Transfer Learning in NLP
1. 简介
预训练的语言表征经过精调后可以在众多NLP任务中达到更好的表现. 目前预训练有两种方法:
- Feature-based:将训练出的representation作为feature用于任务,从词向量、句向量、段向量、文本向量都是这样的.
- ELMo属于这类,但迁移后需要重新计算出输入的表征
- Fine-tuning:这个主要借鉴于CV(Computer Vision), 就是在预训练好的模型上加些针对任务的层,再对后几层进行精调
- ULMFit和OpenAI GPT属于这一类
2. ELMo

Let's stick to improvisation is this skit. ‘stick’这样的词其实有很多意思,具体是什么意思取决于在什么语境中用它.
ELMo就是基于其上下文语境来学习一个词的嵌入表示, 它就是一个语境化的词嵌入模型.
模型原理与架构
ELMo不是对每个单词使用固定嵌入,而是在为其中的每个单词分配嵌入之前查看整个句子,它使用在特定任务上训练的双向LSTM来创建这些嵌入
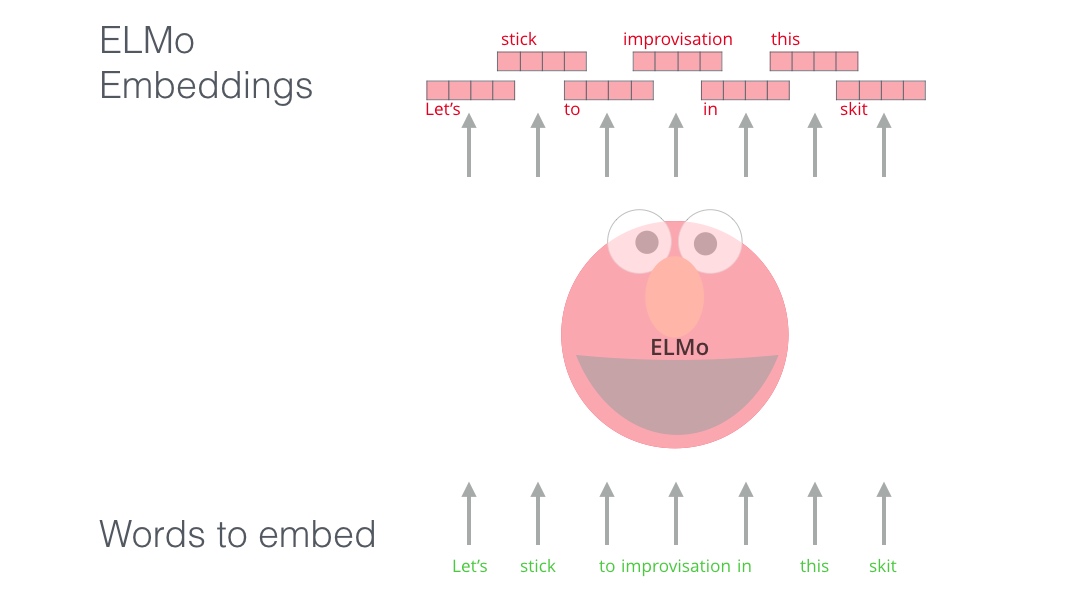 ELMo为解决NLP的语境问题作出了重要的贡献,它的LSTM可以使用与我们任务相关的大量文本数据来进行训练,然后将训练好的模型用作其他NLP任务的词向量的基准.
ELMo为解决NLP的语境问题作出了重要的贡献,它的LSTM可以使用与我们任务相关的大量文本数据来进行训练,然后将训练好的模型用作其他NLP任务的词向量的基准.
