Python
getattr, getitem….
__getattribute__只适用于所有的`.`运算符
__getitem__只适用于所有的`[]`运算符
__getattr__解决了访问不存在的属性报错问题, 找不到属性时会被调用
__get__作为数据描述符,那么此对象只能作为类属性,作为实例属性则无效collections
from collections import defaultdict, UserDictUserDict:
from collections import UserDict
d = {'a':1,
'b': 2,
'c': 3}
# Creating an UserDict
userD = UserDict(d)
print(userD.data)
>> {'a': 1, 'b': 2, 'c': 3}
# Creating an empty UserDict
userD = UserDict()
print(userD.data)
>> {}
# Creating a Dictionary where deletion is not allowed
class MyDict(UserDict):
# Function to stop deleltion from dictionary
def __del__(self):
raise RuntimeError("Deletion not allowed")
# Function to stop pop from dictionary
def pop(self, s = None):
raise RuntimeError("Deletion not allowed")
# Function to stop popitem from Dictionary
def popitem(self, s = None):
raise RuntimeError("Deletion not allowed")
# Driver's code
d = MyDict({'a':1,
'b': 2,
'c': 3})
print("Original Dictionary")
print(d)
>> "Original Dictionary"
>> {'a': 1, 'c': 3, 'b': 2}
d.pop(1)
>> RuntimeError: Deletion not allowedExample2 - 一个增强的字典类, 允许对字典使用 “加/+” :
from collections import UserDict
class FancyDict(UserDict):
def __init__(self, data = {}, **kw):
UserDict.__init__(self)
self.update(data)
self.update(kw)
def __add__(self, other):
tmp_dict = FancyDict(self.data)
tmp_dict.update(b)
return tmp_dict
a = FancyDict(a = 1)
b = FancyDict(b = 2)
print(a + b)
>> {'a': 1, 'b': 2}class/static/abstract method
property
封裝是個很基本的要素.不讓外部使用者直接碰到物件的內容,而只能透過方法來修改或取用內部的屬性.
class gundam(object):
def __init__(self, driver):
self.driver = driver
g1 = gundam('Charon')
g1.driver
>> 'Charon'
g1.driver = 'Alan'
g1.driver
>> 'Alan'雖然可以实例化高达class (初始化時要填入駕駛名字),和取得駕駛名字,但是這樣的方式也會讓使用者輕易把駕駛替換掉 為了安全,將駕駛換成私有屬性
class gundam(object):
def __init__(self, driver):
self._driver = driver这是如果再用上面的方法就会报错
Get 和 Set
可以換個寫法,加上 get 和 set 方法來操作私有屬性
class gundam(object):
def __init__(self, driver):
self._driver = driver
def get_driver(self):
return self._driver
def set_driver(self, new_driver):
self._driver = new_driver
g2 = gundam('Charon')
g2.get_driver()
>> 'Charon'
g2.set_driver('Alan')
g2.get_driver()
>> 'Alan'Property
如果不想讓取出那麼麻煩, Python 有一種方式可以將私有屬性讓使用者用起來像公開屬性一樣,就是加上 property 這個裝飾器.
class gundam(object):
def __init__(self, driver):
self._driver = driver
@property
def driver(self):
return self._driver
def set_driver(self, new_driver):
self._driver = new_driver
g3 = gundam('Charon')
g3.driver
>> 'Charon'
g3.driver = 'Alan'
>> AttributeError: can't set attributeGetter 和 Setter
class gundam(object):
def __init__(self, driver=None):
self._driver = driver
@property
def driver(self):
print('!!!get driver!!!')
return self._driver
@driver.setter
def driver(self, new_driver):
print('!!!set driver!!!')
if type(new_driver) == str:
self._driver = new_driver
else:
raise TypeError('driver need str.')
g4 = gundam('Charon')
>> '!!!set driver!!!'
g4.driver
>> '!!!get driver!!!'
>> 'Charon'
g4.driver = 'Alan'
>> '!!!set driver!!!'
g4.driver
>> '!!!get driver!!!'
>> 'Alan'一開始初始化的時候,雖然是寫 self.driver = driver ,這時候就會呼叫 setter 函數,使用者輸入的參數便指派到 self._driver 中.之後用 g4.driver 的時候就會直接取出 self._driver 出來
用起來就跟一開始的範例一模一樣,但是背後其實是在操作私有屬性.使用者也更容易透過 setter 方法來管理使用者輸入的值
Pandas
pandas.DataFrame.resample 根据时间聚合采样
https://blog.csdn.net/brucewong0516/article/details/84768464
DataFrame.resample(rule, how=None, axis=0, fill_method=None, closed=None,
label=None, convention='start', kind=None, loffset=None,
limit=None, base=0, on=None, level=None)pandas.DataFrame.pct_change 计算Percentage change
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.pct_change.htmlpandas.DataFrame.to_dict dataframe转换成dict
orient: str {‘dict’, ‘list’, ‘series’, ‘split’, ‘records’, ‘index’}
Determines the type of the values of the dictionary.
‘dict’ (default) : dict like {column -> {index -> value}}
‘list’ : dict like {column -> [values]}
‘series’ : dict like {column -> Series(values)}
‘split’ : dict like {‘index’ -> [index], ‘columns’ -> [columns], ‘data’ -> [values]}
‘records’ : list like [{column -> value}, … , {column -> value}]
‘index’ : dict like {index -> {column -> value}}Convert dict into a dataframe
def dict_to_df(d):
df=pd.DataFrame(d.items(), columns=['Date', 'DateValue'])
df.set_index(0, inplace=True)
# df['Date'] = pd.to_datetime(df['Date'])
return dfchange a single index/column value in pandas dataframe
df.rename(index={'2020-07-30':'2020-07-25'},inplace=True)
df.rename(column={'Adj Close':'amount'},inplace=True)convert Pandas Timestamp index to list of date strings
df.index.strftime("%Y-%m-%d")Display all dataframe columns in a Jupyter Python Notebook
import pandas as pd
pd.set_option('display.max_columns', <number of columns>)
# can do the same for the rows too:
pd.set_option('display.max_rows', <number of rows>)get DataFrame.pct_change to calculate monthly change on daily price data
### resample the data to business mont
In [31]: from pandas.io import data as web
# read some example data, note that this is not exactly your data!
In [32]: s = web.get_data_yahoo('AAPL', start='2009-01-02',
... end='2009-12-31')['Adj Close']
# resample to business month and return the last value in the period
In [34]: monthly = s.resample('BM').apply(lambda x: x[-1])
In [35]: monthly
Out[35]:
Date
2009-01-30 89.34
2009-02-27 88.52
2009-03-31 104.19
...
