Scikit-learn Preprocessing 预处理: 主要包括标准化、数据最大最小缩放处理、正则化、特征二值化和数据缺失值处理
http://www.atyun.com/14092.html
联邦学习 (federated learning)
一句话说明: state-of-the-art machine learning without centralizing data, and with privacy by default. (by Google)
数据不需要離開原有的环境, 各自在自己的环境訓練模型,並且通過特定的加密的機制在雲上建立一個共有的模型與進行模型的更新,用以改善模型的品質,透過這樣子的聯盟式學習的概念所有的訓練數據都仍然保留在原本的环境上
假設有不同的企業 A、B 與 C,這些企業都有相同的特徵(feature) 與不同的客戶(sample),根據隱私權的相關法規是不能將雙方的數據加以合併,因為他們各自的客戶並沒有同意授權讓這些企業這樣做,在這樣數據不充分的狀態下其實是很難建立一個效果好的模型
而聯盟式學習的目的,就是希望做到各個企業的自有的數據不出自己的公司, 各自訓練模型,然后通過加密的機制建立一個共有的模型與進行模型的更新,這不僅保護了隱私,還降低大量數據集中傳輸的成本
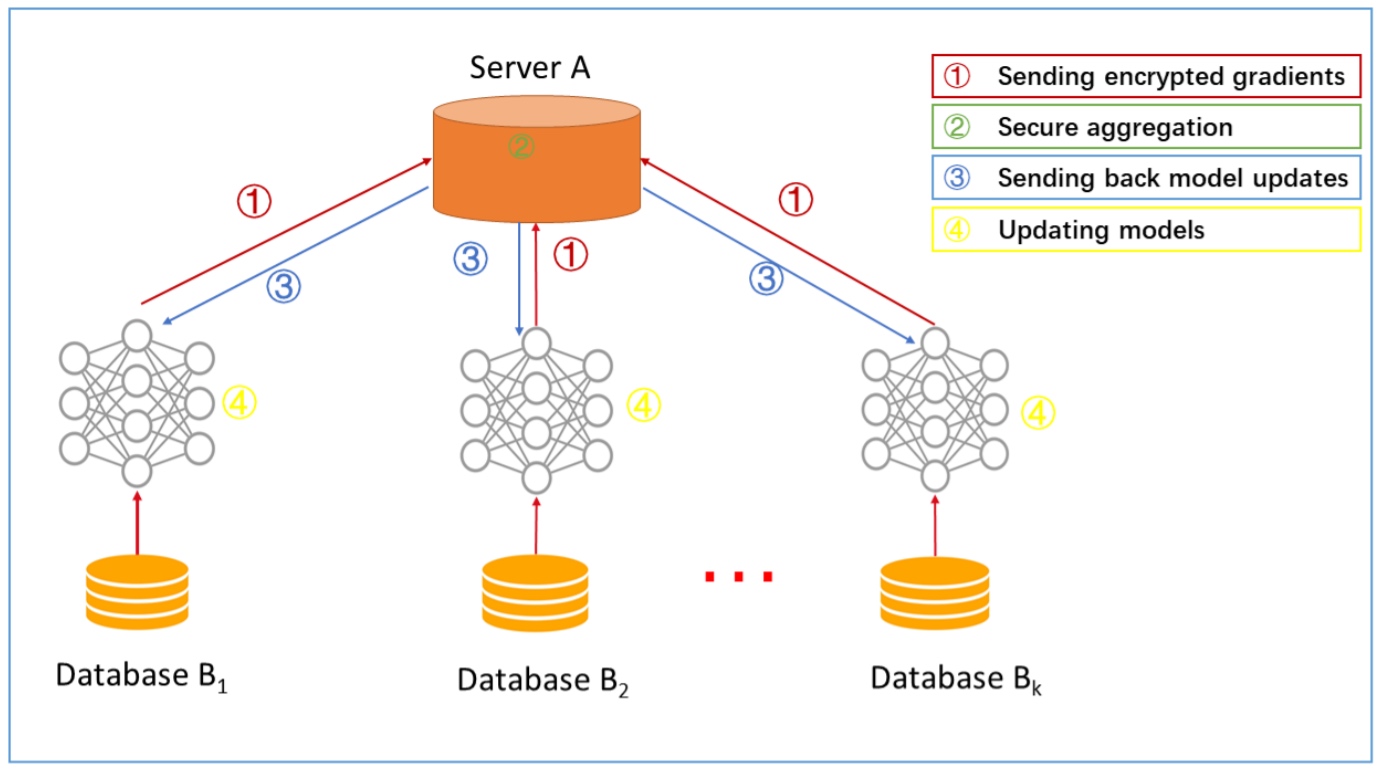
- 每個參與端(Data owner - 企業或設備用戶)利用自己的資料訓練模型,各自計算梯度,再將加密過的梯度修正量上傳至 Sever
- 由 Sever 整合各參與端(Data owner)的梯度並且更新模型
- Sever 回傳模型更新後的梯度給各個參與端(Data owner)
- 參與端(Data owner)更新各自的模型
梯度: 梯度是一个与函数相切的向量,指向此函数最大增量的方向. 函数在局部最大值或最小值处梯度为零. 在数学中,梯度被定义为函数的偏导数 梯度下降: 由于梯度是指向函数最大增量的向量,因此负梯度是指向函数最大减量的向量. 因此,梯度下降就是通过在负梯度方向上迭代来最小化损失函数 在机器学习中我们更关注目标函数和参数之间的关系,机器学习模型使用梯度下降的核心思想就是迭代调整参数以便最小化成本函数 常用的梯度下降算法包括批量梯度下降(batch gradient descent),小批量梯度下降(mini-batch gradient descent)和随机梯度下降(stochastic gradient descent) https://www.cnblogs.com/wangguchangqing/p/10521330.html
