Regex
正则
Here is a quick cheat sheet for various rules in regular expressions:
Identifiers:
- \d = any number
- \D = anything but a number
- \s = space
- \S = anything but a space
- \w = any letter or number - [a-zA-Z0-9_]
- \W = anything but a letter and number - [^\w]
- . = any character, except for a new line
- \b = space around whole words
- . = period. must use backslash, because . normally means any character.
Modifiers:
- {1,3} = for digits, u expect 1-3 counts of digits, or “places”
- + = match 1 or more
- ? = match 0 or 1 repetitions.
- * = match 0 or MORE repetitions
- $ = matches at the end of string
- ^ = matches start of a string
- | = matches either/or. Example x|y = will match either x or y
- [] = matches any character contained between the square brackets
- {x} = expect to see this amount of the preceding code.
- {x,y} = expect to see this x-y amounts of the precedng code
White Space Charts:
- \n = new line
- \s = space
- \t = tab
- \e = escape
- \f = form feed
- \r = carriage return
Characters to REMEMBER TO ESCAPE IF USED!
- . + * ? [ ] $ ^ ( ) { } |
Brackets:
- [] = quant[ia]tative = will find either quantitative, or quantatative.
- [a-z] = return any lowercase letter a-z
- [1-5a-qA-Z] = return all numbers 1-5, lowercase letters a-q and uppercase A-Z
什么是正则表达式?
正则表达式是一组由字母和符号组成的特殊文本, 它可以用来从文本中找出满足你想要的格式的句子.
一个正则表达式是一种从左到右匹配主体字符串的模式. “Regular expression”这个词比较拗口, 我们常使用缩写的术语“regex”或“regexp”. 正则表达式可以从一个基础字符串中根据一定的匹配模式替换文本中的字符串、验证表单、提取字符串等等.
想象你正在写一个应用, 然后你想设定一个用户命名的规则, 让用户名包含字符、数字、下划线和连字符, 以及限制字符的个数, 好让名字看起来没那么丑. 我们使用以下正则表达式来验证一个用户名:
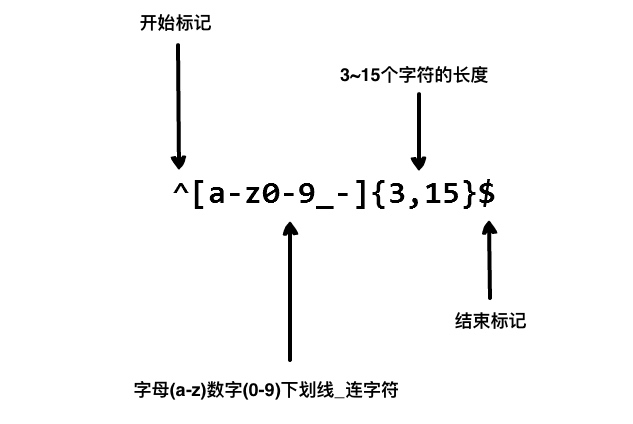
以上的正则表达式可以接受 john_doe、jo-hn_doe、john12_as.
但不匹配Jo, 因为它包含了大写的字母而且太短了.
1. 基本匹配
正则表达式其实就是在执行搜索时的格式, 它由一些字母和数字组合而成.
例如:一个正则表达式 the, 它表示一个规则:由字母t开始, 接着是h, 再接着是e.
"the" => The fat cat sat on the mat.
正则表达式123匹配字符串123. 它逐个字符的与输入的正则表达式做比较.
正则表达式是大小写敏感的, 所以The不会匹配the.
"The" => The fat cat sat on the mat.
2. 元字符
正则表达式主要依赖于元字符. 元字符不代表他们本身的字面意思, 他们都有特殊的含义. 一些元字符写在方括号中的时候有一些特殊的意思. 以下是一些元字符的介绍:
| 元字符 | 描述 |
|---|---|
| . | 句号匹配任意单个字符除了换行符. |
| [ ] | 字符种类. 匹配方括号内的任意字符. |
| [^ ] | 否定的字符种类. 匹配除了方括号里的任意字符 |
| * | 匹配>=0个重复的在*号之前的字符. |
| + | 匹配>=1个重复的+号前的字符. |
| ? | 标记?之前的字符为可选. |
| {n,m} | 匹配num个大括号之前的字符或字符集 (n <= num <= m). |
| (xyz) | 字符集, 匹配与 xyz 完全相等的字符串. |
| | | 或运算符, 匹配符号前或后的字符. |
| \ | 转义字符,用于匹配一些保留的字符 [ ] ( ) { } . * + ? ^ $ \ | |
| ^ | 从开始行开始匹配. |
| $ | 从末端开始匹配. |
2.1 点运算符 .