2009-10-30 186.84
2009-11-30 198.15
2009-12-31 208.88
In [36]: monthly.pct_change()
Out[36]:
Date
2009-01-30 NaN
2009-02-27 -0.009178
2009-03-31 0.177022
...
2009-10-30 0.016982
2009-11-30 0.060533
2009-12-31 0.054151Delete column from pandas DataFrame
# The best way to do this in pandas is to use drop:
df = df.drop('column_name', 1)
# where 1 is the axis number (0 for rows and 1 for columns.)
# To delete the column without having to reassign df you can do:
df.drop('column_name', axis=1, inplace=True)
# Finally, to drop by column number instead of by column label, try this to delete, e.g. the 1st, 2nd and 4th columns:
df = df.drop(df.columns[[0, 1, 3]], axis=1) # df.columns is zero-based pd.Index
# Also working with "text" syntax for the columns:
df.drop(['column_nameA', 'column_nameB'], axis=1, inplace=True)count the NaN values in a column in pandas DataFrame
s = pd.Series([1,2,3, np.nan, np.nan])
s.isna().sum() # or s.isnull().sum() for older pandas versions
# 2__init__.py
init.py该文件的作用就是相当于把自身整个文件夹当作一个包来管理,每当有外部import的时候,就会自动执行里面的函数
例子1:
.
└── test
├── A
│ ├── A_A
│ │ ├── A_A_A.py
│ │ └── A_A_B.py
│ └── A_B.py
└── B
└── run.py建立了一个test文件夹,其中一个文件夹A打算建立成一个软件包,然后尝试在B文件夹的的run.py文件下导入A包中的模块
在B/run.py中运行以下语句的结果为:
| Sentence | Result |
|---|---|
| import A | ImportError: No module named A |
| import A.A_A | ImportError: No module named A.A_A |
| import A.A_B | ImportError: No module named A.A_B |
结论:此时A并不能被当成是一个软件包
例子2:
.
└── test
├── A
│ ├── A_A
│ │ ├── A_A_A.py
│ │ └── A_A_B.py
│ ├── __init__.py
│ └── A_B.py
└── B
└── run.pyA文件夹下包含init.py
在B/run.py中运行以下语句的结果为:
| Sentence | Result |
|---|---|
| import A | 成功 |
| import A.A_A | ImportError: No module named A.A_A |
| import A.A_B | 成功 |
结论:由A.A_B能被成功import看出此时A已经是一个软件包,因为A下的.py文件已经能够程序识别出来. 但是由于A下的A_A还不是一个软件包,所以A.A_A还不能被导入
例子3:
.
└── test
├── A
│ ├── A_A
│ │ ├── __init__.py
│ │ ├── A_A_A.py
│ │ └── A_A_B.py
│ ├── __init__.py
│ └── A_B.py
└── B
└── run.pyA文件夹及其子文件夹下都包含init.py
在B/run.py中运行以下语句的结果为:
| Sentence | Result |
|---|---|
| import A | 成功 |
| import A.A_A | 成功 |
| import A.A_B | 成功 |
结论:此时A及其子文件夹A_A都成功变成软件包,其中的模块可以被任意导入
Python Thread
使用 futures 处理并发: https://www.jianshu.com/p/62145aed2d49
无线程:
# No thread
import time
start_time = time.time()
ppl = 500
def action(num):
global ppl
while ppl > 0:
ppl -= 50
print(f'车辆编号: {num}, 当前车站人数: {ppl}')
time.sleep(1)
num = 1
action(num)
print(f'Duration: {time.time()-start_time}')
'''
车辆编号: 1, 当前车站人数: 450
车辆编号: 1, 当前车站人数: 400
车辆编号: 1, 当前车站人数: 350
车辆编号: 1, 当前车站人数: 300
车辆编号: 1, 当前车站人数: 250
车辆编号: 1, 当前车站人数: 200
车辆编号: 1, 当前车站人数: 150
车辆编号: 1, 当前车站人数: 100
车辆编号: 1, 当前车站人数: 50
车辆编号: 1, 当前车站人数: 0
Duration: 10.034696340560913
'''单线程:
# Signle thread
import time
# import threading
from threading import Thread
start_time = time.time()
ppl = 500
def action(num):
global ppl
while ppl > 0:
ppl -= 50
print(f'车辆编号: {num}, 当前车站人数: {ppl}')
time.sleep(1)
num = 1
vehicle = Thread(target=action, args=(num,))
vehicle.start()
vehicle.join()
print(f'Duration: {time.time()-start_time}')
'''
车辆编号: 1, 当前车站人数: 450
车辆编号: 1, 当前车站人数: 400
车辆编号: 1, 当前车站人数: 350
车辆编号: 1, 当前车站人数: 300
车辆编号: 1, 当前车站人数: 250
车辆编号: 1, 当前车站人数: 200
车辆编号: 1, 当前车站人数: 150
车辆编号: 1, 当前车站人数: 100
车辆编号: 1, 当前车站人数: 50
车辆编号: 1, 当前车站人数: 0
Duration: 10.028159141540527
'''多线程 (传递对象方式):
# Multi thread 1
import time
# import threading
from threading import Thread
start_time = time.time()
ppl = 500
def action(num):
global ppl
while ppl > 0:
ppl -= 50
print(f'车辆编号: {num}, 当前车站人数: {ppl}')