ELMo会训练一个模型,这个模型接受一个句子或者单词的输入,输出最有可能出现在后面的一个单词 (类似输入法). 这个在NLP中称作Language Modeling. 这样的模型很容易实现,因为拥有大量的文本数据且可以在不需要标签的情况下去学习
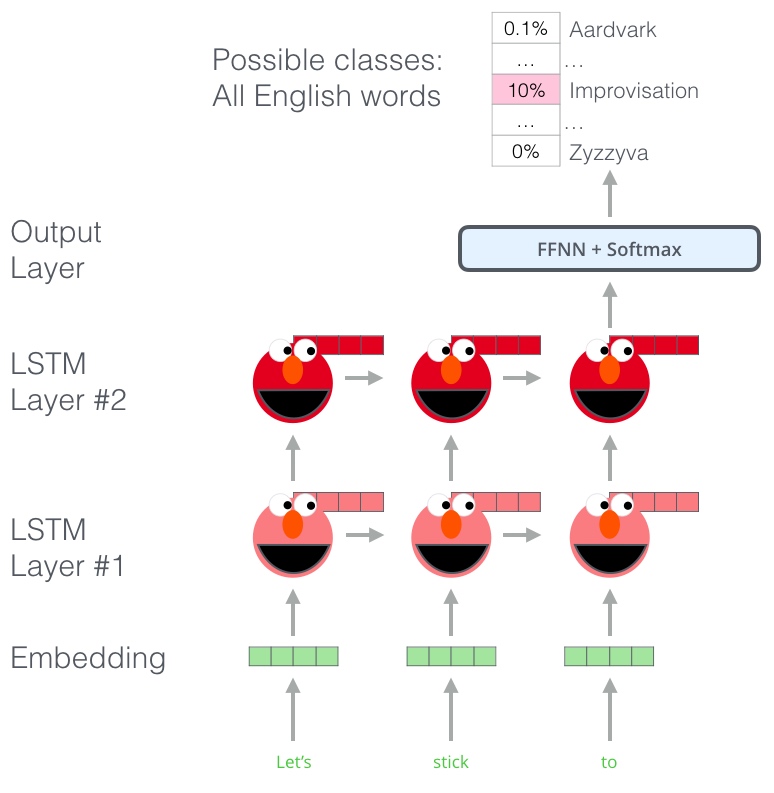 ELMo进行预训练的一个步骤:给定输入“Let’s stick to”, 预测接下来一个词,这就是语言模型(LM)的任务. 当模型在大语料上进行预训练,他就会学习其中的语言模式. 它不太可能准确地直接地猜出这个例子中的下一个单词. 更实际一点说,在“hang”这样的单词之后,它将为“out”这样的单词分配更高的概率(组成 “hang out”) 而不是给“camera”分配更高的概率
ELMo进行预训练的一个步骤:给定输入“Let’s stick to”, 预测接下来一个词,这就是语言模型(LM)的任务. 