.是元字符中最简单的例子.
.匹配任意单个字符, 但不匹配换行符.
例如, 表达式.ar匹配一个任意字符后面跟着是a和r的字符串.
".ar" => The car parked in the garage.
2.2 字符集
字符集也叫做字符类.
方括号用来指定一个字符集.
在方括号中使用连字符来指定字符集的范围.
在方括号中的字符集不关心顺序.
例如, 表达式[Tt]he 匹配 the 和 The.
"[Tt]he" => The car parked in the garage.
方括号的句号就表示句号.
表达式 ar[.] 匹配 ar.字符串
"ar[.]" => A garage is a good place to park a car.
2.2.1 否定字符集
一般来说 ^ 表示一个字符串的开头, 但它用在一个方括号的开头的时候, 它表示这个字符集是否定的.
例如, 表达式[^c]ar 匹配一个后面跟着ar的除了c的任意字符.
"[^c]ar" => The car parked in the garage.
2.3 重复次数
后面跟着元字符 +, * or ? 的, 用来指定匹配子模式的次数.
这些元字符在不同的情况下有着不同的意思.
2.3.1 * 号
*号匹配 在*之前的字符出现大于等于0次.
例如, 表达式 a* 匹配0或更多个以a开头的字符. 表达式[a-z]* 匹配一个行中所有以小写字母开头的字符串.
"[a-z]*" => The car parked in the garage #21.
*字符和.字符搭配可以匹配所有的字符.*.
*和表示匹配空格的符号\s连起来用, 如表达式\s*cat\s*匹配0或更多个空格开头和0或更多个空格结尾的cat字符串.
"\s*cat\s*" => The fat cat sat on the concatenation.
2.3.2 + 号
+号匹配+号之前的字符出现 >=1 次.
例如表达式c.+t 匹配以首字母c开头以t结尾, 中间跟着至少一个字符的字符串.
"c.+t" => The fat cat sat on the mat.
2.3.3 ? 号
在正则表达式中元字符 ? 标记在符号前面的字符为可选, 即出现 0 或 1 次.
例如, 表达式 [T]?he 匹配字符串 he 和 The.
"[T]he" => The car is parked in the garage.
"[T]?he" => The car is parked in the garage.
2.4 {} 号
在正则表达式中 {} 是一个量词, 常用来限定一个或一组字符可以重复出现的次数.
例如, 表达式 [0-9]{2,3} 匹配最少 2 位最多 3 位 0~9 的数字.
"[0-9]{2,3}" => The number was 9.9997 but we rounded it off to 10.0.
我们可以省略第二个参数.
例如, [0-9]{2,} 匹配至少两位 0~9 的数字.
"[0-9]{2,}" => The number was 9.9997 but we rounded it off to 10.0.
如果逗号也省略掉则表示重复固定的次数.
例如, [0-9]{3} 匹配3位数字
"[0-9]{3}" => The number was 9.9997 but we rounded it off to 10.0.
2.5 (...) 特征标群
特征标群是一组写在 (...) 中的子模式. (...) 中包含的内容将会被看成一个整体, 和数学中小括号( )的作用相同. 例如, 表达式 (ab)* 匹配连续出现 0 或更多个 ab. 如果没有使用 (...) , 那么表达式 ab* 将匹配连续出现 0 或更多个 b . 再比如之前说的 {} 是用来表示前面一个字符出现指定次数. 但如果在 {} 前加上特征标群 (...) 则表示整个标群内的字符重复 N 次.
我们还可以在 () 中用或字符 | 表示或. 例如, (c|g|p)ar 匹配 car 或 gar 或 par.
"(c|g|p)ar" => The car is parked in the garage.
2.6 | 或运算符
或运算符就表示或, 用作判断条件.
例如 (T|t)he|car 匹配 (T|t)he 或 car.
"(T|t)he|car" => The car is parked in the garage.
2.7 转码特殊字符
反斜线 \ 在表达式中用于转码紧跟其后的字符. 用于指定 { } [ ] / \ + * . $ ^ | ? 这些特殊字符. 如果想要匹配这些特殊字符则要在其前面加上反斜线 \.
例如 . 是用来匹配除换行符外的所有字符的. 如果想要匹配句子中的 . 则要写成 \. 以下这个例子 \.?是选择性匹配.
"(f|c|m)at\.?" => The fat cat sat on the mat.