time.sleep(1)
vehicles = [] # 新建车辆组
for num in range(1,6):
vehicle = Thread(target=action, args=(num,)) # 新建车辆
vehicles.append(vehicle) # 添加车辆到车辆组中
for vehicle in vehicles:
vehicle.start() # 分别启动车辆
for vehicle in vehicles:
vehicle.join() # 分别检查到站车辆
print(f'Duration: {time.time()-start_time}')
'''
车辆编号: 1, 当前车站人数: 450
车辆编号: 2, 当前车站人数: 400
车辆编号: 3, 当前车站人数: 350
车辆编号: 4, 当前车站人数: 300
车辆编号: 5, 当前车站人数: 250
车辆编号: 2, 当前车站人数: 200
车辆编号: 1, 当前车站人数: 150
车辆编号: 3, 当前车站人数: 100
车辆编号: 4, 当前车站人数: 50
车辆编号: 5, 当前车站人数: 0
Duration: 2.0072731971740723
'''多线程 (覆盖子类方式):
# Multi thread 2
import time
# import threading
from threading import Thread
start_time = time.time()
ppl = 500
class MyThread(Thread):
def __init__(self, num):
super(MyThread, self).__init__()
self.num = num
def run(self):
global ppl
while ppl > 0:
ppl -= 50
print(f'车辆编号: {self.num}, 当前车站人数: {ppl}')
time.sleep(1)
vehicles = [] # 新建车辆组
for num in range(1,6): # 设置车辆数
vehicle = MyThread(num) # 新建车辆
vehicles.append(vehicle) # 添加车辆到车辆组中
vehicle.start() #启动车辆
for vehicle in vehicles:
vehicle.join() # 分别检查到站车辆
print(f'Duration: {time.time()-start_time}')
'''
车辆编号: 1, 当前车站人数: 450
车辆编号: 2, 当前车站人数: 400
车辆编号: 3, 当前车站人数: 350
车辆编号: 4, 当前车站人数: 300
车辆编号: 5, 当前车站人数: 250
车辆编号: 1, 当前车站人数: 200
车辆编号: 2, 当前车站人数: 150
车辆编号: 3, 当前车站人数: 100
车辆编号: 4, 当前车站人数: 50
车辆编号: 5, 当前车站人数: 0
Duration: 2.00836181640625
'''小结:
- 不使用线程类和使用单线程运行时间是一样的,因为正常执行一个脚本,本质上就是单线程
- 创建多线程的两种方法运行时间也是一样的,因为最终都是交给Thread类来处理,自行选择即可
- 多线程运行时间明显比单线程快的多,从理论上来说是和线程数成正比的,但是实际并非是线程越多越好,因为线程越多所消耗的资源也就越多
Thread类提供了以下方法:
- run(): 用以表示线程活动的方法
- start():启动线程活动
- join([time]): 等待至线程中止. 这阻塞调用线程直至线程的join() 方法被调用中止
- 正常退出或者抛出未处理的异常
- 或者是可选的超时发生
- isAlive(): 返回线程是否活动的
- getName(): 返回线程名
- setName(): 设置线程名
说明:
- 创建线程对象后,必须通过调用线程的start() 方法启动其活动,这将在单独的控制线程中调用run()方法
- 一旦线程的活动开始,线程就被认为是“活着的”,当run()方法终止时,它会停止活动,或者引发异常
- 线程可以调用is_alive()方法测试是否处于活动状态,其他线程可以调用线程的join()方法,这将阻塞调用线程,直到调用其join()方法的线程终止
- 线程有一个名称,这个名称可以传递给构造函数,并通过name属性读取或更改
- 线程可以标记为“守护程序线程”,这个标志的意义在于,当只剩下守护进程线程时,整个Python程序都会退出,可以通过守护程序属性设置该标志
Python ZMQ
- ZMQ (以下 ZeroMQ 简称 ZMQ)是一个简单好用的传输层,像框架一样的一个 socket library,他使得 Socket 编程更加简单、简洁和性能更高
- 是一个消息处理队列库,可在多个线程、内核和主机盒之间弹性伸缩. ZMQ 的明确目标是“成为标准网络协议栈的一部分,之后进入 Linux 内核”
- ZMQ 让编写高性能网络应用程序极为简单和有趣
- ZeroMQ并不是一个对socket的封装,不能用它去实现已有的网络协议
- 它有自己的模式,不同于更底层的点对点通讯模式
- 它有比tcp协议更高一级的协议。(当然ZeroMQ不一定基于TCP协议,它也可以用于进程间和进程内通讯)
- zeromq 并不是类似rabbitmq消息列队,它实际上只一个消息列队组件,一个库
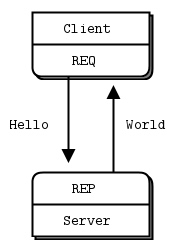
Request-Reply模式(请求响应模型)
- 客户端在请求后,服务端必须回响应
- 由客户端发起请求,并等待服务端响应请求
- 从客户端端来看,一定是一对对发收配对的
- 反之,在服务端一定是收发对
- 服务端和客户端都可以是1:N的模型. 通常把1认为是server,N认为是Client.
- ZMQ可以很好的支持路由功能(实现路由功能的组件叫做Device),把1:N扩展为N:M(只需要加入若干路由节点)
- 从这个模型看,更底层的端点地址是对上层隐藏的. 每个请求都隐含回应地址,而应用则不关心它
server.py
import zmq
import sys
context = zmq.Context()
socket = context.socket(zmq.REP)
socket.bind("tcp://*:5555")
while True:
try:
print("wait for client ...")
message = socket.recv()
print("message from client:", message.decode('utf-8'))
socket.send(message)
except Exception as e:
print('异常:',e)
sys.exit()client.py
import zmq
import sys
context = zmq.Context()
print("Connecting to server...")
socket = context.socket(zmq.REQ)
socket.connect("tcp://localhost:5555")
while True:
input1 = input("请输入内容:").strip()
if input1 == 'b':
sys.exit()
socket.send(input1.encode('utf-8'))
message = socket.recv()
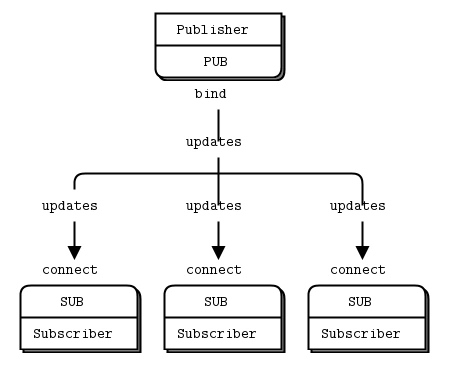
print("Received reply: ", message.decode('utf-8'))Publish-Subscribe模式(发布订阅模型)
广播所有client,没有队列缓存,断开连接数据将永远丢失. client可以进行数据过滤.