当模型在大语料上进行预训练,他就会学习其中的语言模式. 它不太可能准确地直接地猜出这个例子中的下一个单词. 更实际一点说,在“hang”这样的单词之后,它将为“out”这样的单词分配更高的概率(组成 “hang out”) 而不是给“camera”分配更高的概率
从上图可以发现,每个展开的LSTM都在最后一步完成预测.
ELMo实际上更进一步, 训练了一个双向的LSTM——这样它的语言模型不仅能预测下一个词,还有预测上一个词
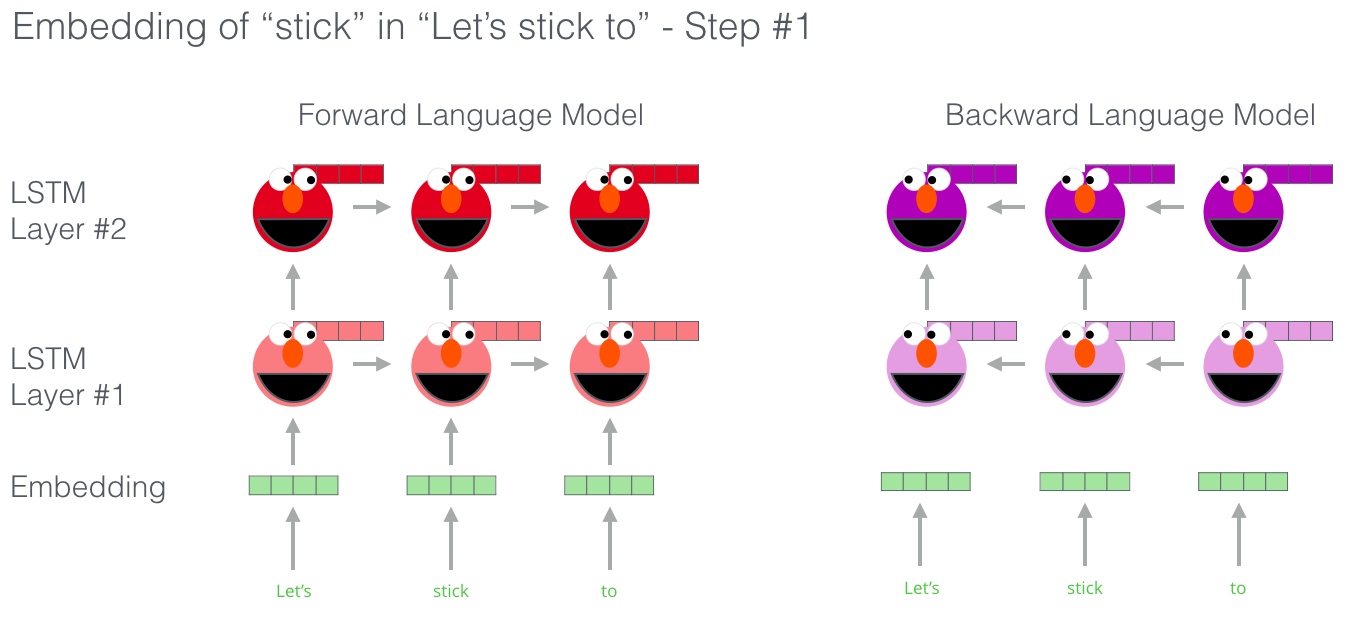
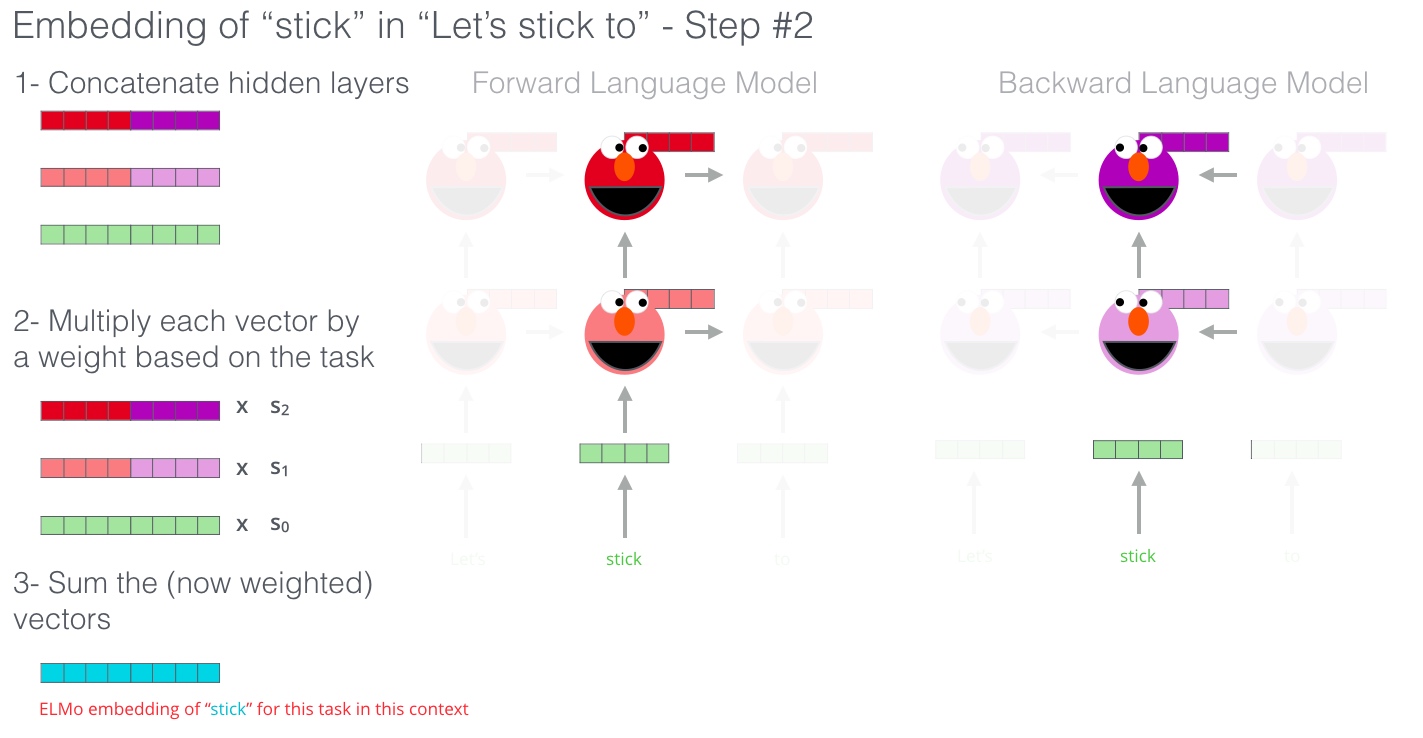
ELMo通过以某种方式将隐藏状态(和初始嵌入)组合在一起来提出情境化嵌入(连接后加权求和)
ELMo不仅去学习单词特征,还有句法特征与语义特征. 后两者的特征是来自LSTM的隐含输出向量. 这里的模型目标是预测对应位置的下一个单词(也就是T1的向量应该预测出E2的单词)