2.8 锚点
在正则表达式中, 想要匹配指定开头或结尾的字符串就要使用到锚点. ^ 指定开头, $ 指定结尾.
2.8.1 ^ 号
^ 用来检查匹配的字符串是否在所匹配字符串的开头.
例如, 在 abc 中使用表达式 ^a 会得到结果 a. 但如果使用 ^b 将匹配不到任何结果. 因为在字符串 abc 中并不是以 b 开头.
例如, ^(T|t)he 匹配以 The 或 the 开头的字符串.
"(T|t)he" => The car is parked in the garage.
"^(T|t)he" => The car is parked in the garage.
2.8.2 $ 号
同理于 ^ 号, $ 号用来匹配字符是否是最后一个.
例如, (at\.)$ 匹配以 at. 结尾的字符串.
"(at\.)" => The fat cat. sat. on the mat.
"(at\.)$" => The fat cat. sat. on the mat.
3. 简写字符集
正则表达式提供一些常用的字符集简写. 如下:
| 简写 | 描述 |
|---|---|
| . | 除换行符外的所有字符 |
| \w | 匹配所有字母数字, 等同于 [a-zA-Z0-9_] |
| \W | 匹配所有非字母数字, 即符号, 等同于: [^\w] |
| \d | 匹配数字: [0-9] |
| \D | 匹配非数字: [^\d] |
| \s | 匹配所有空格字符, 等同于: [\t\n\f\r\p{Z}] |
| \S | 匹配所有非空格字符: [^\s] |
| \f | 匹配一个换页符 |
| \n | 匹配一个换行符 |
| \r | 匹配一个回车符 |
| \t | 匹配一个制表符 |
| \v | 匹配一个垂直制表符 |
| \p | 匹配 CR/LF(等同于 \r\n), 用来匹配 DOS 行终止符 |
4. 零宽度断言(前后预查)
先行断言和后发断言都属于非捕获簇(不捕获文本 , 也不针对组合计进行计数). 先行断言用于判断所匹配的格式是否在另一个确定的格式之前, 匹配结果不包含该确定格式(仅作为约束).
例如, 我们想要获得所有跟在 $ 符号后的数字, 我们可以使用正后发断言 (?<=\$)[0-9\.]*.
这个表达式匹配 $ 开头, 之后跟着 0,1,2,3,4,5,6,7,8,9,. 这些字符可以出现大于等于 0 次.
零宽度断言如下:
| 符号 | 描述 |
|---|---|
| ?= | 正先行断言-存在 (前面跟着) |
| ?! | 负先行断言-排除 (前面不跟着) |
| ?<= | 正后发断言-存在 (后面跟着) |
| ?<! | 负后发断言-排除 (后面不跟着) |
4.1 ?=... 正先行断言
?=... 正先行断言, 表示第一部分表达式之后必须跟着 ?=...定义的表达式.
返回结果只包含满足匹配条件的第一部分表达式.
定义一个正先行断言要使用 (). 在括号内部使用一个问号和等号: (?=...).
正先行断言的内容写在括号中的等号后面.
例如, 表达式 (T|t)he(?=\sfat) 匹配 The 和 the, 在括号中我们又定义了正先行断言 (?=\sfat) , 即 The 和 the 后面紧跟着 (空格)fat.
"(T|t)he(?=\sfat)" => The fat cat sat on the mat.
4.2 ?!... 负先行断言
负先行断言 ?! 用于筛选所有匹配结果, 筛选条件为 其后不跟随着断言中定义的格式.
正先行断言 定义和 负先行断言 一样, 区别就是 = 替换成 ! 也就是 (?!...).
表达式 (T|t)he(?!\sfat) 匹配 The 和 the, 且其后不跟着 (空格)fat.
"(T|t)he(?!\sfat)" => The fat cat sat on the mat.
4.3 ?<= ... 正后发断言
正后发断言 记作(?<=...) 用于筛选所有匹配结果, 筛选条件为 其前跟随着断言中定义的格式.
例如, 表达式 (?<=(T|t)he\s)(fat|mat) 匹配 fat 和 mat, 且其前跟着 The 或 the.
"(?<=(T|t)he\s)(fat|mat)" => The fat cat sat on the mat.
4.4 ?<!... 负后发断言
负后发断言 记作 (?<!...) 用于筛选所有匹配结果, 筛选条件为 其前不跟随着断言中定义的格式.
例如, 表达式 (?<!(T|t)he\s)(cat) 匹配 cat, 且其前不跟着 The 或 the.
"(?<!(T|t)he\s)(cat)" => The cat sat on cat.