server.py
import zmq
import time
import sys
context = zmq.Context()
socket = context.socket(zmq.PUB)
socket.bind("tcp://*:5555")
while True:
msg = input("请输入要发布的信息:").strip()
if msg == 'b':
sys.exit()
socket.send(msg.encode('utf-8'))
time.sleep(1)client1.py
import zmq
context = zmq.Context()
socket = context.socket(zmq.SUB)
socket.connect("tcp://localhost:5555")
socket.setsockopt(zmq.SUBSCRIBE,''.encode('utf-8')) # 接收所有消息
while True:
response = socket.recv().decode('utf-8');
print("response: %s" % response)client2.py
import zmq
context = zmq.Context()
socket = context.socket(zmq.SUB)
socket.connect("tcp://localhost:5555")
socket.setsockopt(zmq.SUBSCRIBE,'123'.encode('utf-8')) # 消息过滤 只接受123开头的信息
while True:
response = socket.recv().decode('utf-8');
print("response: %s" % response)结果:
### server发布以下信息(注意:b是关闭发布端的指令):
请输入要发布的信息:hello python
请输入要发布的信息:发布以下信息
请输入要发布的信息:123435678
请输入要发布的信息:123三部分
请输入要发布的信息:广播模式,发布端只关心发布信息,不关心订阅端是否接收
请输入要发布的信息:b
### client1接收的信息:
response: hello python
response: 发布以下信息
response: 123435678
response: 123三部分
response: 广播模式,发布端只关心发布信息,不关心订阅端是否接收
### client2接收的信息 (只接收123开头的信息):
response: 123435678
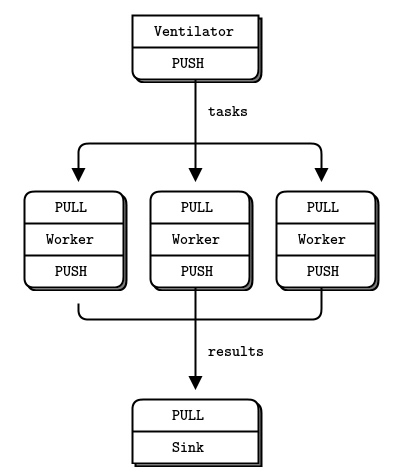
response: 123三部分Parallel Pipeline模式(管道模型)
由三部分组成:
- push进行数据推送,
- work进行数据缓存,
- pull进行数据竞争获取处理.
区别于Publish-Subscribe存在一个数据缓存和处理负载
当连接被断开,数据不会丢失,重连后数据继续发送到对端.
server.py
import zmq
import time
context = zmq.Context()
socket = context.socket(zmq.PUSH)
socket.bind("tcp://*:5557")
while True:
msg = input("请输入要发布的信息:").strip()
socket.send(msg.encode('utf-8'))
print("已发送")
time.sleep(1)worker.py
import zmq
context = zmq.Context()
receive = context.socket(zmq.PULL)
receive.connect('tcp://127.0.0.1:5557')
sender = context.socket(zmq.PUSH)
sender.connect('tcp://127.0.0.1:5558')
while True:
data = receive.recv()
print("正在转发...")
sender.send(data)client.py
import zmq
context = zmq.Context()
socket = context.socket(zmq.PULL)
socket.bind("tcp://*:5558")
while True:
response = socket.recv().decode('utf-8')
print("response: %s" % response)结果:
### server端:
请输入要发布的信息:hello python
已发送
请输入要发布的信息:不可阻挡
已发送
请输入要发布的信息:123abc
已发送
请输入要发布的信息:
### work端:
正在转发...
正在转发...
正在转发...
### client端:(接收第二条信息后断开,断开后重新收到的信息)
response: 123abcPython 打包成Mac app
在Mac下打包用Tkinter开发出来的应用程序
安装
pip3 install py2app创建setup.py文件
- 进入项目工程
cd 项目路径 创建setup.py
py2applet --macke-setup python文件- E.g.
py2applet --macke-setup main.py - 可能报错:
py2applet:command not found - 解决:
sudo find / -name "py2applet" -type f
- 成功了会显示Wrote setup.py,在你的工程下会有setup.py文件
若是setup.py文件创建失败, 报错, 报错信息为:
*** creating application bundle: MyApp *** error: [Errno 1] Operation not permitted MacOSX El Captain引入的SIP(系统完整性保护)功能会影响py2app创建应用
- 禁用SIP
csrutil statuscsrutil disable:SIP安全已关闭csrutil enable:SIP安全已开启
- 设置SIP
- 重启Mac,同时按住Command+R,直到进入Recovery Model
- 点击Utilities —>Terminal
- 在Terminal输入
csrutil disable或csrutil enabel,回车 - 重启Mac,完成
- 删除受限制的文件标志
sudo chflags -R norestricted /System/Library/Frameworks/Python.framework
- 禁用SIP
- E.g.
设置程序图标
- 在Easyicon网站下载了icns格式的图标,将图标另存为到桌面上存放脚本的文件夹
打开setup.py文件,修改其中OPTIONS内容
OPTIONS = { 'iconfile':'icon.icns' }也可以使用命令的参数模式直接生成带有图标设置的setup文件:
py2applet --make-setup main.py icon.icns
打包应用程序
- 清除旧的内容
rm -rf build dist - 创建app应用
python3 setup.py py2apppython setup.py py2app -A- 给其他没有sdk的电脑使用, 包括lib库.(没有安装sdk的电脑使用, 需要去掉-A,将把所有的依赖全部打包)
- 等待创建,创建完成后,项目目录会多build和dist文件夹,程序应用就在dist文件下
- 清除旧的内容
Python Seed
import numpy as np
num=0
while(num<5):
np.random.seed(1)
print(np.random.random())
num+=1
print('-------------------------')
num1=0
np.random.seed(2)
while(num1<5):
print(np.random.random())
num1+=1运行结果:
0.417022004702574
0.417022004702574
0.417022004702574
0.417022004702574
0.417022004702574
---------------------
0.43599490214200376
0.025926231827891333
0.5496624778787091
0.4353223926182769
0.42036780208748903众所周知,所谓随机数其实是伪随机数,所谓的‘伪’,意思是这些数其实是有规律的,只不过因为算法规律太复杂,很难看出来.
所谓巧妇难为无米之炊,再厉害的算法,没有一个初始值,它也不可能凭空造出一系列随机数来,诶,种子就是这个初始值.
可以将随机数生成的算法看成一个黑盒,把准备好的种子扔进去,它会返给你两个东西,一个是随机数,另一个是保证能生成下一个随机数的新的种子,把新的种子放进黑盒,又得到一个新的随机数和一个新的种子….
第一段代码把对种子的设置放在了循环里面,每次执行循环都旗帜鲜明地告诉黑盒:“我的种子是1”. 那么很显然:同一个黑盒,同一个种子,自然得到的是同一个随机数.
第二段代码把对种子的设置放在了循环外面,它只在第一次循环的时候明确地告诉黑盒:“我的种子是2”. 那么也很显然:从第二次循环开始,黑盒用的就是自己生成的新种子了.
Python eval & ast.literal_eval
作用: 把数据还原成它本身或者是能够转化成的数据类型
使用eval可以实现从元祖,列表,字典型的字符串到元祖,列表,字典的转换. 此外,eval还可以对字符串型的输入直接计算. 比如,她会将’1+1’的计算串直接计算出结果:
str_list = '[1,2,3,4]'
true_list = eval(str_list)
print(true_list) # [1,2,3,4]
print(type(true_list),type(str_list)) # <class 'list'> <class 'str'>
str_tuple = '(1,2,3,4)'
true_tuple = eval(str_tuple)
print(true_tuple) # (1,2,3,4)
print(type(true_tuple),type(str_tuple)) # <class 'tuple'> <class 'str'>
str_dict = "{'name':'Charon',}"
true_dict = eval(str_dict)
print(true_dict) # [1,2,3,4]
print(type(true_dict),type(str_dict)) # <class 'dict'> <class 'str'>
value = eval(input('Plz enter a math formula: ')) # Plz enter a math formula: 1+1
print(value) # 2eval强大的背后,是巨大的安全隐患. 比如说,用户恶意输入下面的字符串:
open(r'/Desktop/filename.txt', 'r').read()
__import__('os').system('dir')
__import__('os').system('rm -rf /etc/*')那么eval就会显示你电脑目录结构,读取文件,删除文件…..如果是格盘等更严重的操作也一样执行.
所以这里就引出了另外一个安全处理方式ast.literal_eval. 官网解释:
Safely evaluate an expression node or a Unicode or Latin-1 encoded string containing a Python expression. The string or node provided may only consist of the following Python literal structures: strings, numbers, tuples, lists, dicts, booleans, and None.
This can be used for safely evaluating strings containing Python expressions from untrusted sources without the need to parse the values oneself.ast模块就是帮助Python应用来处理抽象的语法解析的. 而该模块下的literal_eval()函数:则会判断需要计算的内容计算后是不是合法的python类型,如果是则进行运算,否则就不进行运算.
比如说上面的计算操作,及危险操作,如果换成了ast.literal_eval(), 都会拒绝执行. 报值错误,不合法的字符串.
import ast
value = ast.literal_eval('1+1')
print(value)
'''
Traceback (most recent call last):
File "/Users/charon/Desktop/adviser-master/adviser/component_test.py", line 77, in <module>
value = ast.literal_eval('1+1')
File "/usr/local/Cellar/python/3.7.7/Frameworks/Python.framework/Versions/3.7/lib/python3.7/ast.py", line 91, in literal_eval
return _convert(node_or_string)
File "/usr/local/Cellar/python/3.7.7/Frameworks/Python.framework/Versions/3.7/lib/python3.7/ast.py", line 90, in _convert
return _convert_signed_num(node)
File "/usr/local/Cellar/python/3.7.7/Frameworks/Python.framework/Versions/3.7/lib/python3.7/ast.py", line 63, in _convert_signed_num
return _convert_num(node)
File "/usr/local/Cellar/python/3.7.7/Frameworks/Python.framework/Versions/3.7/lib/python3.7/ast.py", line 55, in _convert_num
raise ValueError('malformed node or string: ' + repr(node))
ValueError: malformed node or string: <_ast.BinOp object at 0x12970a050>
'''而只会执行合法的Python类型,从而大大降低系统的危险性. 所以出于安全考虑,对字符串进行类型转换的时候,最好使用ast.literal_eval()函数.
Python heapq
该模块提供了堆排序算法的实现。堆是二叉树,最大堆中父节点大于或等于两个子节点,最小堆父节点小于或等于两个子节点
针对问题: 找到该序列中最大或者最小的N个元素
一般方法
### 普通列表
l = [1,2,4,3,6,0,5,7,9]
sorted(l)
print("前三个:{},后三个:{}".format(l[:3], l[-3:]))
# 前三个:[1, 2, 4],后三个:[5, 7, 9]
### 复杂列表
scoreInfo=[
{'name':'Lucy','en_score': 89.6,'math_scroe':94.1},
{'name':'Bob','en_score': 72.4,'math_scroe':84.2},
{'name':'LiLei','en_score': 82.6,'math_scroe':74.1},
{'name':'HanMeimei','en_score': 65.6,'math_scroe':86.9},
{'name':'Lily','en_score': 78.1,'math_scroe':65.8},
{'name':'Tracy','en_score': 72.6,'math_scroe':65.4},
]
# 按照英语成绩'en_score'对学生进行排名,找出前3名和后3名
t_scoreInfo = sorted([item for item in scoreInfo], key=lambda x: x['en_score'], reverse=True)
print('前三个:{}\n后三个:{}'.format(t_scoreInfo[:3], t_scoreInfo[-3:]))
# 前三个:[{'name': 'Lucy', 'en_score': 89.6, 'math_scroe': 94.1}, {'name': 'LiLei', 'en_score': 82.6, 'math_scroe': 74.1}, {'name': 'Lily', 'en_score': 78.1, 'math_scroe': 65.8}]
# 后三个:[{'name': 'Tracy', 'en_score': 72.6, 'math_scroe': 65.4}, {'name': 'Bob', 'en_score': 72.4, 'math_scroe': 84.2}, {'name': 'HanMeimei', 'en_score': 65.6, 'math_scroe': 86.9}]使用内置函数heapq
import heapq
# 简单序列
l = [1,2,4,3,6,0,5,7,9]
print('前三:{}'.format(heapq.nlargest(3, l))) # 前三:[9, 7, 6]
print('后三:{}'.format(heapq.nsmallest(3, l))) # 后三:[0, 1, 2]
# 复杂序列
high =heapq.nlargest(3, scoreInfo, key=lambda s: s['en_score'])
low = heapq.nsmallest(3, scoreInfo, key=lambda s: s['en_score'])
print("前三:{}\n后三:{}".format(high, low))
# 前三:[{'name': 'Lucy', 'en_score': 89.6, 'math_scroe': 94.1}, {'name': 'LiLei', 'en_score': 82.6, 'math_scroe': 74.1}, {'name': 'Lily', 'en_score': 78.1, 'math_scroe': 65.8}]
# 后三:[{'name': 'HanMeimei', 'en_score': 65.6, 'math_scroe': 86.9}, {'name': 'Bob', 'en_score': 72.4, 'math_scroe': 84.2}, {'name': 'Tracy', 'en_score': 72.6, 'math_scroe': 65.4}]nlargest()和nsmallest()函数的底层实现是:先将序列数据进行堆排序后放入一个列表中
堆(heap)的数据结构有以下优点:
- heap[0]永远是最小的元素
- 其余元素可通过调用 heapq.heappop()方法得到,该方法会先将第一个元素弹出来,然后用下一个最小的元素来取代被弹出元素(这种操作时间复杂度仅仅是O(log N),N是堆大小)
通过上面的描述,如果查找最小的三个元素,其实等价于分别从堆结构中使用heappop()方法弹出3个值即可
heapq的其他方法:
heapq有两种方式创建堆, 一种是使用一个空列表,然后使用heapq.heappush()函数把值加入堆中,另外一种就是使用heap.heapify(list)转换列表成为堆结构
### 方法一:使用heappush()方法
heap = []
data = [2,3,5,7,9,23,14,16,12,10]
for i in data:
heapq.heappush(heap,i)
print(heap) # [2, 3, 5, 7, 9, 23, 14, 16, 12, 10] !!没有进行排序!!
### 方法二:使用heapify()方法
data = [2,3,5,7,9,23,14,16,12,10]
heapq.heapify(data)
# 此时,直接变换data数据为堆结构,并没有返回新的数据
### 排序
##方法一:使用heapq.nlargest()和heapq.nsmallest()方法实现
heapq.nXXXest(num, set, key)
- num:表示返回数据的个数
- set:表示要处理的序列(当然集合最好,没有重复元素)
- key:表示排序规则
##方法二: 使用heappop()可以弹出heap中的数据。此时,弹出的数据就是排序后的数据
lst = []
while heap:
lst.append(heapq.heappop(heap))
print(lst) # [2, 3, 5, 7, 9, 10, 12, 14, 16, 23]对heapq使用排序场合给出几点建议:
- 查找(排序)元素个数相对序列较小时,函数 nlargest()和 nsmallest()是最佳选择
- 查找序列唯一的最小、最大的元素,推荐使用min()和max()函数最快
- 查找(排序)元素个数和序列个数接近时,先排序、再切片,这样会更快
* 和 ** 运算符
算数运算
# * 代表乘法
# ** 代表乘方
>>> 2 * 5
10
>>> 2 ** 5
32函数形参
*args 和 **kwargs 主要用于函数定义
可以将不定数量的参数传递给一个函数. 不定的意思是:预先并不知道, 函数使用者会传递多少个参数给你, 所以在这个场景下使用这两个关键字. 其实并不是必须写成 *args 和 *kwargs. (星号) 才是必须的. 你也可以写成 *ar 和 k. 而写成 *args 和kwargs 只是一个通俗的命名约定.
python函数传递参数的方式有两种:
- 位置参数(positional argument)
- 关键词参数(keyword argument)
*args 与 **kwargs 的区别, 两者都是 python 中的可变参数:
- *args 表示任何多个无名参数, 它本质是一个 tuple
- **kwargs 表示关键字参数, 它本质上是一个 dict
如果同时使用 *args 和 **kwargs 时, 必须 *args 参数列要在 **kwargs 之前
def fun(*args, **kwargs):
print('args=', args)
print('kwargs=', kwargs)
fun(1, 2, 3, 4, A='a', B='b', C='c', D='d')
# args= (1, 2, 3, 4)
# kwargs= {'A': 'a', 'B': 'b', 'C': 'c', 'D': 'd'}使用 *args
def fun(name, *args):
print('你好:', name)
for i in args:
print("你的宠物有:", i)
fun("Geek", "dog", "cat")
# 你好: Geek
# 你的宠物有: dog
# 你的宠物有: cat使用 **kwargs
def fun(**kwargs):
for key, value in kwargs.items():
print("{0} 喜欢 {1}".format(key, value))
fun(Geek="cat", cat="box")
# Geek 喜欢 cat
# cat 喜欢 box函数实参
如果函数的形参是定长参数, 也可以使用 *args 和 **kwargs 调用函数, 类似对元组和字典进行解引用:
def fun(data1, data2, data3):
print("data1: ", data1)
print("data2: ", data2)
print("data3: ", data3)
args = ("one", 2, 3)
fun(*args)
# data1: one
# data2: 2
# data3: 3
kwargs = {"data3": "one", "data2": 2, "data1": 3}
fun(**kwargs)
# data1: 3
# data2: 2
# data3: one序列解包
序列解包没有 **
a, b, *c = 0, 1, 2, 3
print(a)
# 0
print(b)
# 1
print(c)
# [2,3]匿名函数
Python Anonymous/Lambda Function
double = lambda x: x * 2
print(double(5)) # 10
# same as below
def double(x):
return x * 2Lambda functions are used along with built-in functions like filter(), map() etc
With filter()
my_list = [1, 5, 4, 6, 8, 11, 3, 12]
new_list = list(filter(lambda x: (x%2 == 0) , my_list))
print(new_list) # [4, 6, 8, 12]With map()
my_list = [1, 5, 4, 6, 8, 11, 3, 12]
new_list = list(map(lambda x: x * 2 , my_list))
print(new_list) # [2, 10, 8, 12, 16, 22, 6, 24]闭包
當一個variable被使用時,會遵循 LEGB 的規則,也就是 Local、Enclosing、Global 與 Builtins
在一个内部函数中,对外部作用域的变量进行引用,(并且一般外部函数的返回值为内部函数),那么内部函数就被认为是闭包.
def startAt(x):
def incrementBy(y):
return x*y
return incrementBy注意python是可以返回一个函数的,这也是python的特性之一
维基百科中的解释:
在计算机科学中,闭包(英语:Closure),又称词法闭包(Lexical Closure)或函数闭包(function closures),是引用了自由变量的函数。这个被引用的自由变量将和这个函数一同存在,即使已经离开了创造它的环境也不例外
# print_msg是外围函数
def print_msg():
msg = "I'm closure"
# printer是嵌套函数
def printer():
print(msg)
return printer
# 这里获得的就是一个闭包
closure = print_msg()
# 输出 I'm closure
closure()- msg是一个局部变量,在print_msg函数执行之后应该就不会存在了. 但是嵌套函数引用了这个变量,将这个局部变量封闭在了嵌套函数中,这样就形成了一个闭包.
- 闭包就是引用了自有变量的函数,这个函数保存了执行的上下文,可以脱离原本的作用域独立存在 (闭包可以保存当前的运行环境 (保存函数的状态信息,使函数的局部变量信息依然可以保存下来))
装饰器
普通装饰器:
import functools
def log(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
print('call %s():' % func.__name__)
print('args = {}'.format(*args))
return func(*args, **kwargs)
return wrapper这是一个打印出方法名及其参数的装饰器
调用:
@log
def test(p):
print(test.__name__ + " param: " + p)
test("I'm a param")
### 输出:
call test():
args = I'm a param
test param: I'm a param装饰器在使用时,用了@语法, 与下面的调用方式没有区别其实:
def test(p):
print(test.__name__ + " param: " + p)
wrapper = log(test)
wrapper("I'm a param")@语法只是将函数传入装饰器函数
带参数的装饰器
装饰器允许传入参数,一个携带了参数的装饰器将有三层函数,如下所示:
import functools
def log_with_param(text):
def decorator(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
print('call %s():' % func.__name__)
print('args = {}'.format(*args))
print('log_param = {}'.format(text))
return func(*args, **kwargs)
return wrapper
return decorator
@log_with_param("param")
def test_with_param(p):
print(test_with_param.__name__)内层的decorator函数的参数func是怎么传进去的?
将其@语法去除,恢复函数调用的形式:
# 传入装饰器的参数,并接收返回的decorator函数
decorator = log_with_param("param")
# 传入test_with_param函数
wrapper = decorator(test_with_param)
# 调用装饰器函数
wrapper("I'm a param")输出结果与正常使用装饰器相同:
call test_with_param():
args = I'm a param
log_param = param
test_with_param装饰器这一语法体现了Python中函数是第一公民,函数是对象、是变量,可以作为参数、可以是返回值,非常的灵活与强大.
deque (双向队列)
创建双向队列
import collections
d = collections.deque()append(往右边添加一个元素)
import collections
d = collections.deque()
d.append(1)
d.append(2)
print(d)
#输出:deque([1, 2])appendleft(往左边添加一个元素)
import collections
d = collections.deque()
d.append(1)
d.appendleft(2)
print(d)
#输出:deque([2, 1])clear(清空队列)
import collections
d = collections.deque()
d.append(1)
d.clear()
print(d)
#输出:deque([])copy(浅拷贝)
import collections
d = collections.deque()
d.append(1)
new_d = d.copy()
print(new_d)
#输出:deque([1])count(返回指定元素的出现次数)
import collections
d = collections.deque()
d.append(1)
d.append(1)
print(d.count(1))
#输出:2extend(从队列右边扩展一个列表的元素)
import collections
d = collections.deque()
d.append(1)
d.extend([3,4,5])
print(d)
#输出:deque([1, 3, 4, 5])extendleft(从队列左边扩展一个列表的元素)
import collections
d = collections.deque()
d.append(1)
d.extendleft([3,4,5])
print(d)
#
# #输出:deque([5, 4, 3, 1])index(查找某个元素的索引位置)
import collections
d = collections.deque()
d.extend(['a','b','c','d','e'])
print(d)
print(d.index('e'))
print(d.index('c',0,3)) #指定查找区间
#输出:deque(['a', 'b', 'c', 'd', 'e'])
# 4
# 2insert(在指定位置插入元素)
import collections
d = collections.deque()
d.extend(['a','b','c','d','e'])
d.insert(2,'z')
print(d)
#输出:deque(['a', 'b', 'z', 'c', 'd', 'e'])pop(获取最右边一个元素,并在队列中删除)
import collections
d = collections.deque()
d.extend(['a','b','c','d','e'])
x = d.pop()
print(x,d)
#输出:e deque(['a', 'b', 'c', 'd'])popleft(获取最左边一个元素,并在队列中删除)
import collections
d = collections.deque()
d.extend(['a','b','c','d','e'])
x = d.popleft()
print(x,d)
#输出:a deque(['b', 'c', 'd', 'e'])remove(删除指定元素)
import collections
d = collections.deque()
d.extend(['a','b','c','d','e'])
d.remove('c')
print(d)
#输出:deque(['a', 'b', 'd', 'e'])reverse(队列反转)
import collections
d = collections.deque()
d.extend(['a','b','c','d','e'])
d.reverse()
print(d)
#输出:deque(['e', 'd', 'c', 'b', 'a'])rotate(把右边元素放到左边)
import collections
d = collections.deque()
d.extend(['a','b','c','d','e'])
d.rotate(2) #指定次数,默认1次
print(d)
#输出:deque(['d', 'e', 'a', 'b', 'c'])sort和sorted
- sorted() 函数对所有可迭代的对象进行排序操作, 产生一个新的列表
sort() 函数在原位重新排列列表, 如果指定参数, 则使用比较函数指定的比较函数
>>> list1=[(8, 'Logan', 20), (2, 'Mike', 22), (5, 'Lucy', 19)] >>> list1.sort(key=lambda x:x[2]) >>> list1 [(5, 'Lucy', 19), (8, 'Logan', 20), (2, 'Mike', 22)] >>> a=[1,2,5,3,9,4,6,8,7,0,12] >>> a.sort(reverse=True) >>> a [12, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0]内部实现机制为:Timesort
最坏时间复杂度为:O(n log n)
空间复杂度为:O(n)
Timsort
结合了合并排序(merge sort)和插入排序(insertion sort)而得出的排序算法. 该算法找到数据中已经排好序的块/分区,每一个分区叫一个run,然后按规则合并这些run.
https://www.cnblogs.com/clement-jiao/p/9243066.html
why left+(right-left)/2 will not overflow?
在二分法中常见left+(right-left)//2, 所以就想问为什么不直接(right+left)//2??
因为后一种的最大值是 right+left 可能它过大而导致overflow, 但是前一种的最大值就是right, 保证确定不会overflow
You have left < right by definition.
As a consequence, right - left > 0, and furthermore left + (right - left) = right (follows from basic algebra).
And consequently left + (right - left) / 2 <= right. So no overflow can happen since every step of the operation is bounded by the value of right.