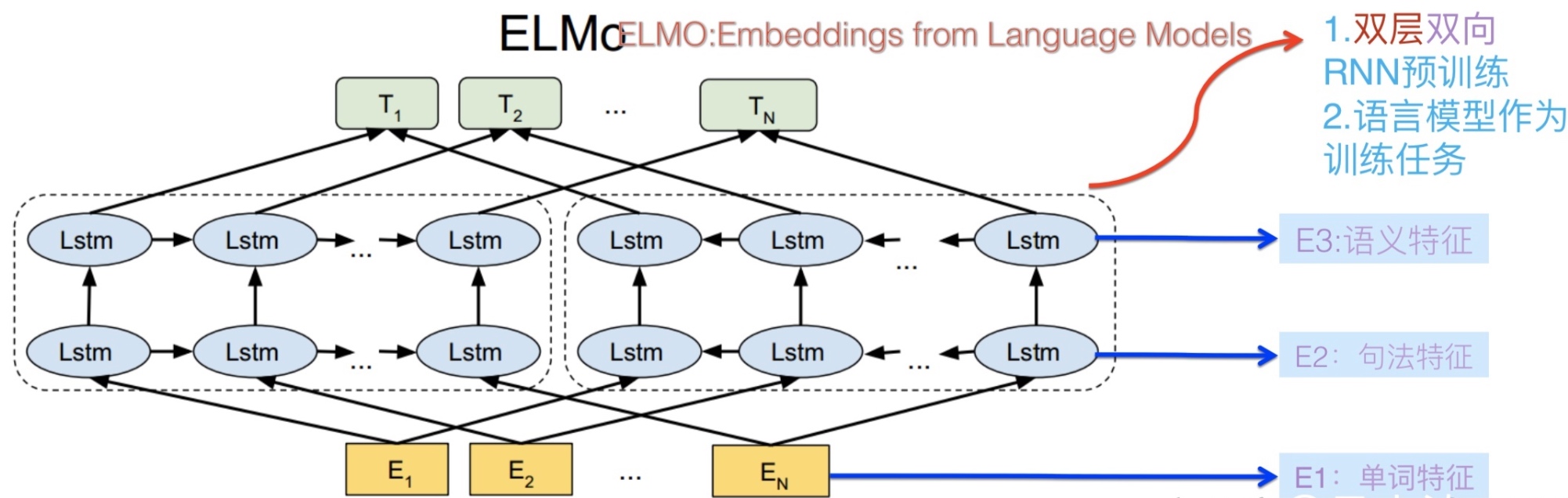 模型训练完,就可以得到单词,句法以及语义特征. 也就是在一个句子中每一个单词将会对应三个向量,然后三者共同构建成下游任务的输入. 比如下游任务就是一个对话系统,整个流程如下图所示
模型训练完,就可以得到单词,句法以及语义特征. 也就是在一个句子中每一个单词将会对应三个向量,然后三者共同构建成下游任务的输入. 比如下游任务就是一个对话系统,整个流程如下图所示
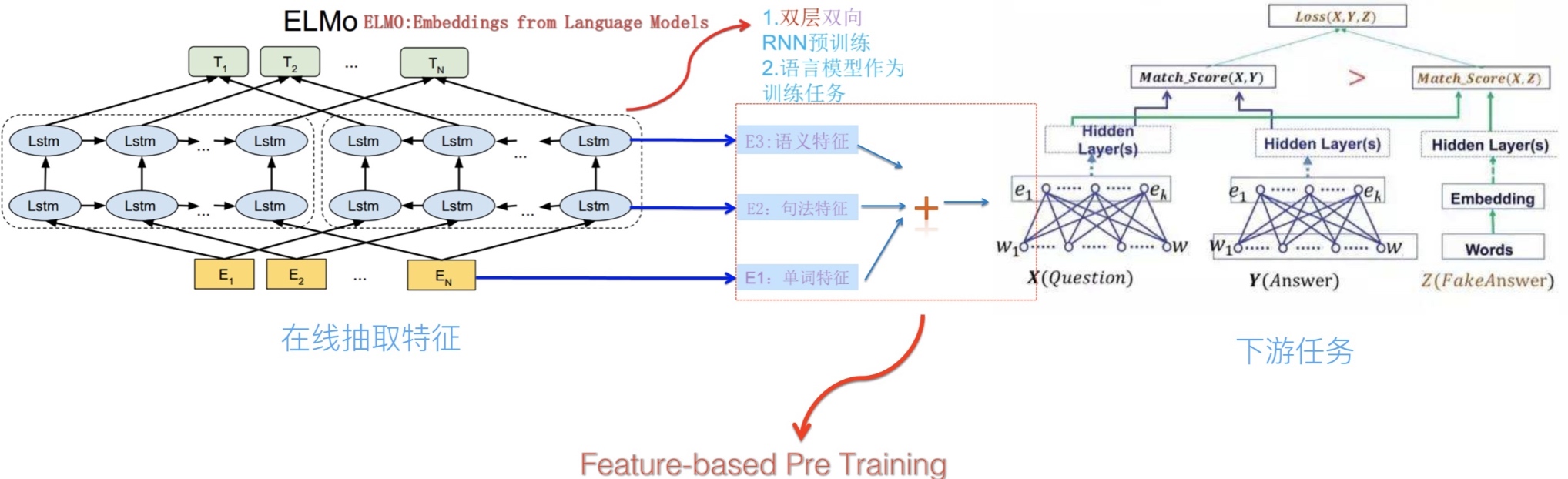 总结就是ELMo模型是通过语言模型任务得到句子中的单词的向量,这个向量是结合左向右向的信息,但是仅仅是拼接的实现.
总结就是ELMo模型是通过语言模型任务得到句子中的单词的向量,这个向量是结合左向右向的信息,但是仅仅是拼接的实现.
模型的优缺点
优点:
- 效果好,在大部分任务上都较传统模型有提升. 实验正式ELMo相比于词向量,可以更好地捕捉到语法和语义层面的信息
- 传统的预训练词向量只能提供一层表征,而且词汇量受到限制. ELMo所提供的是character-level的表征,对词汇量没有限制
缺点:
- 速度较慢,对每个token编码都要通过language model计算得出
适用任务
- Question Answering
- Textual entailment
- Semantic role labeling
- Coreference resolution
- Named entity extraction
- Sentiment analysis
3. ULM-FiT
模型原理与架构
ULM-FiT机制让模型的预训练参数得到更好的利用. 所利用的参数不仅限于embeddings,也不仅限于语境embedding,ULM-FiT引入了Language Model和一个有效微调该Language Model来执行各种NLP任务的流程. 这使得NLP任务也能像计算机视觉一样方便的使用迁移学习.
ULMFiT的过程分为三步:
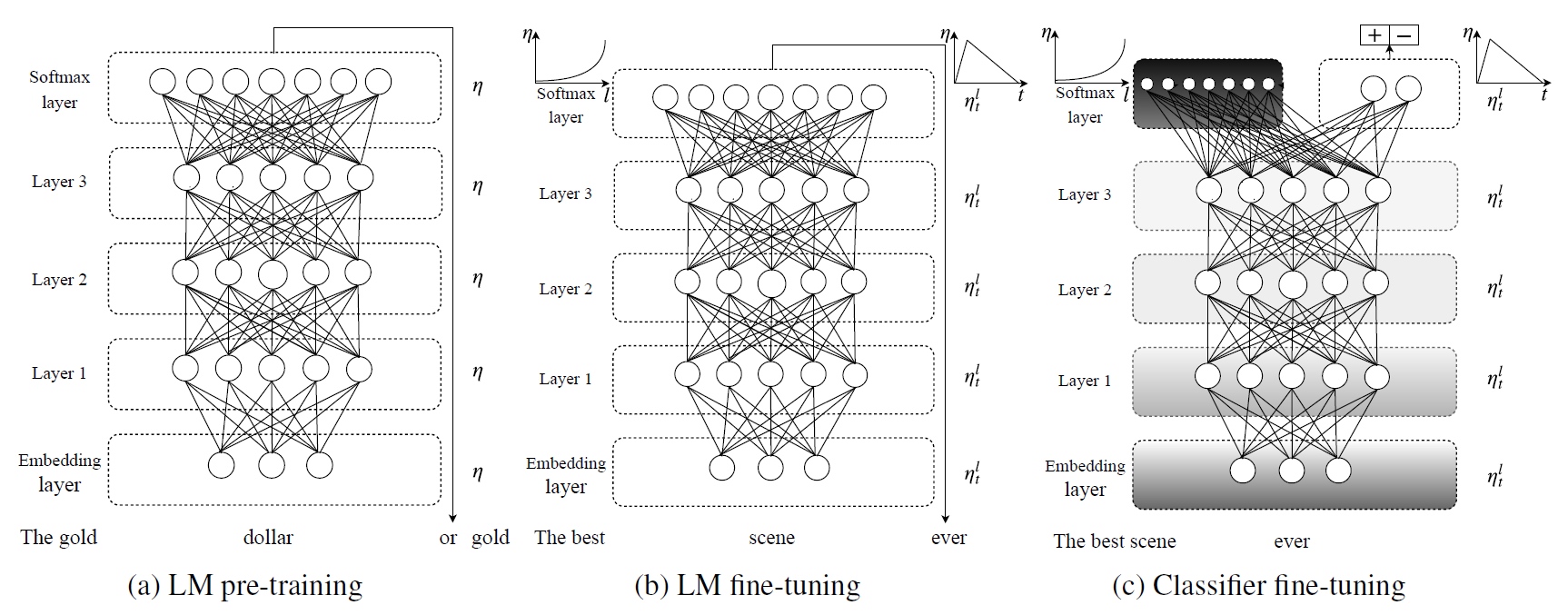
- General-domain LM pre-train
- 在Wikitext-103上进行语言模型的预训练
- 预训练的语料要求:large & capture general properties of language
- 预训练对小数据集十分有效,之后仅有少量样本就可以使模型泛化
Target task LM fine-tuning
- 文中介绍了两种fine-tuning方法:

- 文中介绍了两种fine-tuning方法:
Target task classifier fine-tuning
为了完成分类任务的精调,作者在最后一层添加了两个线性block,每个都有batch-norm和dropout,使用ReLU作为中间层激活函数,最后经过softmax输出分类的概率分布. 最后的精调涉及的环节如下:
- Concat pooling
- 第一个线性层的输入是最后一个隐层状态的池化. 因为文本分类的关键信息可能在文本的任何地方,所以只是用最后时间步的输出是不够的. 作者将最后时间步 $h_T$ 与尽可能多的时间步 $H=h_1,…,h_T$ 池化后拼接起来,以 $h_c = [h_T, maxpool(H),meanpool(H)]$ 作为输入.
- Gradual unfreezing
- 由于过度精调会导致模型遗忘之前预训练得到的信息,作者提出逐渐unfreez网络层的方法,从最后一层开始unfreez和精调,由后向前地unfreez并精调所有层.