5. 标志
标志也叫模式修正符, 因为它可以用来修改表达式的搜索结果. 这些标志可以任意的组合使用, 它也是整个正则表达式的一部分.
| 标志 | 描述 |
|---|---|
| i | 忽略大小写. |
| g | 全局搜索. |
| m | 多行修饰符:锚点元字符 ^ $ 工作范围在每行的起始. |
5.1 忽略大小写(Case Insensitive)
修饰语 i 用于忽略大小写.
例如, 表达式 /The/gi 表示在全局搜索 The, 在后面的 i 将其条件修改为忽略大小写, 则变成搜索 the 和 The, g 表示全局搜索.
"The" => The fat cat sat on the mat.
"/The/gi" => The fat cat sat on the mat.
5.2 全局搜索(Global search)
修饰符 g 常用于执行一个全局搜索匹配, 即(不仅仅返回第一个匹配的, 而是返回全部).
例如, 表达式 /.(at)/g 表示搜索 任意字符(除了换行)+ at, 并返回全部结果.
"/.(at)/" => The fat cat sat on the mat.
"/.(at)/g" => The fat cat sat on the mat.
5.3 多行修饰符(Multiline)
多行修饰符 m 常用于执行一个多行匹配.
像之前介绍的 (^,$) 用于检查格式是否是在待检测字符串的开头或结尾. 但我们如果想要它在每行的开头和结尾生效, 我们需要用到多行修饰符 m.
例如, 表达式 /at(.)?$/gm 表示小写字符 a 后跟小写字符 t , 末尾可选除换行符外任意字符. 根据 m 修饰符, 现在表达式匹配每行的结尾.
"/.at(.)?$/" => The fat
cat sat
on the mat.
"/.at(.)?$/gm" => The fat cat sat on the mat.
6. 贪婪匹配与惰性匹配(Greedy vs lazy matching)
正则表达式默认采用贪婪匹配模式, 在该模式下意味着会匹配尽可能长的子串. 我们可以使用 ? 将贪婪匹配模式转化为惰性匹配模式.
"/(.*at)/" => The fat cat sat on the mat.
"/(.*?at)/" => The fat cat sat on the mat.
6. \b 和 \B
\b: 匹配非字母数字(\W) 与 字母数字(\w)的边界 (即\b的前一个字符和后一个字符, 必须一个是字母数字, 一个非字母数字 或者 一个是非字母数字, 一个字母数字)
\B:匹配非字母数字(\W) 与 非字母数字(\W)的边界
例如, 表达式 \bnice\b 匹配 nice, 且其前面一定不是字母数字(因为第一个\b后面的n已经是字母数字), 后面也一定不是字母数字(因为第二个\b的前面e也是字母数字, 所以另一个是非字母数组).
"\bnice\b" => It's a nice day, nice123.
第二个nice匹配不到是因为, 第二个\b的前面是e(是字母数字),后面是1也是字母数字, 所以匹配失败
7. python re模块
Re库是Python的标准库,主要用于字符串匹配 调用方式:
import re正则表达式的表示类型
- re库采用raw string(原生字符串)类型表示正则表达式,表示为: r’text’
- 例如: r’[1‐9]\d{5}’ 和 r’\d{3}‐\d{8}|\d{4}‐\d{7}’
- raw string是不包含对转义符再次转义的字符串
- re库也可以采用string类型表示正则表达式,但更繁琐
- 例如: ‘[1‐9]\d{5}’ 和 ‘\d{3}‐\d{8}|\d{4}‐\d{7}’
- 建议:当正则表达式包含转义符时,使用raw string
主要功能函数

re.search(pattern, string, flags=0)
在一个字符串中搜索匹配正则表达式的第一个位置返回match对象
- pattern : 正则表达式的字符串或原生字符串表示
- string : 待匹配字符串
flags : 正则表达式使用时的控制标记
- re.I (ignorecase): 忽略正则表达式的大小写
- re.M (multiline): 正则表达式中的^操作符能够将给定字符串的每行当做匹配开始
re.S (dotall): 正则表达式中的.操作符能够匹配所有字符, 默认匹配除换行外的所有字符
>>> match = re.search(r'[1-9]\d{5}', 'BIT 100081') >>> if match: ... print(match.group(0)) ... 100081
re.match(pattern, string, flags=0)
从一个字符串的开始位置起匹配正则表达式返回match对象
- pattern : 正则表达式的字符串或原生字符串表示
- string : 待匹配字符串
flags : 正则表达式使用时的控制标记
Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'NoneType' object has no attribute 'group' >>> match = re.match(r'[1-9]\d{5}', '100081 BIT') >>> if match: ... print(match.group(0)) ... 100081
re.findall(pattern, string, flags=0)
搜索字符串,以列表类型返回全部能匹配的子串