Python 位运算符
按位运算符是把数字看作二进制来进行计算的
a = 0011 1100
b = 0000 1101
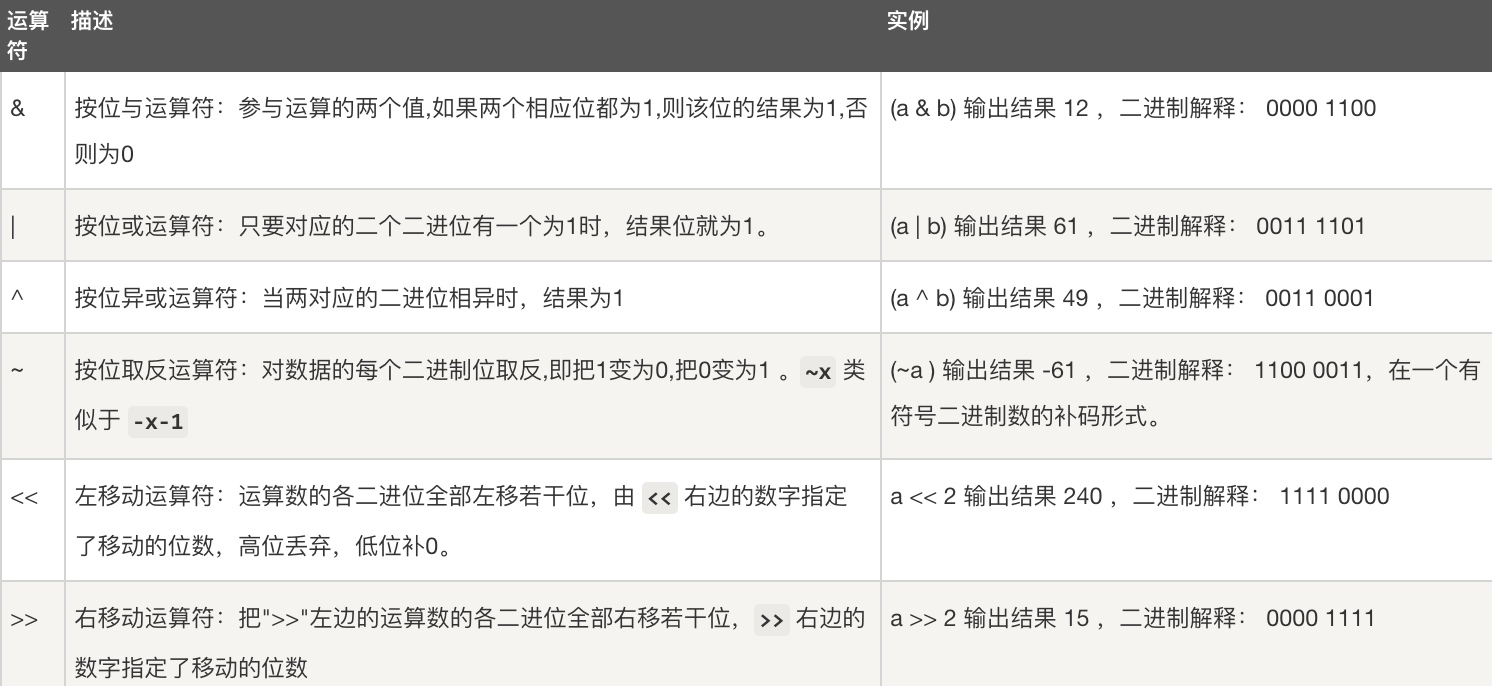
a>>=2等价于a=a>>2(右移2位)
a = 60 # 60 = 0011 1100
b = 13 # 13 = 0000 1101
c = 0
c = a & b; # 12 = 0000 1100
c = a | b; # 61 = 0011 1101
c = a ^ b; # 49 = 0011 0001
c = ~a; # -61 = 1100 0011
c = a << 2; # 240 = 1111 0000
c = a >> 2; # 15 = 0000 1111Python copy & deepcopy
import copy
if __name__ == '__main__':
a = [1, 2, 3, 4]
b = copy.copy(a)
c = copy.deepcopy(a)
e = a
print(a == b) # True 说明 a 和 b 所指向的对象的内容相同
print(a is b) # False 说明 a 和 b 所指向的不是同一个对象(地址不同)
print(a == c) # True 说明 a 和 c 所指向的对象的内容相同
print(a is c) # False 说明 a 和 c 所指向的不是同一个对象(地址不同)
print(a == e) # True 说明 a 和 e 所指向的对象的内容相同
print(a is e) # True 说明 a 和 e 所指向的是同一个对象(地址相同)对于简单对象(普通元素如数字,字符串..)来说, 深复制和浅复制的执行结果是一样的,并没有什么差别.
而复杂对象可以理解为另外包含其他简单对象的对象,也就是包含子对象的对象,例如:List中嵌套List,或者Dict中嵌套List等, 其拷贝:
import copy
if __name__ == '__main__':
a = {'name': 'test', 'age': 56, 'address': [1, 2, 3, 4, 5]}
b = copy.copy(a)
print(a is b) # False 说明 a 和 b 不是同一个对象的引用
print(a['address'] is b['address']) # True 说明 a中的address 和 b 中的 address 是同一个对象
c = copy.deepcopy(a)
print(a is c) # False 说明 a 和 c 不是同一个对象的引用
print(a['address'] is c['address']) # False 说明 a中的address 和 c 中的 address 不是同一个对象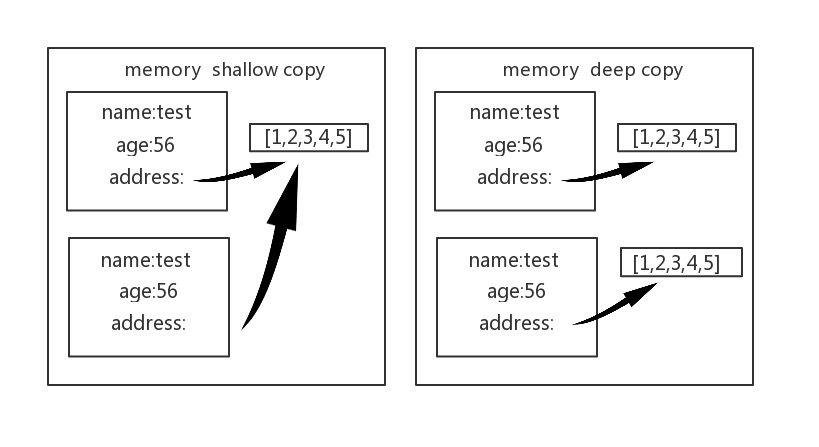
Python 内置函数
all()
all() 函数用于判断给定的可迭代参数 iterable 中的所有元素是否都为 TRUE,如果是返回 True,否则返回 False。
all(iterable)
# example
>>> all(['a', 'b', 'c', 'd']) # 列表list,元素都不为空或0
True
>>> all(['a', 'b', '', 'd']) # 列表list,存在一个为空的元素
False
>>> all([0, 1,2, 3]) # 列表list,存在一个为0的元素
False
>>> all([]) # 空列表
True
>>> all(()) # 空元组
True