- BPTT for Text Classification (BPT3C)
- 为了在large documents上进行模型精调,作者将文档分为固定长度为b的batches,并在每个batch训练时记录mean和max池化,梯度会被反向传播到对最终预测有贡献的batches.
- Bidirectional language model
- 在作者的实验中,分别独立地对前向和后向LM做了精调,并将两者的预测结果平均. 两者结合后结果有0.5-0.7的提升
模型的优缺点
优点:
- 对比其他迁移学习方法(ELMo)更适合以下任务:
- 非英语语言,有标签训练数据很少
- 没有state-of-the-art模型的新NLP任务
- 只有部分有标签数据的任务
缺点:
- 对于分类和序列标注任务比较容易迁移,对于复杂任务(问答等)需要新的精调方法
适用任务
- Classification
- Sequence labeling
4. OpenAI GPT
模型原理与架构
OpenAI Generative Pre-Training Transformer是一类可迁移到多种NLP任务的,基于Transformer的语言模型. 它的基本思想同ULMFiT相同,都是在尽量不改变模型结构的情况下将预训练的语言模型应用到各种任务. 不同的是,OpenAI Transformer主张用Transformer结构,而ULMFiT中使用的是基于RNN的语言模型. 文中所用的网络结构如下:
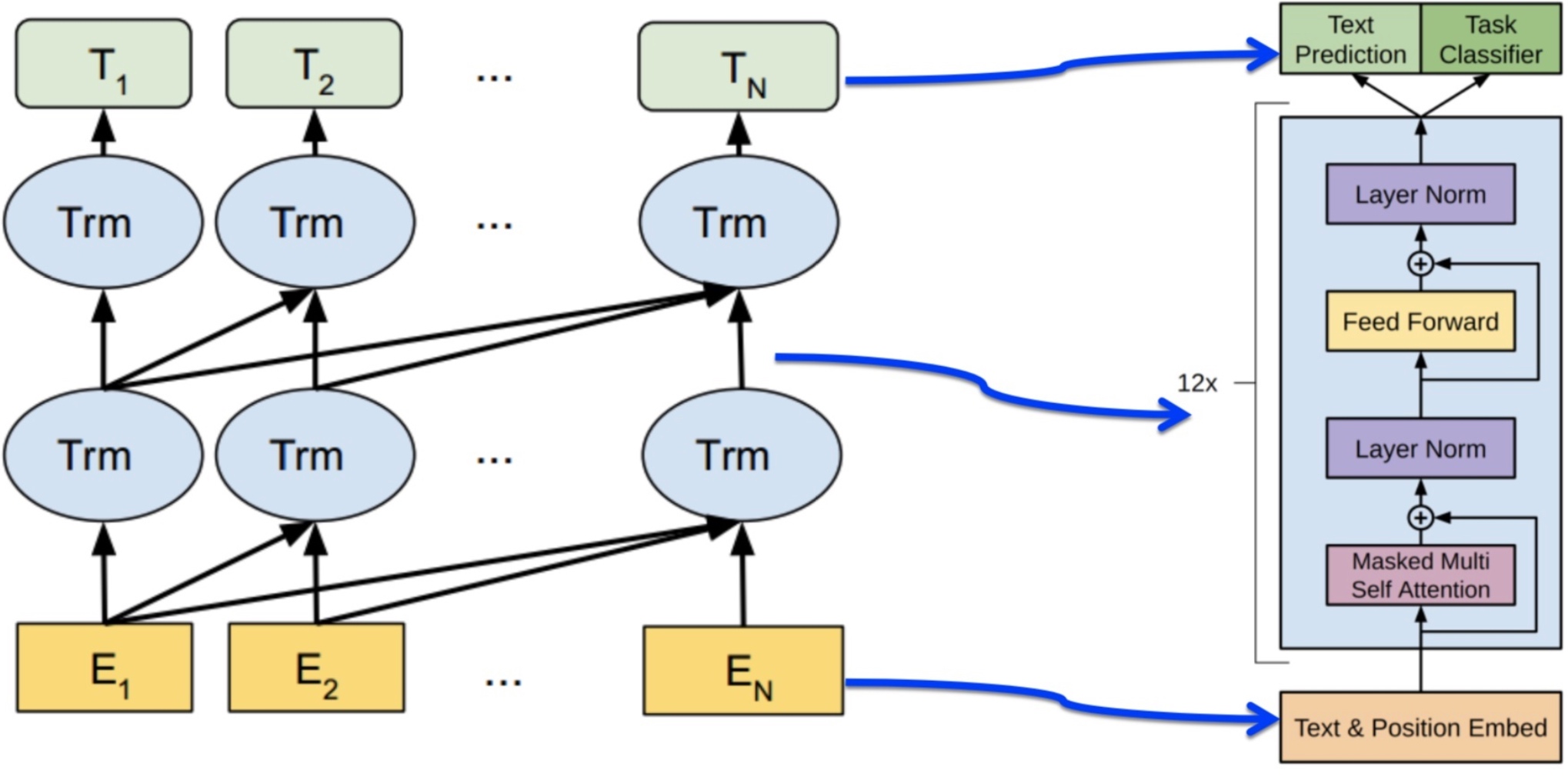 (需要注意的是这里的transformer只有encode部分)
(需要注意的是这里的transformer只有encode部分)
得到预训练的模型,然后在这样的模型后面再次接上下游任务. 与ELMo只提供向量不同,这里预训练的模型一同提供给下游的任务. 这里模型的向量是可以随着新的下游任务发生微小的调整,也就是fine-tune:
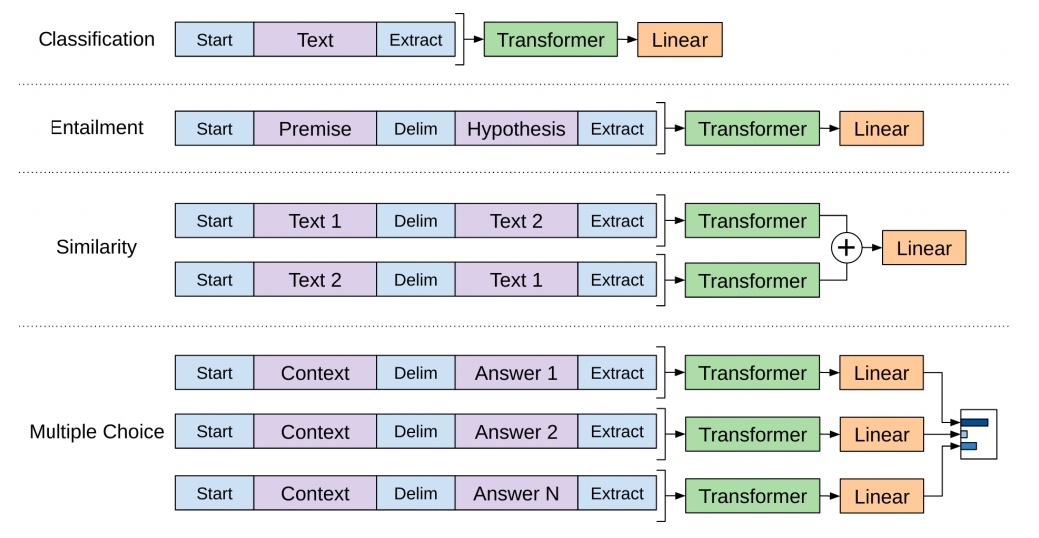
其实GPT的工作已经相当的成熟,与bert相比,区别并不是很大.
模型的优缺点
优点:
- 循环神经网络所捕捉到的信息较少,而Transformer可以捕捉到更长范围的信息
- 计算速度比循环神经网络更快,易于并行化
- 实验结果显示Transformer的效果比ELMo和LSTM网络更好
缺点:
- 对于某些类型的任务需要对输入数据的结构作调整
适用任务
- Natural Language Inference
- Question Answering and commonsense reasoning
- Classification
- Semantic Similarity
5. BERT
6. Reference
https://zhuanlan.zhihu.com/p/42618178
[ELMo]Deep contextualized word representations
- https://arxiv.org/abs/1802.05365
- https://zhuanlan.zhihu.com/p/76714382
- https://jalammar.github.io/illustrated-bert/
[ULM-FiT]Universal Language Model Fine-tuning for Text Classification
[GPT]Improving Language Understanding by Generative Pre-Training