- pattern : 正则表达式的字符串或原生字符串表示
- string : 待匹配字符串
flags : 正则表达式使用时的控制标记
>>> match = re.findall(r'[1-9]\d{5}', 'BIT 100081 TSU100082') >>> match ['100081', '100082']
re.split(pattern, string, maxsplit=0, flags=0)
将一个字符串按照正则表达式匹配结果进行分割返回列表类型
- pattern : 正则表达式的字符串或原生字符串表示
- string : 待匹配字符串
- maxsplit: 最大分割数,剩余部分作为最后一个元素输出
flags : 正则表达式使用时的控制标记
>>> match = re.findall(r'[1-9]\d{5}', 'BIT 100081 TSU100082') >>> match ['100081', '100082'] >>> match = re.split(r'[1-9]\d{5}', 'BIT 100081 TSU100082') >>> match ['BIT ', ' TSU', ''] >>> match = re.split(r'[1-9]\d{5}', 'BIT 100081 TSU100082', maxsplit=1) >>> match ['BIT ', ' TSU100082']
re.finditer(pattern, string, flags=0)
搜索字符串,返回一个匹配结果的迭代类型,每个迭代元素是match对象
- pattern : 正则表达式的字符串或原生字符串表示
- string : 待匹配字符串
flags : 正则表达式使用时的控制标记
>>> for m in re.finditer(r'[1-9]\d{5}', 'BIT 100081 TSU100082'): ... if m: ... print(m.group(0)) ... 100081 100082
re.sub(pattern, repl, string, count=0, flags=0)
在一个字符串中替换所有匹配正则表达式的子串返回替换后的字符串
- pattern: 正则表达式的字符串或原生字符串表示
- repl: 替换匹配字符串的字符串
- string: 待匹配字符串
- count: 匹配的最大替换次数
flags: 正则表达式使用时的控制标记
>>> re.sub(r'[1-9]\d{5}',':zipcode', 'BIT 100081 TSU100082') 'BIT :zipcode TSU:zipcode'
Re库的另一种等价用法 => re.compile(pattern, flags=0)
将正则表达式的字符串形式编译成正则表达式对象 * pattern : 正则表达式的字符串或原生字符串表示 * flags : 正则表达式使用时的控制标记
函数式用法:一次性操作
rst = re.search(r'[1‐9]\d{5}', 'BIT 100081')面向对象用法:编译后的多次操作
pat = re.compile(r'[1‐9]\d{5}')
rst = pat.search('BIT 100081')Re库的Match对象
Match对象是一次匹配的结果,包含匹配的很多信息
>>> match = re.search(r'[1‐9]\d{5}', 'BIT 100081')
>>> if match:
print(match.group(0))
>>> type(match)
<class '_sre.SRE_Match'>Match对象的属性
- .string: 待匹配的文本
- .re: 匹配时使用的pattern对象(正则表达式)
- .pos: 正则表达式搜索文本的开始位置
- .endpos: 正则表达式搜索文本的结束位置
Match对象的方法
- .group(0): 获得匹配后的字符串
- .start(): 匹配字符串在原始字符串的开始位置
- .end(): 匹配字符串在原始字符串的结束位置
- .span(): 返回(.start(), .end())
例子:
>>> match = re.search(r'[1-9]\d{5}', 'BIT 100081')
>>> match.string
'BIT 100081'
>>> match.re
re.compile('[1-9]\\d{5}')
>>> match.pos
0
>>> match.endpos
10
>>> match.group(0)
'100081'
>>> match.start()
4
>>> match.end()
10
>>> match.span()
(4, 10)Re库的贪婪匹配
>>> match = re.search(r'PY.*N', 'PYANBNCNDN')
>>> match.group(0)
'PYANBNCNDN'Re库默认采用贪婪匹配,即输出匹配最长的子串
Re库的最小匹配
输出最短的子串
>>> match = re.search(r'PY.*?N', 'PYANBNCNDN')
>>> match.group(0)
'PYAN'只要长度输出可能不同的,都可以通过在操作符后增加?变成最小匹配:
- *?: 前一个字符0次或无限次扩展, 最小匹配
- +?: 前一个字符1次或无限次扩展, 最小匹配
- ??: 前一个字符0次或1次扩展, 最小匹配
- {m,n}?: 扩展前一个字符m至n次(含n), 最小匹配