the first word, 1 represents the second word…
- token_is_max_context : A Boolean index to each word representing whether the word is important in the context or not.
INFO:tensorflow:token_is_max_context: 17:True 18:True 19:True 20:True 21:True 22:True 23:True 24:True 25:True 26:True 27:True 28:True 29:True 30:True 31:True 32:True ...........................202:True 203:True 204:True 205:True 206:True 207:True 208:True 209:True- Boolean值表示该位置的token在当前span里面是否是最全上下文的 - E.g.Doc: the man went to the store and bought a gallon of milk | Span A: the man went to the | Span B: to the store and bought | Span C: and bought a gallon ofbought在spanB和spanC里都有出现,但很显然span C里bought是语境最全的,既有上文也有下文
- input_ids : Assigning word to vector ids to each word of context by considering the words dictionary data from pretrained BERT.
INFO:tensorflow:input_ids: 101 1134 183 2087 1233 1264 2533 1103 170 2087 1665 1120 7688 7329 1851 136 102 7688 7329 1851 1108 1126 1821 26237 1389 1709 1342 1106 4959 1103 3628 1104 1103 1569 1709 2074 113 183 2087 1233 114 1111 ............................ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
- input_mask : Boolean mask to the context words based on their presence and followed by zero padding to meet the max word vector representation used for specific downloaded BERT model.
INFO:tensorflow:input_mask: 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 ............... 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
- segment_ids : segment ids to indicate whether a token belongs to the first sequence or the second sequence
INFO:tensorflow:segment_ids: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 .............0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0