联邦學習與分散式機器學習的比較:
| Item | Federated Learning | Distributed ML |
|---|---|---|
| Nodes | Data Owners | Data Shards |
| Learning Processing | Data oweners can decide when . how to join learning | Central nodes always take control |
| Note | Privavy protection |
最大的差別在於它的每個結點(node)都是獨立的參與端(data owner),因此在建模的過程中可能會因為參與端(data owner)的偏好而有動態的改變,並且整個學習過程都受到加密的保護. (联邦学习就是加密過後的分散式學習)
应用:
输入法, 根據使用者打的單詞推薦下個可能打出來的單詞,來加快使用者的打字速度. 应用联邦學習則會根據設備上的歷史記錄(數據以非常不均勻的方式分佈在數百萬個手機中),在下一次迭代中改進模型的性能.
如何解决机器学习中小数据集问题
小数据集带来的问题
- 模型容易过拟合. 模型不仅仅容易在训练集(training data)上出现过拟合的问题, 而且也可能在验证集上出现过拟合问题, 最终造成模型的稳定性降低
- 异常值难以避免. 异常值可能出现在特征里, 也可能出现在响应变量中, 对这些异常值进行处理的成本很高;与此同时异常值也可能导致训练样本和测试样本数据分布(data distribution)不一致, 降低模型稳定性
- 难以进行模型优化. 最终造成模型稳定性降低
数据不平衡
如何解决小数据集问题
数据角度:
- 降低数据不平衡影响. 可以选择过度抽样占比较少类别的数据, 使得较少类别和较多类别的数据在训练集中更加平衡
- 异常值处理. 对于小数据集, 噪声和异常值影响往往很大. 在建模之前仔细清理数据有助于我们获取合理的模型, 常见的检测异常值模型方法有OneClassSVM,Clustering methods或者Gaussian Anomaly detection. 如果条件不允许, 也可以尝试专们针对异常值而设计的模型, 例如分位数回归(quantile regression)
- 主动选择数据集特征. 尝试使用领域专业知识进行特征选择或一处, 过多特征容易造成过度拟合以及模型不稳定问题.
- 汇集更多相关数据, 权衡定制模型(personalized model)还是一般使用模型(general use model). 思考一下我们需要解决的问题, 我们是否为特定”地区”建模?如果一个”地区”的模型相关的数据较少, 不妨尝试使用所有“地区”的模型, 并根据问题重要性来加权感兴趣的“地区”. 基于此, 模型也可以从其他”地区” 学习到对于感兴趣”地区“有用的信息.
模型角度:
- 引入传统统计工具. 统计学的一个目标是在无法使用全部数据的情形下, 用少量的数据得出结论. 常见的统计学工具有:统计检验(statistical test), 参数模型(parametric model), 自助法(bootstrap)
- 选用简单模型. 模型的选择可以看成一个数据对模型投票的过程. 在某种程度上, 我们使用的每个样本都可以对所有不适合的模型进行投票, 或者对适合的模型进行投票. 当我们拥有大量数据时, 我们可以有效地探索大量模型, 最终通过数据投票找到一个合适的模型. 而我们没有大量数据时, 我们需要排除复杂的模型, 例如那些处理非线性(non-linearity)或交互特征(interaction terms). 这也意味着模型不会有太多自由度, 即太多的权重(weights)或参数(parameters) 等. 即使我们在模型中增加这些降低模型自由度的特征, 小样本本身也无法检测出这些假设/特征是否真正起了作用. 相反, 如果我们通过限制这些复杂假设, 减少模型搜索空间, 模型反而更加稳定.
- 考虑使用模型平均. 模型平均具有与正则化类似的效果, 即它减少了方差并增强了模型泛化能力. 这是一种通用技术, 可以用于任何类型的模型, 非常不同的模型一系列模型. 缺点是可能得到了大量模型, 这些大量的模型很难评估或者难以部署到实现系统(production systems). c常见的模型平均形式有:Bagging和Bayesian模型平均
- 正规化处理(regularization). 正则化可以限制模型拟合并降低有效自由度, 与此同时并不会减少模型中的实际参数数量. L1正则化产生的模型具有较少非零参数, 类似于在模型中进行了特征选择. L2正则化产生的模型更加保守(接近零)并且实际上类似于假定了参数的零中心先验(zero-centered priors)
- 降低数据不平衡. 我们可以选择在建模过程中增加比例较少但是很重要类别数据的权重(weights), scikit learn 大部分模型都支持添加weights
- 建模过程中避免过度使用验证集(validation data). 如果我们通过在验证集上的表现来选择不同的模型, 这些在验证集上的结果, 由于验证集过小, 并不是对于模型的一个好的估计, 测试结果也不一定稳健和显著.
- 贝叶斯模型. 可以考虑使用领域专业知识来构建合理的先验, 从而构建贝叶斯模型.
- 考虑非参模型. 如KNN或者决策树模型. 非参数模型性能取决于数据的分布. 并且对于异常值也很稳健. 缺点是受可用的数据集的影响很大.
- 考虑预测置信区间或者分类概率分布. 对于小数据集来说, 这点尤为重要, 因为特征空间中的某些区域变得比其他区域更少. 使用置信区间(for regressor)或者分来概率(for classifier)分布而非点估计使模型使用者避免跳到许多错误的结论.
- 如何评估小数据集下模型的好坏?
- 多样本测量. 当我们在进行训练数据集, 验证数据集以及测试数据集划分时, 我们往往会设置一个random seeds 用于随机抽取样本. 可以通过迭代随机种子(random seeds), 在不同的训练集反复上重新训练模型, 在不同的验证集上重新选择超参数(hyper-parameter), 在不同的测试集上(testing data)测试模型表现. 好的模型往往会在随机种子的迭代下, 展现出稳定的超参数组合 以及在测试集上模型的分数差别比较小.
ref: