Misc
Link
如何构建优秀的 API: 设计一个优秀的 RESTful API 的注意事项,以及 REST 和 GraphQL 两种 API 的差异
Microservices & Nameko Python 微服务实践
All Algorithms implemented in Python
python DP
- https://blog.csdn.net/asd136912/article/details/78987624
- https://blog.csdn.net/bailang_zhizun/article/details/80538774
- https://www.jb51.net/article/141362.htm
Statistical learning methods, 统计学习方法(李航)
Restful API
- API:顾名思义(Application Programming Interface)是一组编程接口规范, 客户端与服务端通过请求响应进行数据通信.
- REST(Representational State Transfer)决定了接口的形式与规则. RESTful是基于http方法的API设计风格, 而不是一种新的技术. 要达到的效果就是:
- 看URI就知道需要什么资源
- 看http method方法就知道针对资源做什么动作
- 看http 状态码就知道动作的结果如何
- 对接口开发提供了一种可以广泛适用的规范; 为前端后端交互减少了接口交流的口舌成本; 是约定大于配置的体现
- 用RESTful风格的目的是为大家提供统一标准, 避免不必要的沟通成本的浪费, 形成一种通用的风格
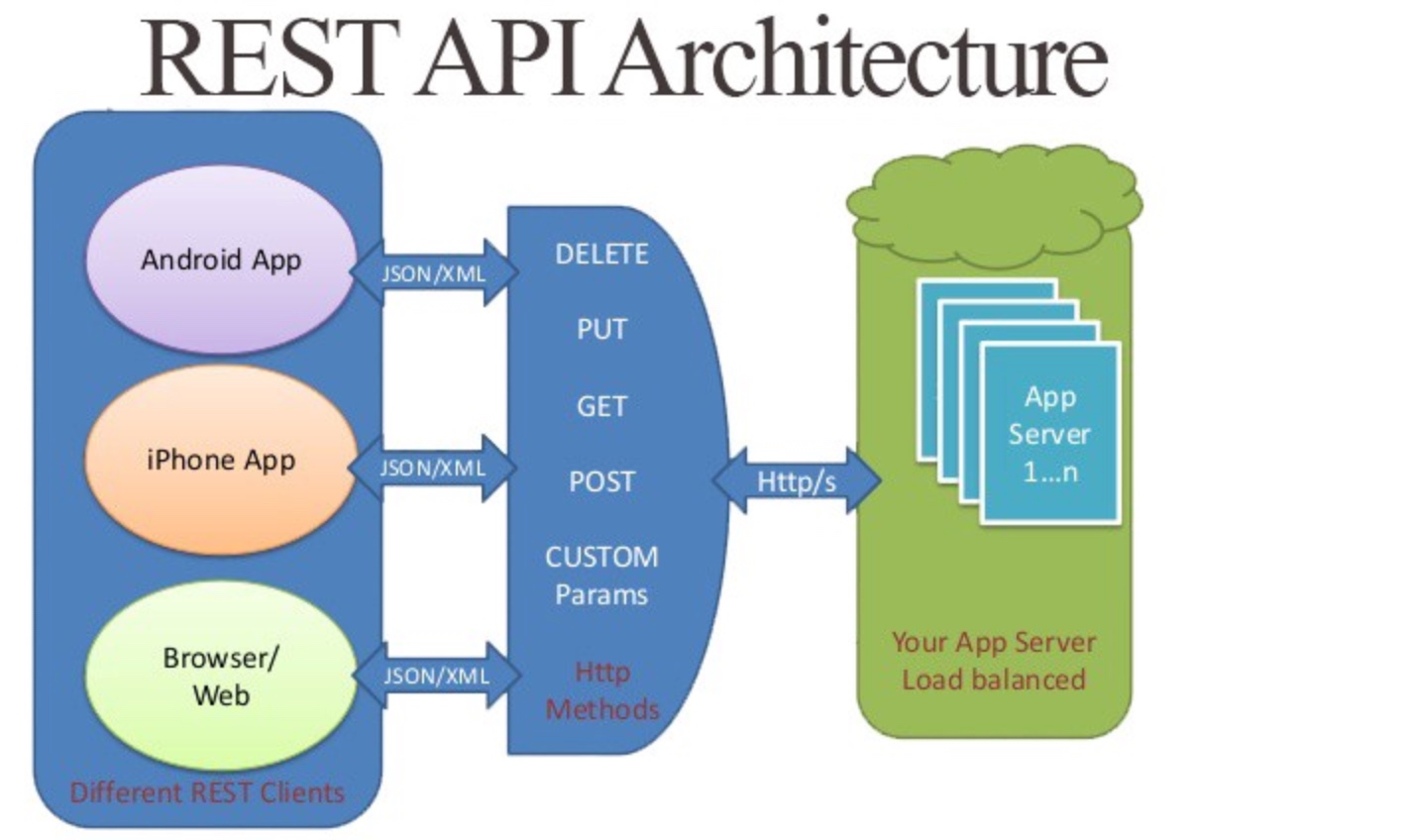
REST 架构, 核心做了两件事情:
- 资源定位
- 资源操作 (CRUD)
REST 是面向资源的, RESTful API 通过 URI 对外暴露资源时, 规范的做法是不要在 URI 中出现动词:
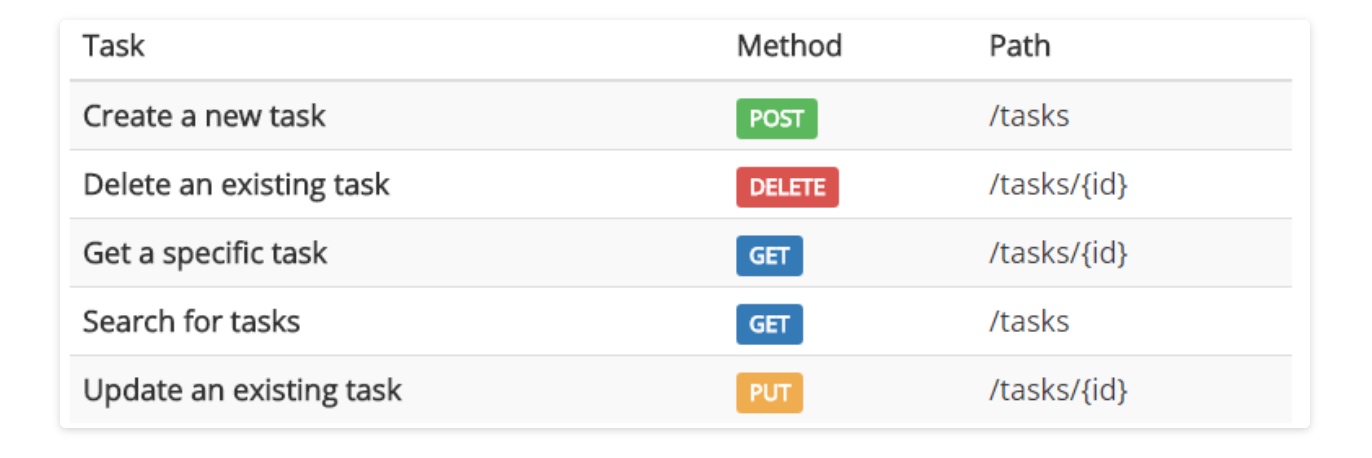
用HTTP方法体现对资源的操作:
- GET to retrieve a resource (获取、读取资源)
- PUT to change the state of or update a resource, which can be an object, file and blocks (修改资源)
- POST to create that resource (添加资源)
- DELETE to remove it (删除资源)
HTTP状态码 通过HTTP状态码体现动作的结果, 不要自定义:
- 200 OK - [GET]:服务器成功返回用户请求的数据, 该操作是幂等的(Idempotent).
- 201 CREATED - [POST/PUT/PATCH]:用户新建或修改数据成功.
- 202 Accepted - [*]:表示一个请求已经进入后台排队(异步任务)
- 204 NO CONTENT - [DELETE]:用户删除数据成功.
- 400 INVALID REQUEST - [POST/PUT/PATCH]:用户发出的请求有错误, 服务器没有进行新建或修改数据的操作, 该操作是幂等的.
- 401 Unauthorized - [*]:表示用户没有权限(令牌、用户名、密码错误).
- 403 Forbidden - [*] 表示用户得到授权(与401错误相对), 但是访问是被禁止的.
- 404 NOT FOUND - [*]:用户发出的请求针对的是不存在的记录, 服务器没有进行操作, 该操作是幂等的.
- 406 Not Acceptable - [GET]:用户请求的格式不可得(比如用户请求JSON格式, 但是只有XML格式).
- 410 Gone -[GET]:用户请求的资源被永久删除, 且不会再得到的.
- 422 Unprocesable entity - [POST/PUT/PATCH] 当创建一个对象时, 发生一个验证错误.
- 500 INTERNAL SERVER ERROR - [*]:服务器发生错误, 用户将无法判断发出的请求是否成功.
例子:
一般http的写法:
[POST] http://jane.com/garage/addCar
body:{"brand":"ford","model":"focus","price":"120000"}
[POST] http://jane.com/garage/udpateCar?id=123
body:{"brand":"ford","model":"focus","price":"130000"}
[GET] http://jane.com/garage/queryCarList
[GET] http://jane.com/garage/queryCarSingle?id=123
[GET] http://jane.com/garage/deleteCar?id=123按照restful规范设计的接口的写法:
[POST] http://jane.com/garage/cars
body:{"brand":"ford","model":"focus","price":"120000"}
[PUT] http://jane.com/garage/cars/123
body:{"brand":"ford","model":"focus","price":"130000"}
[GET] http://jane.com/garage/cars
[GET] http://jane.com/garage/cars/123
[DELETE] http://jane.com/garage/cars/123问:
- 平时get, post就可以处理所有, 为什么要用delete, put?
- 新增用户不能用/addCar?
- 删除用户不能用/deleteCar吗?
答:
- URL的定义, 叫做统一资源定位符, 也就是说url是用来表示资源在互联网上的位置的, 所以说在url中不应该包含动词, 只能包含名词
- 在第一种写法中, url丢失了资源的位置
- deleteCar又可以是eraseCar, removeCar… 具体什么含义只有设计这个api的人才能说清楚. 但是delete, 一看就知道是要删除资源
- 方便权限控制, 可以在代理或者防火墙上设置策略, 禁止某些资源的修改及删除操作, 而这显然是自定义的url所达不到的
但是, 总有一些场景是CRUD所抽象不了的, 例如用户登入, 所以建议设计:
[POST] /login
[DELETE] /logout把用户在远程服务器的会话信息抽象为一个资源, 这样的话, 登陆其实就是在远程服务器增加了一个会话资源, 登出就是在远程服务器删除了一个会话资源.
使用规范:
- 应该尽量将API部署在专用域名之下
https://api.example.comorhttps://api.example.com/api/ - 应该将API的版本号放入URL
https://api.example.com/v1/ 过滤信息(Filtering)
?limit=10:指定返回记录的数量 ?offset=10:指定返回记录的开始位置. ?page=2&per_page=100:指定第几页, 以及每页的记录数. ?sortby=name&order=asc:指定返回结果按照哪个属性排序, 以及排序顺序. ?animal_type_id=1:指定筛选条件
返回结果 - 针对不同操作, 服务器向用户返回的结果应该符合以下规范:
GET /collection:返回资源对象的列表(数组) GET /collection/resource:返回单个资源对象 POST /collection:返回新生成的资源对象 PUT /collection/resource:返回完整的资源对象 PATCH /collection/resource:返回完整的资源对象 DELETE /collection/resource:返回一个空文档
RESTful API最好做到Hypermedia, 即返回结果中提供链接, 连向其他API方法, 使得用户不查文档, 也知道下一步应该做什么
比如, 当用户向api.example.com的根目录发出请求, 会得到这样一个文档
{"link": { "rel": "collection https://www.example.com/zoos", "href": "https://api.example.com/zoos", "title": "List of zoos", "type": "application/vnd.yourformat+json" }}上面代码表示, 文档中有一个link属性, 用户读取这个属性就知道下一步该调用什么API了. rel表示这个API与当前网址的关系(collection关系, 并给出该collection的网址), href表示API的路径, title表示API的标题, type表示返回类型
API的身份认证应该使用OAuth 2.0框架
ref:
- https://www.jianshu.com/p/9bb7e6c683a3
- https://developer.github.com/v3/
- https://searchapparchitecture.techtarget.com/definition/open-API-public-API
RPC vs REST vs GraphQL
RPC
RPC是Remote Procedure Call(远程过程调用)的简称. 一般基于RPC协议所设计的接口, 是基于网络采用客户端/服务端的模式完成调用接口的. 简单来说就是从一台机器(客户端)上通过参数传递的方式调用另一台机器(服务器)上的一个函数或方法(可以统称为服务)并得到返回的结果.
XML-RPC, 通过XML将调用函数封装, 并使用HTTP协议作为传送机制. PRC慢慢演变成为今日的SOAP协定(被取代).
优点:
- 简单并且易于理解(面向开发者)
- 轻量级的数据载体
- 高性能
缺点:
- 对于系统本身耦合性高
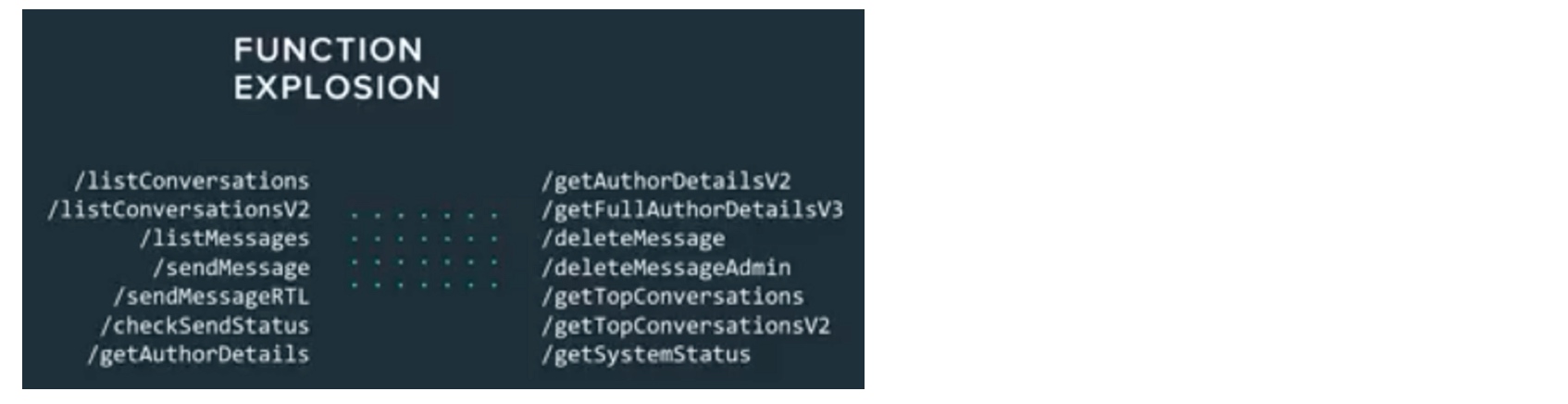
- 因为RPC本身很简单、轻量, 因此很容易造成 function explosion
对于接口提供者来说, 因为它的高耦合性, 所以它性能高同时又很简单
但是如果从接口调用者的角度来看, 高耦合性就变成了缺点, 因为高耦合意味着调用者必须要足够了解系统本身的实现才能够完成调用, 比如:
- 调用者需要知道所调用接口的函数名、参数格式、参数顺序、参数名称等等
- 如果接口提供者(server)要对接口做出一些改变, 很容易对接口调用者(client)造成breaking change(违背开闭原则)
- 一般RPC所暴露接口仅仅会暴露函数的名称和参数等信息, 对于函数之间的调用关系无法提供, 这意味着调用者必须足够了解系统, 从能够知道如何正确的调用这些接口, 但是对于接口调用者往往不需要了解过多系统内部实现细节
关于上面的第二点, 为了减少breaking change, 有的人实现接口的时候会引入版本, 就是在暴露接口的方法名中加入版本号, 一开始效果确实不错, 但是随后就不知不觉的形成了function explosion:
REST
当前REST风格的API架构方式已经成了主流解决方案了, 相比较RPC, 它的主要不同之处在于, 它是对于资源(Resource)的模型化而非步骤(Procedure)
优点:
- 对于系统本身耦合性低, 调用者不再需要了解接口内部处理和实现细节
- 重复使用了一些 http 协议中的已定义好的部分状态动词, 增强语义表现力
- API可以随着时间而不断演进
缺点:
- 缺少约束, 缺少简单、统一的规范
- 有时候 payload 会变的冗余(overload), 有时候调用api会比较繁琐(chattiness)
- 有时候需要发送多条请求已获取数据, 在网络带宽较低的场景, 往往会造成不好的影响
REST的优点基本解决了RPC中存在的问题, 就是解耦, 从而使得前后端分离成为可能. 接口提供者在修改接口时, 不容易造成breaking-change, 接口调用者在调用接口时, 往往面向数据模型编程, 而省去了了解接口本身的时间成本.
REST当前最大的问题在于虽然它利用http的动词约束了接口的暴露方式, 同时增强了语义, 但是却没有约束接口如何返回数据的最佳实践, 总让人感觉只要是返回json格式的接口都可以称作REST.
实际工作中, 经常会遇到第二条缺点所指出的问题, 就是接口返回的数据冗余度很高, 但是却缺少开发者真正需要的数据, 因此不得已只能调用其他接口或者直接和后端商议修改接口, 并且这种问题会在web端和移动端共用一套接口中被放大.
当前比较好的解决方案就是规范化返回数据的格式, 比如json-schema或者自己制定的规范.
GraphQL
GraphQL是近来比较热门的一个技术话题, 相比REST和RPC, 它汲取了两者的优点, 即不面向资源, 也不面向过程, 而是面向数据查询(ask for exactly what you want). 同时GraphQL本身需要使用强类型的Schema来对数据模型进行定义, 因此相比REST它的约束性更强.
优点:
- 网络开销低, 可以在单一请求中获取REST中使用多条请求获取的资源
- 强类型Schema(约束意味着可以根据规范形成文档、IDE、错误提示等生态工具)
- 特别适合图状数据结构的业务场景(比如好友、流程、组织架构等系统)
缺点:
- 本身的语法相比较REST和RPC均复杂一些
- 实现方面需要配套 Caching 以解决性能瓶颈
- 对于 API 的版本控制当前没有完善解决方案(社区的建议是不要使API版本化)
- 技术较新, 很多细节仍然处于待验证状态
在某些程度上确实解决了REST的缺点所带来的问题, 同时配套社区建议的各种工具和库, 相比使用REST风格, 全栈开发体验更好.
GraphQL之所以没有大火的原因是它所带来的好处, 大部分是对于接口调用者而言的, 但是实现这部分的工作却需要接口提供者来完成.
同时GraphQL的最佳实践场景应当是类似像Facebook这样的网站, 业务逻辑模型是图状数据结构, 比如社交. 如果在一些业务逻辑模型相对简单的场景, 使用GraphQL确实不如使用REST来得简单明了直截.
另外一方面是GraphQL的使用场景相当灵活, 可以把它当做一个类似ORM的框架来使用的, 或者把它当做一个中间层来做渐进式开发和系统升级.
Application
应用场景:
如果是Management API, 这类API的特点如下:
- 关注于对象与资源
- 会有多种不同的客户端
- 需要良好的可发现性和文档
这种情景使用REST + JSON API可能会更好
如果是Command or Action API, 这类API的特点如下:
- 面向动作或者指令
- 仅需要简单的交互
这种情况使用RPC就足够了
如果是Internal Micro Services API, 这类API的特点如下:
- 消息密集型
- 对系统性能有较高要求
这种情景仍然建议使用RPC
如果是Micro Services API, 这类API的特点如下:
- 消息密集型
- 期望系统开销较低
这种情景使用RPC或者REST均可
如果是Data or Mobile API, 这类API的特点是:
- 数据类型是具有图状的特点
- 希望对于高延迟场景可以有更好的优化
这种场景无疑GraphQL是最好的选择
总览它们之间在不同指标下的表现:
| 耦合性 | 约束性 | 复杂度 | 缓存 | 可发现性 | 版本控制 | |
|---|---|---|---|---|---|---|
| RPC(Function) | high | medium | low | custom | bad | hard |
| REST(Resource) | low | low | low | http | good | easy |
| GraphQL(Query) | medium | high | medium | custom | good | ??? |
最后引用人月神话中的观点no silver bullet, 在技术选型时需要具体情况具体分析, 不过鉴于GraphQL的灵活性, 把它与RPC和REST配置使用, 也是不错的选择.
SOAP
- The most common open API architectures fall into two categories: REST APIs and SOAP APIs
- SOAP-based APIs typically use XML as a data exchange format, while RESTful APIs typically use JSON back and forth
- The current trend in the industry is largely toward REST APIs and away from SOAP-based APIs
- SOAP(Simple Object Access Protocol) 可以认为是XML-PRC的加强版本, 基本格式仍然是xml, 但封装的更加完美, 支持的数据类型更多, 可以支持对象和容器.
- 随着 SOA (Service Oriented Architecture) 的走红, 提倡将一个大的软件拆分成多个不同的小的服务, SOAP 在服务之间的远程调用大有用武之地.
- SOAP的消息是基于xml并封装成了符合http协议, 因此, 它符合任何路由器、 防火墙或代理服务器的要求.
- SOAP要用于Web服务(web service)中并可以使用任何语言来完成(跨语言), 只要发送正确的soap请求即可, 基于soap的服务可以在任何平台无需修改即可正常使用(跨平台).
- 例子: 一个 SOAP 消息可以发送到一个具有 Web Service 功能的 Web 站点
- 例如, 一个含有房价信息的数据库, 消息的参数中标明这是一个查询消息, 此站点将返回一个 XML 格式的信息, 其中包含了查询结果(价格, 位置, 特点, 或者其他信息). 由于数据是用一种标准化的可分析的结构来传递的, 所以可以直接被第三方站点所利用
- 例子: 一个 SOAP 消息可以发送到一个具有 Web Service 功能的 Web 站点
优点:
- 协议约定面向对象, 更贴合业务逻辑的应用场景
- 服务定义清楚, 在 WSDL 能清楚了解到所有服务
- 格式不用完全一致, 比如上面那个请求里 name, type, priority 的顺序不用完全跟服务端的 WSDL 对应. 版本更新上, 客户端可以先增加新的项, 服务端可以之后再更新
- 使用 WS Security 所为安全标准, 安全性较高
- SOAP 是 面向动作 的, 支持比较复杂的动作, 可以在 XML 里放动作, 比如 ADD, MINUS
缺点:
- 远程调用速度慢, 效率低. 因为以 XML 作为数据格式, 除了主要传输的数据之外, 有较多冗余用在定义格式上, 占用带宽, 并且对于 XML 的序列化和解析的速度也比较慢
- 协议约定 WSDL 比较复杂, 要经过好几个环节才能搞定
- SOAP 多数用的是 POST, 而 HTTP 有 GET, DELETE, PUT 等很多别的方法, 通常是 POST 加上动作, 比如 POST CreateTask, POST DeleteTask. 而多数用 POST 的原因是 GET 请求最大长度限制较多, 而 SOAP 需要把数据加上 SOAP 标准化的格式, 请求数据比较大, 超过 GET 的限制.
- SOAP 的业务状态大多是维护在服务端的, 比如说分页, 服务端会记住用户在哪个页面上, 在企业软件中, 客户端和服务端比较平衡的情况下是没有问题的, 但是在失衡情况下, 比如说客户端请求大大超过服务端时, 服务端维护所有状态的成本太高, 影响并发量
SOA
SOA(Service-Oriented Architecture)面向服务的架构.
SOA提倡将不同应用程序的业务功能封装成”服务”, 通常以接口和契约的形式暴露并提供给外界应用访问(通过交换消息), 达到不同系统可重用的目的.
SOA是一个组件模型, 它能将不同的服务通过定义良好的接口和契约联系起来, 服务是SOA的基石.
Difference between microservice and SOA
微服务是SOA架构演进的结果. 两者说到底都是对外提供接口的一种架构设计方式,随着互联网的发展, 复杂的平台、业务的出现, 导致SOA架构向更细粒度、更通过化程度发展, 就成了所谓的微服务.
微服务是SOA发展出来的产物, 它是一种比较现代化的细粒度的SOA实现方式
SOA与微服务的区别在于如下几个方面:
- 微服务相比于SOA更加精细, 微服务更多的以独立的进程的方式存在, 互相之间并无影响;
- 微服务提供的接口方式更加通用化, 例如HTTP RESTful方式, 各种终端都可以调用, 无关语言、平台限制;
- 微服务更倾向于分布式去中心化的部署方式, 在互联网业务场景下更适合
Why microservice
技术和架构都是为业务而生, 而出现SOA和微服务框架也与业务的发展、平台的壮大密不可分.
- 单一应用架构
- 当网站流量很小时, 只需一个应用, 将所有功能都部署在一起, 以减少部署节点和成本
- 此时, 用于简化增删改查工作量的 数据访问框架(ORM) 是关键
- 垂直应用架构
- 当访问量逐渐增大, 单一应用增加机器带来的加速度越来越小, 将应用拆成互不相干的几个应用, 以提升效率 (分成web, app, db server)
- 此时, 用于加速前端页面开发的 Web框架(MVC) 是关键
- 分布式服务架构
- 当垂直应用越来越多, 应用之间交互不可避免, 将核心业务抽取出来, 作为独立的服务, 逐渐形成稳定的服务中心, 使前端应用能更快速的响应多变的市场需求
- 此时, 用于提高业务复用及整合的 分布式服务框架(RPC) 是关键
- 流动计算架构
- 当服务越来越多, 容量的评估, 小服务资源的浪费等问题逐渐显现, 此时需增加一个调度中心基于访问压力实时管理集群容量, 提高集群利用率
- 此时, 用于提高机器利用率的 资源调度和治理中心(SOA) 是关键
平台随着业务的发展从 All in One 环境就可以满足业务需求, 发展到需要拆分多个应用, 并且采用MVC的方式分离前后端, 加快开发效率;在发展到服务越来越多, 不得不将一些核心或共用的服务拆分出来, 其实发展到此阶段, 如果服务拆分的足够精细, 并且独立运行, 就可以将之理解为一个微服务了.
Microservice & Docker
- 环境配置的难题
- 软件开发最大的麻烦事之一, 就是环境配置 (用户计算机的环境都不相同)
- 用户必须保证两件事:操作系统的设置, 各种库和组件的安装 ==> 软件才能运行. E.g.一个 Python 应用, 计算机必须有 Python 引擎, 还必须有各种依赖, 可能还要配置环境变量
- 常常出现一些老旧的模块与当前环境不兼容的情况, “它在我的机器可以跑了”(It works on my machine), 言下之意就是, 其他机器很可能跑不了
- 虚拟机
- 虚拟机(virtual machine)就是带环境安装的一种解决方案. 它可以在一种操作系统里面运行另一种操作系统, 比如在 Windows 系统里面运行 Linux 系统. 应用程序对此毫无感知, 因为虚拟机看上去跟真实系统一模一样, 而对于底层系统来说, 虚拟机就是一个普通文件, 不需要了就删掉, 对其他部分毫无影响
- 缺点:
- 资源占用多: 虚拟机会独占一部分内存和硬盘空间. 它运行的时候, 其他程序就不能使用这些资源了. 哪怕虚拟机里面的应用程序, 真正使用的内存只有 1MB, 虚拟机依然需要几百 MB 的内存才能运行
- 冗余步骤多: 虚拟机是完整的操作系统, 一些系统级别的操作步骤, 往往无法跳过, 比如用户登录
- 启动慢: 启动操作系统需要多久, 启动虚拟机就需要多久. 可能要等几分钟, 应用程序才能真正运行
- Linux 容器
- 由于虚拟机存在这些缺点, Linux 发展出了另一种虚拟化技术:Linux 容器(Linux Containers, 缩写为 LXC)
- Linux 容器不是模拟一个完整的操作系统, 而是对进程进行隔离. 或者说, 在正常进程的外面套了一个保护层. 对于容器里面的进程来说, 它接触到的各种资源都是虚拟的, 从而实现与底层系统的隔离
- 由于容器是进程级别的, 相比虚拟机有很多优势:
- 启动快: 容器里面的应用, 直接就是底层系统的一个进程, 而不是虚拟机内部的进程. 所以, 启动容器相当于启动本机的一个进程, 而不是启动一个操作系统, 速度就快很多
- 资源占用少: 容器只占用需要的资源, 不占用那些没有用到的资源;虚拟机由于是完整的操作系统, 不可避免要占用所有资源. 另外, 多个容器可以共享资源, 虚拟机都是独享资源
- 体积小: 容器只要包含用到的组件即可, 而虚拟机是整个操作系统的打包, 所以容器文件比虚拟机文件要小很多.
- 总之, 容器有点像轻量级的虚拟机, 能够提供虚拟化的环境, 但是成本开销小得多
- Docker
- Docker 属于 Linux 容器的一种封装, 提供简单易用的容器使用接口. 它是目前最流行的 Linux 容器解决方案
- Docker 将应用程序与该程序的依赖, 打包在一个文件里面. 运行这个文件, 就会生成一个虚拟容器. 程序在这个虚拟容器里运行, 就好像在真实的物理机上运行一样. 有了 Docker, 就不用担心环境问题
- 总体来说, Docker 的接口相当简单, 用户可以方便地创建和使用容器, 把自己的应用放入容器. 容器还可以进行版本管理、复制、分享、修改, 就像管理普通的代码一样
- Docker 与 微服务
- Docker 是一个容器工具, 提供虚拟环境
- 站在 Docker 的角度, 软件就是容器的组合:业务逻辑容器、数据库容器、储存容器、队列容器……Docker 使得软件可以拆分成若干个标准化容器, 然后像搭积木一样组合起来
- 这正是微服务(microservices)的思想:软件把任务外包出去, 让各种外部服务完成这些任务, 软件本身只是底层服务的调度中心和组装层
- 微服务很适合用 Docker 容器实现, 每个容器承载一个服务. 一台计算机同时运行多个容器, 从而就能很轻松地模拟出复杂的微服务架构
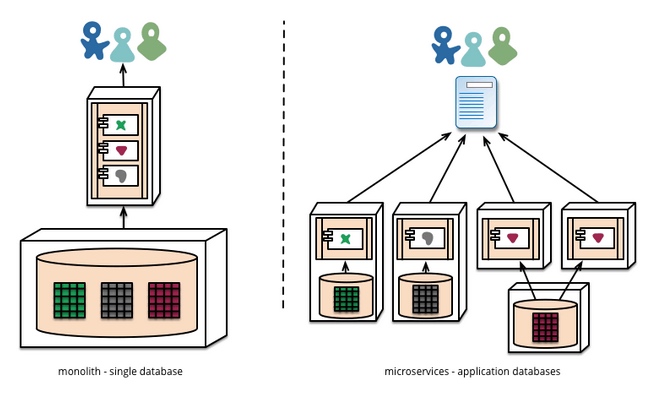
Open vs. closed APIs
- Closed APIs are private. This privacy is different from the form of security found in open APIs.
- An open API has access restrictions because they are openly accessible to the public and can be invoked from anywhere on the open internet (OpenAPI虽然有访问限制, 但是可以从任何公用网络调用)
- While a closed API is not accessible openly on the internet. Accessing a closed API normally requires making calls through highly restrictive firewalls or a VPN service, if any external access is allowed at all (ClosedAPI只有内部网络可以调用, 要经过严格的VPN或者firewall)
- Since closed APIs typically reside in highly secure environments, they often do not employ any form of user authentication at all, as it is assumed that every resource making calls to them originates from within a secured and trusted realm (ClosedAPI假设所有调用都是通过高度安全的内部网络, 所以它通常不需要用户权限验证)
- closed APIs are often used for internal services and processes, such as microservices and container orchestration tools, to communicate with each other, whereas open APIs tend to focus on delivering more user-driven services and capabilities (ClosedAPI通常用于微服务和容器(内部沟通))
Hashing & Encryption & Security
- 对称加密
- 指加密和解密使用相同密鑰的加密算法
- 假設兩個用戶需要使用對稱加密方法加密然後交換數據,則用戶最少需要 2 個密鑰並交換使用,如果企業內用戶有 n 個,則整個企業共需要 n×(n-1) 個密鑰,密鑰的生成和分發將十分恐怖
- 特点:
- 加密,解密的高速度
- 使用長密鑰時的難破解性高
- 對稱加密算法的安全性取決於加密密鑰的保存情況
- 常見的對稱加密算法:DES, 3DES, DESX, Blowfish, IDEA, RC4, RC5, RC6, AES
- 非对称加密
- 指加密和解密使用不同密鑰的加密算法,也稱爲公私鑰加密
- E.g. 兩個用戶要加密交換數據
- 乙方生成兩把密鑰,公鑰和私鑰. 公鑰是公開的,任何人都可以獲得,私鑰則是保密的
- 甲方獲取乙方的公鑰,用它對信息加密
- 乙方得到加密後的信息,用私鑰解密
- 如果企業中有 n 個用戶,企業需要生成 n 對密鑰,並分發 n 個公鑰. 由於公鑰是可以公開的,用戶只要保管好自己的私鑰即可,因此加密密鑰的分發將變得十分簡單. 同時,由於每個用戶的私鑰是唯一的,其他用戶除了可以可以通過信息發送者的公鑰來驗證信息的來源是否真實,還可以確保發送者無法否認曾發送過該信息
- 特点:
- 非對稱加密的缺點是加解密速度要遠遠慢於對稱加密,在某些極端情況下,甚至能比非對稱加密慢上 1000 倍
- 极度安全
- 常見的非對稱加密算法:RSA, ECC (移動設備用), Diffie-Hellman, El Gamal, ECDSA (數字簽名用)
- Hash 算法
- 哈希算法, 也叫摘要算法 / 线性散列算法 / 签名算法. 对任意长度的目標信息, 产生一个固定长度的输出, 这个输出叫做 哈希值, 且不能通過這個 Hash 值重新獲得目標信息
- 它是一種單向算法
- 常见的哈希算法:
- MD2, MD4, MD5, HAVAL, SHA, SHA-1, SHA-256, SHA-512, HMAC, HMAC-MD5, HMAC-SHA1, HMAC-SHA256, HMAC-SHA512
- 特点:
- 无冲突:无法找到两个不一样的输入, 产生同样的哈希值
- 不可逆:无法由输出推导输入
- 常用在不可還原的密碼存儲、信息完整性校驗等
- 客户端的密码如果以明文发送并存储在服务器有很多安全问题,比如通信的时候被截取,存在服务器后台人员能看到明文,一种方案是用客户端随机产生一个盐(密码+加盐,盐是固定的)的方式发给服务端并存储
- 加密算法的效能通常可以按照算法本身的複雜程度、密鑰長度(密鑰越長越安全)、加解密速度等來衡量. 上述的算法中,除了 DES 密鑰長度不夠、MD2 速度較慢已逐漸被淘汰外,其他算法仍在目前的加密系統產品中使用
- 数字签名
- 数字签名和传统的签名一样, 满足两个性质:
- 只有特定的人可以签, 但是所有人都可以验证
- 签名和特定的内容绑定在一起, 剪切复制是没用的
- 目前使用的数字签名一般由 非对称秘钥 实现, 有两把钥匙, 一把秘钥, 一把公钥, 公钥公之于众
- 数字签名是将摘要信息用发送者的私钥加密,与原文一起传送给接收者. 接收者只有用发送者的公钥才能解密被加密的摘要信息,然后用HASH函数对收到的原文产生一个摘要信息,与解密的摘要信息对比. 如果相同,则说明收到的信息是完整的,在传输过程中没有被修改,否则说明信息被修改过,因此数字签名能够验证信息的完整性。如果中途数据被纂改或者丢失。那么对方就可以根据数字签名来辨别是否是来自对方的第一手信息数据
- 数字签名是个加密的过程,数字签名验证是个解密的过程
- 简单来说:
- 消息发布者可以使用
秘钥 + 消息产生签名 - 其他人可以使用
公钥 + 消息 + 签名来验证有效性
- 消息发布者可以使用
- 数字签名和传统的签名一样, 满足两个性质:
- 数字证书
- 数字证书就是互联网通讯中标志通讯各方身份信息的一串数字,提供了一种在Internet上验证通信实体身份的方式,数字证书不是数字身份证,而是身份认证机构盖在数字身份证上的一个章或印(或者说加在数字身份证上的一个签名). 它是由权威机构——CA机构,又称为证书授权(Certificate Authority)中心发行的,人们可以在网上用它来识别对方的身份
- 数字证书绑定了公钥及其持有者的真实身份
- 通俗讲就是车管所会给每个车辆进行认证颁发车牌,通过车牌可以查到所有车辆和驾驶员的信,而数字证书就辨别唯一身份
- 支付宝等的数字证书就是公开的,这不是支付宝自己决定,而是由国际组织认证,这样不管是哪个用户首先就可以根据浏览器返回的证书辨别支付宝的真伪
加密算法介绍:
- 对称加密算法
- 对称加密算法用来对敏感数据等信息进行加密,常用的算法包括:
- DES(Data Encryption Standard):数据加密标准,速度较快,适用于加密大量数据的场合
- 3DES(Triple DES):是基于DES,对一块数据用三个不同的密钥进行三次加密,强度更高
- AES(Advanced Encryption Standard):高级加密标准,是下一代的加密算法标准,速度快,安全级别高;
- 非对称算法
- RSA:由 RSA 公司发明,是一个支持变长密钥的公共密钥算法,需要加密的文件块的长度也是可变的
- DSA(Digital Signature Algorithm):数字签名算法,是一种标准的 DSS(数字签名标准)
- ECC(Elliptic Curves Cryptography):椭圆曲线密码编码学
- ECC和RSA相比,在许多方面都有对绝对的优势,主要体现在以下方面:
- 抗攻击性强。相同的密钥长度,其抗攻击性要强很多倍
- 计算量小,处理速度快。ECC总的速度比RSA、DSA要快得多
- 存储空间占用小。ECC的密钥尺寸和系统参数与RSA、DSA相比要小得多,意味着它所占的存贮空间要小得多. 这对于加密算法在IC卡上的应用具有特别重要的意义
- 带宽要求低。当对长消息进行加解密时,三类密码系统有相同的带宽要求,但应用于短消息时ECC带宽要求却低得多. 带宽要求低使ECC在无线网络领域具有广泛的应用前景
- 散列算法
- 散列是信息的提炼,通常其长度要比信息小得多,且为一个固定长度. 加密性强的散列一定是不可逆的,这就意味着通过散列结果,无法推出任何部分的原始信息. 任何输入信息的变化,哪怕仅一位,都将导致散列结果的明显变化,这称之为雪崩效应. 散列还应该是防冲突的,即找不出具有相同散列结果的两条信息。具有这些特性的散列结果就可以用于验证信息是否被修改
- 单向散列函数一般用于产生消息摘要,密钥加密等,常见的有:
- MD5(Message Digest Algorithm 5):是RSA数据安全公司开发的一种单向散列算法,非可逆,相同的明文产生相同的密文。
- SHA(Secure Hash Algorithm):可以对任意长度的数据运算生成一个160位的数值;
- SHA-1与MD5的比较
- 因为二者均由MD4导出,SHA-1和MD5彼此很相似. 相应的,他们的强度和其他特性也是相似
- 对强行供给的安全性:最显著和最重要的区别是SHA-1摘要比MD5摘要长32 位. 使用强行技术,产生任何一个报文使其摘要等于给定报摘要的难度对MD5是
$2^{128}$数量级的操作,而对SHA-1则是$2^{160}$数量级的操作. 这样,SHA-1对强行攻击有更大的强度 - 对密码分析的安全性:由于MD5的设计,易受密码分析的攻击,SHA-1显得不易受这样的攻击
- 速度:在相同的硬件上,SHA-1的运行速度比MD5慢
- HMAC (Hased Message Authentication Code): 它不是散列函数,而是采用了将MD5或SHA1散列函数与共享机密秘钥(与公钥/秘钥对不同)一起使用的消息身份验证机制. 消息与秘钥组合并运行散列函数(md5或sha1),然后运行结果与秘钥组合并再次运行散列函数
- 对称与非对称算法比较
- 在管理方面:公钥密码算法只需要较少的资源就可以实现目的,在密钥的分配上,两者之间相差一个指数级别(一个是
$n$一个是$n^2$). 所以私钥密码算法不适应广域网的使用,而且更重要的一点是它不支持数字签名 - 在安全方面:由于公钥密码算法基于未解决的数学难题,在破解上几乎不可能。对于私钥密码算法,到了AES虽说从理论来说是不可能破解的,但从计算机的发展角度来看。公钥更具有优越性
- 从速度上来看:AES的软件实现速度已经达到了每秒数兆或数十兆比特. 是公钥的100倍,如果用硬件来实现的话这个比值将扩大到1000倍
- 在管理方面:公钥密码算法只需要较少的资源就可以实现目的,在密钥的分配上,两者之间相差一个指数级别(一个是
- 对称加密算法用来对敏感数据等信息进行加密,常用的算法包括:
加密算法的選擇:
- 當需要加密大量的數據時,建議採用對稱加密算法,提高加解密速度
- 因为非對稱加密算法的運行速度比對稱加密算法的速度慢很多
- 當數據量很小時,可以考慮採用非對稱加密算法
- 由於對稱加密算法的密鑰管理是一個複雜的過程,密鑰的管理直接決定着他的安全性
- 簽名只能使用非對稱算法
- 對稱加密算法不能實現簽名
- 实际/通常: 採用非對稱加密算法管理對稱算法的密鑰,然後用對稱加密算法加密數據,
- 這樣就集成了兩類加密算法的優點,既實現了加密速度快的優點,又實現了安全方便管理密鑰的優點
採用多少位的密鑰?
- 一般來說,密鑰越長,運行的速度就越慢,應該根據的實際需要的安全級別來選擇,一般來說,RSA 建議採用 1024 位的數字,ECC 建議採用 160 位,AES 採用 128 爲即可
应用:
- 保密通信:保密通信是密码学产生的动因. 使用公私钥密码体制进行保密通信时,信息接收者只有知道对应的密钥纔可以解密该信息
- 数字签名:数字签名技术可以代替传统的手写签名,而且从安全的角度考虑,数字签名具有很好的防僞造功能. 在政府机关、军事领域、商业领域有广泛的应用环境
- 秘密共享:秘密共享技术是指将一个祕密信息利用密码技术分拆成 n 个称爲共享因子的信息,分发给 n 个成员,只有 k(k≤n) 个合法成员的共享因子才可以恢复该祕密信息,其中任何一个或 m(m≤k) 个成员合作都不知道该祕密信息. 利用祕密共享技术可以控制任何需要多个人共同控制的祕密信息、命令等
- 认证功能:在公开的信道上进行敏感信息的传输,採用签名技术实现对消息的真实性、完整性进行验证,通过验证公钥证书实现对通信主体的身份验证
- 密钥管理:密钥是保密系统中更爲脆弱而重要的环节,公钥密码体制是解决密钥管理工作的有力工具;利用公钥密码体制进行密钥协商和产生,保密通信双方不需要事先共享祕密信息;利用公钥密码体制进行密钥分发、保护、密钥託管、密钥恢复等
ref: https://www.jianshu.com/p/f729ab026da2
RSA 的原理与实现
1976 年以前, 所有的加密都是如下方式:
- A 使用某种规则对信息进行处理
- B 使用同样的规则对处理过的信息进行复原
这个方式很好理解, 不论是非常简单的 ROT13 还是目前广泛使用的 AES, 都是这种对称加密方式.
但是这种方式有一个巨大的缺点, 那就是 A 需要将对信息进行处理的规则(也就是秘钥)告诉给 B. 怎样安全地传输秘钥就成了一个非常棘手的问题.
因此, 有了另一种方式, 加密和解密使用不同的秘钥, 彻底规避掉传输秘钥的问题 - RSA, 一种非对称加密方式:
- 使用算法可以生成两把钥匙 A 和 B
- 使用 A 加密的信息, 使用 B 可以解开
- 使用 B 加密的信息, 使用 A 可以解开
日常使用中, 我们把一把作为公钥, 公开发布. 一把作为私钥, 自己保留. 这样, 任何人都可以使用我们的公钥加密信息发给我们, 我们则可以使用自己的私钥解开.
只要把私钥保存好, 这个通信系统就非常安全.
数学原理
首先梳理几个概念:
互质
- 如果两个正整数, 除了 1 以外没有其他的公因数, 则他们互质. 比如, 14 和 15 互质. 注意, 两个数构成互质关系, 他们不一定需要是质数, 比如 7 和 9.
欧拉函数
$$ \phi(n) = n (1 - \frac{1}{p_1}) (1 - \frac{1}{p_2})…(1 - \frac{1}{p_n}) $$- 欧拉函数用于计算任意正整数 n , 在 <=n 的正整数中, 与 n 互质的正整数个数, 其中
$\phi(1) = 1$.- 其中,
$p_1$,$p_2$表示 n 的质因子, 重复的只算一个.
- 其中,
- 例如,
$10 = 2 \times 5$, 所以$\phi(10) = 10 (1- \frac12) (1 - \frac15) = 4$, 意味着在 <=10 的正整数中, 与 10 互质的正整数个数为 4 个. 可以验证一下, 他们分别是 1, 3, 7, 9, 一共 4 个. - 再例如,
$12 = 2 \times 2 \times 3$, 所以$\phi(12) = 12 (1 - \frac12) (1 - \frac13) = 4$.
欧拉定理和费马小定理
- 欧拉定理陈述了这样一个事实:如果两个正整数 a 和 n 互质, 则如下等式成立.
$$ a^{\phi(n)} \equiv 1 \pmod n $$- 上面公式的意思是:
$a^{\phi(n)}$减去 1 后的值可以整除 n 或者$a^{\phi(n)}$被n除的余数为1 - 例如, 7 和 10 互质,
$7^{\phi(10)} = 7^4 = 2401$, 减去 1 等于 2400, 可以整除 10. - 同样的道理,
$10^{\phi(7)} = 10^6 = 1000000$, 减去 1 等于 999999, 可以整除 7. - 欧拉定理存在一个特殊情况:如果 p 是质数, 而 a 不是 p 的倍数, 此时 a 和 p 必然互质. 因为
$\phi(p) = p - 1$, 所以 $$ a^{\phi(p)} = a^{p - 1} \equiv 1 \pmod p $$- 这就是费马小定理, 它是欧拉定理的特例.
模反元素
- 如果两个正整数 a 和 n 互质, 那么一定可以找到一个正整数 b, 使得 ab - 1 被 n 整除.
$$ ab \equiv 1 mod n $$- 这个时候, b 就叫做 a 的模反元素
- 比如, 3 和 11 互质, 3 的模反元素是 4, 因为
$(3 \times 4) - 1$可以整除 11. - 可以发现, 模反元素不止一个, 4 加减 11 的倍数都是 3 的模反元素.
- 可以用欧拉定理来证明, 模反元素一定存在.
$$ a^{\phi(n)} = a \times a^{\phi(n) - 1} \equiv 1 \pmod n $$- 可以看出,
$a^{\phi(n) - 1}$就是 a 相对 n 的模反元素.
秘钥生成
秘钥生成步骤:
- 随机选择两个大质数 p 和 q, 并计算他们的乘积 n. 在日常应用中, 出于安全考虑, 一般要求 n 换算成二进制要大于 2048 位
- 这里因为是演示, 使用比较小的数, 选择 p = 7 以及 q = 9, 所以 n = 63.
- 计算 n 的欧拉函数
$\phi(n)$- 根据公式,
$\phi(n) = (p-1)(q-1)$, 我么可以得知$\phi(63) = 6 \times 8 = 48$
- 根据公式,
- 选择一个数 e 使得 e 与
$\phi(n)$互质.- 很多文章会提到
$1 < e < \phi(n)$, 其实这并不严谨, 只是工程上的考虑, 在数学上来说, e 随便选择, 只要与$\phi(n)$互质即可 - 在日常应用中, 一般选择 65537. 选择一个已知的数字不会降低 RSA 的安全性.
- 这里选择 e = 5.
- 很多文章会提到
- 计算 e 相对
$\phi(n)$的模反元素 d. 根据上面的知识, 因为 e 和$\phi(n)$互质, 可以用如下公式计算 d$$ d = e^{\phi[\phi(n)] - 1} $$
在例子中, $\phi(n) = 48$, 可以很容易的查表得出 $\phi(48) = 16$.
但是在实际应用中, 这是不现实的, 因为 $\phi(n)$ 是一个非常大的数, 而我们没有什么办法去快速计算 $\phi[\phi(n)]$.
这里我们要换一个方式来计算 d.
因为
$$ ed \equiv 1 \pmod {\phi(n)} $$
我们可以得出
$$ ed = k\phi(n) + 1 $$
移项得到
$$ ed - k\phi(n) = 1 $$
所以, 实际上这个问题就变成了:已知两个数 a 和 b, 求解 x 和 y 满足如下方程:
$$ ax + by = 1 $$
根据 [扩展欧几里得算法][4], 这个方程式有解的充分必要条件是 a 和 b 互质.
在我们的情况中, e 和 $\phi(n)$ 是互质的, 所以这个方程式有解. 同时, 通过扩展欧几里得算法, 可以非常容易的通过迭代求解出 d = -19.
d 加减 $\phi(n)$ 的倍数都是有效的值, 所以我们加上 48, 得到 d = 29.
到这里计算完毕, 公钥就是 $[n, e] = [63, 5]$, 私钥就是 $[n, d] = [63, 29]$.
加密和解密
现在我们来看看加密和解密过程是怎样的.
被加密的消息 m 需要是一个小于 n 的整数(我们可以将任意字节流直接解读为一个无符号整数). 如果消息太大, 解读为整数以后比 n 要大, 那么分段加密即可. 实际上在工程中, 我们不会直接用 RSA 来加密消息, 而是用 RSA 来加密一个对称秘钥, 再用这个秘钥加密消息.
加密的过程, 就是计算如下的 c.
$$ m^e \equiv c \pmod n $$
我们的公钥是 $[63, 5]$, 假设我们的消息是 10.
$$ 10^5 \equiv 19 \pmod {63} $$
c = 19, 所以加密以后的消息就是 19.
后面我们会证明, 下面的等式一定成立:
$$ c^d \equiv m \pmod n $$
所以, 解密只要使用私钥 $[n, d]$, 对 c 进行运算即可.
我们的私钥是 $[63, 29]$.
$$ 19^{29} \equiv 10 \pmod {63} $$
解密得出原始消息 10.
解密证明
现在我们来证明为什么如下等式一定成立.
$$ c^d \equiv m \pmod n $$
因为
$$ m^e \equiv c \pmod n $$
所以, c 可以写为
$$c = m^e - kn$$
将 c 代入得到
$$ (m^e - kn)^d \equiv m \pmod n $$
根据 [二项式定理][5], 左边展开后的每一项, 除了 $m^{ed}$ 以外, 都含有 $kn$, 因此, 证明上面的式子等同于证明
$$ m^{ed} \equiv m \pmod n $$
由于
$$ ed \equiv 1 \pmod {\phi(n)} $$
所以, $ed = 1 + h\phi(n)$, 代入得到
$$ m^{h\phi(n) + 1} \equiv m \pmod n $$
我们来分两种情况证明.
1、如果 m 和 n 互质
根据欧拉定理, 我们可以得到
$$ m^{\phi(n)} \equiv 1 \pmod n $$
所以
$$ m^{\phi(n)} = kn + 1 $$
$$ (m^{\phi(n)})^h = (kn + 1)^h $$
根据二项式定理, 我们可以得知
$$ (m^{\phi(n)})^h = k'n + 1 $$
也就是
$$ (m^{\phi(n)})^h \equiv 1 \pmod n $$
从而得到
$$ (m^{\phi(n)})^h \times m \equiv m \pmod n $$
原式得到证明.
2、如果 m 和 n 不互质
因为 n 是质数 p 和 q 的乘积, 此时 m 必然为 kp 或者 kq.
以 m = kp 为例, 此时 k 必然与 q 互质. 因为 n = pq, 而 m < n, 所以 k 必然小于 q, 而 q 是一个质数, 在小于 q 的数字当中所有数都与 q 互质.
同时 kp 必然也与 q 互质, 如果 kp 和 q 不互质, 那么 kp 必然是 q 的倍数, 因为 q 不存在其他因子, 那么 kp 就是 n 的倍数, 因为 n = pq, 但是我们的前提是 m < n.
因为 kp 和 q 互质, 根据欧拉定理
$$ (kp)^{q - 1} \equiv 1 \pmod q $$
所以
$$ (kp)^{q - 1} = tq + 1 $$
两边同时进行 $h(p-1)$ 次方
$$ [(kp)^{q - 1}]^{h(p-1)} = (tq + 1)^{h(p-1)} $$
同理根据二项式定理, 右边展开除了 1 每一项都含有 q, 所以可以得到
$$ [(kp)^{q - 1}]^{h(p-1)} \equiv 1 \pmod q $$
从而得到
$$ [(kp)^{q - 1}]^{h(p-1)} \times kp \equiv kp \pmod q $$
也就是
$$ (kp)^{ed} \equiv kp \pmod q $$
改写为如下形式
$$ (kp)^{ed} = kp + tq $$
左边是 p 的倍数, 右边 kp 是 p 的倍数, 所以 tq 必然是 p 的倍数. 而 q 是 p 互质的, 因此 t 必然是 p 的倍数, 我们记为 t = t’p, 代入得到
$$ (kp)^{ed} = kp + t'pq $$
也就是
$$ m^{ed} \equiv m \pmod n $$
RSA 的解密至此得到了证明.
可靠性
接下来我们来看为什么 RSA 是可靠的, 也就是说, 在得知公钥 $[n, e]$ 的情况下, 怎样保证私钥 $[n, d]$ 的安全.
因为 n 是公开的, 所以私钥的安全本质上就是 d 的安全, 那么有没有可能在得知 n 和 e 的情况下, 推导得出 d?
- 因为
$ed \equiv 1 \pmod {\phi(n)}$, 想知道 d 需要知道 e 和$\phi(n)$ - 因为 e 是公开的, 所以想知道 d 需要知道
$\phi(n)$ - 而
$\phi(n) = (p - 1)(q - 1)$计算$\phi(n)$需要对正数 n 进行质数分解
所以, d 的安全性依赖于对 n 进行质数分解的难度. 目前来说, 大整数的质数分解是一件相当困难的事情, 参考 [整数分解][6].
秘钥格式
日常工作中我们似乎并没有使用 RSA, 但其实, 我们无时无刻都在用它.
在配置 GitHub 或者 远程服务器时, 一般我们都会使用 ssh-keygen 生成秘钥, 然后上传 id_rsa.pub 到远程服务器, 这样, 之后的访问便不再需要输入密码, 十分方便, 同时也十分安全.
这里的 ssh-keygen 生成的就是 RSA 的两把钥匙. 访问远程服务器和拉取 Git 仓库这些常见操作底层都是在使用 RSA 进行鉴权, 只是一般我们并不去注意而已.
ssh-keygen 生成的公钥和私钥默认保存目录为 ~/.ssh, 公钥为 ~/.ssh/id_rsa.pub, 私钥为 ~/.ssh/id_rsa.
我们现在来生成一对秘钥看看他们的格式是怎样的, 上面的几个关键数字 n, e, d 又是怎样保存的.
我们得到了 rsa 和 rsa.pub 文件, 其中 rsa 是私钥, rsa.pub 是公钥.
先来看公钥, rsa.pub 的内容如下.
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDMIcdbPh0r8kftRomVX4+6HkCoZYYoWPvI7AQvcEvanZl+j2AqWEFoC8zHMXqXLlMPeE5Nt0tzLFixw9sKOhA3llc2CL4B3cJaYQ1GHI6bpSX1U1PkBtm1YaIMR+d/r22o5On/U0B4Zkmo5Ua+XI3yeYqkyCLgRWz1832IIl9dVvNSln9R89Ox1XOvuMxNnEeACcSBmnAGvY5Jykhf4TBDwwNRmqZpusqkpkfhA6Y9PvjbRNMfcDEz82VV1VeLxIg3ayC6MX5I4vXFORIzx+VbBnxwing8vQZAHj0lFNmWeOZzoh3o9k4uFCSzWezVQD9JV9xQorjsZ5AB1Zdqb1J5 [email protected]这个格式是 OpenSSH 公钥格式, [RFC4253][7] 中有详细的说明. 简单来说, 公钥分为三个部分
- 秘钥类型:
ssh-rsa - PEM 编码的一段数据:
AAAA..b1J5 - 备注:
[email protected]
PEM 的全称是 [Privacy Enhanced Mail][8], 是一种 Base64 编码, 使用 ASCII 来编码二进制数据.
PEM 编码的数据是三个 (length, data) 数据块, length 为四个字节, BigEndian.
- 第一个 data 表示秘钥类型, 和公钥第一部分相同
- 第二个 data 为 RSA exponent, 也就是 e
- 第三个 data 为 RSA modulus, 也就是 n
根据上面的知识, 我们可以很容易地解析 rsa.pub 文件, 下文中提到的 rsademo 程序实现了公钥解析的逻辑.
$ rsademo -parse rsa.pub
OpenSSH Public Key
algorithm: ssh-rsa
e: 0x010001
n: 0xCC21C75B3E1D2BF247ED4689955F8FBA1E40A865862858FBC8EC042F704BDA9D997E8F602A5841680BCCC7317A972E530F784E4DB74B732C58B1C3DB0A3A103796573608BE01DDC25A610D461C8E9BA525F55353E406D9B561A20C47E77FAF6DA8E4E9FF5340786649A8E546BE5C8DF2798AA4C822E0456CF5F37D88225F5D56F352967F51F3D3B1D573AFB8CC4D9C478009C4819A7006BD8E49CA485FE13043C303519AA669BACAA4A647E103A63D3EF8DB44D31F703133F36555D5578BC488376B20BA317E48E2F5C5391233C7E55B067C708A783CBD06401E3D2514D99678E673A21DE8F64E2E1424B359ECD5403F4957DC50A2B8EC679001D5976A6F5279我们也可以使用 openssl 来解析. 因为公钥是 OpenSSH 的格式, 需要先转换到标准的 PEM 格式.
$ ssh-keygen -e -m PEM -f rsa.pub | openssl asn1parse -inform PEM
0:d=0 hl=4 l= 266 cons: SEQUENCE
4:d=1 hl=4 l= 257 prim: INTEGER :CC21C75B3E1D2BF247ED4689955F8FBA1E40A865862858FBC8EC042F704BDA9D997E8F602A5841680BCCC7317A972E530F784E4DB74B732C58B1C3DB0A3A103796573608BE01DDC25A610D461C8E9BA525F55353E406D9B561A20C47E77FAF6DA8E4E9FF5340786649A8E546BE5C8DF2798AA4C822E0456CF5F37D88225F5D56F352967F51F3D3B1D573AFB8CC4D9C478009C4819A7006BD8E49CA485FE13043C303519AA669BACAA4A647E103A63D3EF8DB44D31F703133F36555D5578BC488376B20BA317E48E2F5C5391233C7E55B067C708A783CBD06401E3D2514D99678E673A21DE8F64E2E1424B359ECD5403F4957DC50A2B8EC679001D5976A6F5279
265:d=1 hl=2 l= 3 prim: INTEGER :010001可以很容易地看出第一个数字是 n, 第二个数字是 e, 都是十六进制的表达方式.
私钥的内容如下.
-----BEGIN OPENSSH PRIVATE KEY-----
b3BlbnNzaC1rZXktdjEAAAAABG5vbmUAAAAEbm9uZQAAAAAAAAABAAABFwAAAAdzc2gtcn
NhAAAAAwEAAQAAAQEAzCHHWz4dK/JH7UaJlV+Puh5AqGWGKFj7yOwEL3BL2p2Zfo9gKlhB
aAvMxzF6ly5TD3hOTbdLcyxYscPbCjoQN5ZXNgi+Ad3CWmENRhyOm6Ul9VNT5AbZtWGiDE
fnf69tqOTp/1NAeGZJqOVGvlyN8nmKpMgi4EVs9fN9iCJfXVbzUpZ/UfPTsdVzr7jMTZxH
gAnEgZpwBr2OScpIX+EwQ8MDUZqmabrKpKZH4QOmPT7420TTH3AxM/NlVdVXi8SIN2sguj
F+SOL1xTkSM8flWwZ8cIp4PL0GQB49JRTZlnjmc6Id6PZOLhQks1ns1UA/SVfcUKK47GeQ
AdWXam9SeQAAA9B/9/tPf/f7TwAAAAdzc2gtcnNhAAABAQDMIcdbPh0r8kftRomVX4+6Hk
CoZYYoWPvI7AQvcEvanZl+j2AqWEFoC8zHMXqXLlMPeE5Nt0tzLFixw9sKOhA3llc2CL4B
3cJaYQ1GHI6bpSX1U1PkBtm1YaIMR+d/r22o5On/U0B4Zkmo5Ua+XI3yeYqkyCLgRWz183
2IIl9dVvNSln9R89Ox1XOvuMxNnEeACcSBmnAGvY5Jykhf4TBDwwNRmqZpusqkpkfhA6Y9
PvjbRNMfcDEz82VV1VeLxIg3ayC6MX5I4vXFORIzx+VbBnxwing8vQZAHj0lFNmWeOZzoh
3o9k4uFCSzWezVQD9JV9xQorjsZ5AB1Zdqb1J5AAAAAwEAAQAAAQEAiC1gmPXu8ApJAXk0
/3kooLjd2Xkg7nmuPnN0t1DqyYSpiUyMkrMdrxNwINJZPdGhh4hydFX693J2GODXlxL1Dq
A0vc9HMmeF6FUmTcdvO1YI5IgaRtxrEB15xUeSoBOfzDQqBjK7p5ZVPV72urdz2nZKj3MU
ERk/fzRYYiDMDa9o4frPay3vc2NLSjqbrpFXTHGBYGpVoIY1R7awczBILIz+TqVZ0Awlpp
89aU3K9K4Sbgnb6p0dcGD8FLoRI5geviLOwYbAnuELxzMrJSVC4xH6UMiLGGqm07qpB3cx
Dd2M6jW1179bNko5qHnbsi87SYO5ms+3mRnin6I08kBogQAAAIEAlAGXHrG3+L73gXfK74
8qoC//E97EdtjPZImAr4Ess62TTfOi3SBungRvmXtWY9s/gkimZa6BL2elyEWlwlLlllX2
jZLbLDjRbGdEmjEwIlzF6Dlkv5EiuGzzJ06MirVuOVpWSgtI3GL+Ir8ovibHq+zz7MGPMQ
dsqqASDZXvPn8AAACBAP/frz0gP1YC6w1ZPIcNCFgcWqfKofSwQviZGthpk04ZwwCkNu2X
sG61MqhnsrUt2vJhMtB0khboXa1SxHO6og5duCH2Tn8uWlZsTiFAjhqOxuZwaCd2f+1tgc
4SUpIdavJrkeLLUM+7JprdUeqGGrv9ae5vtfhEBozbwDGm3CJFAAAAgQDMO487OesMXGh2
p2WES/pw+LxJuFqtZZY8Oy2uBNJKXNeFWXioiL4EglMLBgPz5zFkg73qMF2cTP/XFSiO8z
q6LUJOy6FnKDPF8eo5jkaIjyLK3ue9BjF79AB2vkB5APSwNBS6Q5sryKqlaT1u3mx+45FZ
HLB/Zl4iDn404UoMpQAAABhjakBDSnMtTWFjQm9vay1Qcm8ubG9jYWwB
-----END OPENSSH PRIVATE KEY-----我并没有找到标准的格式说明文档, 不过这篇博客 [The OpenSSH Private Key Format][9] 写的很清楚, 我验证了一下, 是对的.
简单来说, 除去开头和结尾的 Marker, 中间部分是 Base64 编码的一段数据, 数据格式如下:
"openssh-key-v1"0x00 # NULL-terminated "Auth Magic" string
32-bit length, "none" # ciphername length and string
32-bit length, "none" # kdfname length and string
32-bit length, nil # kdf (0 length, no kdf)
32-bit 0x01 # number of keys, hard-coded to 1 (no length)
32-bit length, sshpub # public key in ssh format
32-bit length, keytype
32-bit length, pub0
32-bit length, pub1
32-bit length for rnd+prv+comment+pad
64-bit dummy checksum? # a random 32-bit int, repeated
32-bit length, keytype # the private key (including public)
32-bit length, pub0 # Public Key parts
32-bit length, pub1
32-bit length, prv0 # Private Key parts
... # (number varies by type)
32-bit length, comment # comment string
padding bytes 0x010203 # pad to blocksize (see notes below)根据上面的描述, 我们会发现, 其实私钥文件中完整编码了公钥的信息, 所以通过私钥我们可以很容易地”恢复”出公钥文件.
$ ssh-keygen -y -f rsa
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDMIcdbPh0r8kftRomVX4+6HkCoZYYoWPvI7AQvcEvanZl+j2AqWEFoC8zHMXqXLlMPeE5Nt0tzLFixw9sKOhA3llc2CL4B3cJaYQ1GHI6bpSX1U1PkBtm1YaIMR+d/r22o5On/U0B4Zkmo5Ua+XI3yeYqkyCLgRWz1832IIl9dVvNSln9R89Ox1XOvuMxNnEeACcSBmnAGvY5Jykhf4TBDwwNRmqZpusqkpkfhA6Y9PvjbRNMfcDEz82VV1VeLxIg3ayC6MX5I4vXFORIzx+VbBnxwing8vQZAHj0lFNmWeOZzoh3o9k4uFCSzWezVQD9JV9xQorjsZ5AB1Zdqb1J5有了结构说明, 就不难自己实现解析器了. 同样, 下文的 rsademo 程序实现了私钥的解析逻辑.
$ rsademo -parse rsa
OpenSSH Private Key
keyType: ssh-rsa
n: 0xCC21C75B3E1D2BF247ED4689955F8FBA1E40A865862858FBC8EC042F704BDA9D997E8F602A5841680BCCC7317A972E530F784E4DB74B732C58B1C3DB0A3A103796573608BE01DDC25A610D461C8E9BA525F55353E406D9B561A20C47E77FAF6DA8E4E9FF5340786649A8E546BE5C8DF2798AA4C822E0456CF5F37D88225F5D56F352967F51F3D3B1D573AFB8CC4D9C478009C4819A7006BD8E49CA485FE13043C303519AA669BACAA4A647E103A63D3EF8DB44D31F703133F36555D5578BC488376B20BA317E48E2F5C5391233C7E55B067C708A783CBD06401E3D2514D99678E673A21DE8F64E2E1424B359ECD5403F4957DC50A2B8EC679001D5976A6F5279
e: 0x010001
d: 0x882D6098F5EEF00A49017934FF7928A0B8DDD97920EE79AE3E7374B750EAC984A9894C8C92B31DAF137020D2593DD1A18788727455FAF7727618E0D79712F50EA034BDCF47326785E855264DC76F3B5608E4881A46DC6B101D79C54792A0139FCC342A0632BBA796553D5EF6BAB773DA764A8F731411193F7F34586220CC0DAF68E1FACF6B2DEF73634B4A3A9BAE91574C7181606A55A0863547B6B07330482C8CFE4EA559D00C25A69F3D694DCAF4AE126E09DBEA9D1D7060FC14BA1123981EBE22CEC186C09EE10BC7332B252542E311FA50C88B186AA6D3BAA90777310DDD8CEA35B5D7BF5B364A39A879DBB22F3B4983B99ACFB79919E29FA234F2406881
p: 0xFFDFAF3D203F5602EB0D593C870D08581C5AA7CAA1F4B042F8991AD869934E19C300A436ED97B06EB532A867B2B52DDAF26132D0749216E85DAD52C473BAA20E5DB821F64E7F2E5A566C4E21408E1A8EC6E6706827767FED6D81CE1252921D6AF26B91E2CB50CFBB269ADD51EA861ABBFD69EE6FB5F844068CDBC031A6DC2245
q: 0xCC3B8F3B39EB0C5C6876A765844BFA70F8BC49B85AAD65963C3B2DAE04D24A5CD7855978A888BE0482530B0603F3E7316483BDEA305D9C4CFFD715288EF33ABA2D424ECBA1672833C5F1EA398E46888F22CADEE7BD06317BF40076BE407900F4B03414BA439B2BC8AAA5693D6EDE6C7EE391591CB07F665E220E7E34E14A0CA5如果使用 openssl 的话, 可以通过如下指令解析私钥. ssh-keygen 无法直接更改私钥的格式, 需要曲线救国, 使用它”修改密码”的功能, 参考 [这个提问][10]
$ cp rsa rsa.pem
$ ssh-keygen -p -m PEM -f rsa.pem
$ cat rsa.pem
-----BEGIN RSA PRIVATE KEY-----
MIIEpQIBAAKCAQEAzCHHWz4dK/JH7UaJlV+Puh5AqGWGKFj7yOwEL3BL2p2Zfo9g
KlhBaAvMxzF6ly5TD3hOTbdLcyxYscPbCjoQN5ZXNgi+Ad3CWmENRhyOm6Ul9VNT
5AbZtWGiDEfnf69tqOTp/1NAeGZJqOVGvlyN8nmKpMgi4EVs9fN9iCJfXVbzUpZ/
UfPTsdVzr7jMTZxHgAnEgZpwBr2OScpIX+EwQ8MDUZqmabrKpKZH4QOmPT7420TT
H3AxM/NlVdVXi8SIN2sgujF+SOL1xTkSM8flWwZ8cIp4PL0GQB49JRTZlnjmc6Id
6PZOLhQks1ns1UA/SVfcUKK47GeQAdWXam9SeQIDAQABAoIBAQCILWCY9e7wCkkB
eTT/eSiguN3ZeSDuea4+c3S3UOrJhKmJTIySsx2vE3Ag0lk90aGHiHJ0Vfr3cnYY
4NeXEvUOoDS9z0cyZ4XoVSZNx287VgjkiBpG3GsQHXnFR5KgE5/MNCoGMrunllU9
Xva6t3PadkqPcxQRGT9/NFhiIMwNr2jh+s9rLe9zY0tKOpuukVdMcYFgalWghjVH
trBzMEgsjP5OpVnQDCWmnz1pTcr0rhJuCdvqnR1wYPwUuhEjmB6+Is7BhsCe4QvH
MyslJULjEfpQyIsYaqbTuqkHdzEN3YzqNbXXv1s2SjmoeduyLztJg7maz7eZGeKf
ojTyQGiBAoGBAP/frz0gP1YC6w1ZPIcNCFgcWqfKofSwQviZGthpk04ZwwCkNu2X
sG61MqhnsrUt2vJhMtB0khboXa1SxHO6og5duCH2Tn8uWlZsTiFAjhqOxuZwaCd2
f+1tgc4SUpIdavJrkeLLUM+7JprdUeqGGrv9ae5vtfhEBozbwDGm3CJFAoGBAMw7
jzs56wxcaHanZYRL+nD4vEm4Wq1lljw7La4E0kpc14VZeKiIvgSCUwsGA/PnMWSD
veowXZxM/9cVKI7zOrotQk7LoWcoM8Xx6jmORoiPIsre570GMXv0AHa+QHkA9LA0
FLpDmyvIqqVpPW7ebH7jkVkcsH9mXiIOfjThSgylAoGBANSTUnQXCWd8zyjs3TNZ
6XfCPrKtzvWJRmpgUIRA2eeF0ZMD2rpzTln7YdW1KSwKp568j8nNPt2XONRZMerv
v9jtlZ9pkPdqXBT2r8ZCaoy315j1BCLc+RUY6EF6yWyo0gQKyE3CGiYq1rzMaFTO
CwHpXAuCdYyHf2Wg38CgXrx9AoGAHvN3xXYFlR38Bt9flykcjzpi7pktxNF8byxY
w+KfK/3d+6uPiZsPkQdfJnCG8NO8vIrqoS8rQKC6tRHTz7Y01Do/rklV8Jg7IGiF
IqvZLKDkmPInFJJ3tV1JJLW4d54ZdwqtiXztazlCA0drs/2pW6GJSYP7i5Mr+OVR
YxoxarECgYEAlAGXHrG3+L73gXfK748qoC//E97EdtjPZImAr4Ess62TTfOi3SBu
ngRvmXtWY9s/gkimZa6BL2elyEWlwlLlllX2jZLbLDjRbGdEmjEwIlzF6Dlkv5Ei
uGzzJ06MirVuOVpWSgtI3GL+Ir8ovibHq+zz7MGPMQdsqqASDZXvPn8=
-----END RSA PRIVATE KEY-----得到 PEM 格式的私钥以后, 剩下就好办了.
$ openssl asn1parse -inform PEM < rsa.pem
0:d=0 hl=4 l=1189 cons: SEQUENCE
4:d=1 hl=2 l= 1 prim: INTEGER :00
7:d=1 hl=4 l= 257 prim: INTEGER :CC21C75B3E1D2BF247ED4689955F8FBA1E40A865862858FBC8EC042F704BDA9D997E8F602A5841680BCCC7317A972E530F784E4DB74B732C58B1C3DB0A3A103796573608BE01DDC25A610D461C8E9BA525F55353E406D9B561A20C47E77FAF6DA8E4E9FF5340786649A8E546BE5C8DF2798AA4C822E0456CF5F37D88225F5D56F352967F51F3D3B1D573AFB8CC4D9C478009C4819A7006BD8E49CA485FE13043C303519AA669BACAA4A647E103A63D3EF8DB44D31F703133F36555D5578BC488376B20BA317E48E2F5C5391233C7E55B067C708A783CBD06401E3D2514D99678E673A21DE8F64E2E1424B359ECD5403F4957DC50A2B8EC679001D5976A6F5279
268:d=1 hl=2 l= 3 prim: INTEGER :010001
273:d=1 hl=4 l= 257 prim: INTEGER :882D6098F5EEF00A49017934FF7928A0B8DDD97920EE79AE3E7374B750EAC984A9894C8C92B31DAF137020D2593DD1A18788727455FAF7727618E0D79712F50EA034BDCF47326785E855264DC76F3B5608E4881A46DC6B101D79C54792A0139FCC342A0632BBA796553D5EF6BAB773DA764A8F731411193F7F34586220CC0DAF68E1FACF6B2DEF73634B4A3A9BAE91574C7181606A55A0863547B6B07330482C8CFE4EA559D00C25A69F3D694DCAF4AE126E09DBEA9D1D7060FC14BA1123981EBE22CEC186C09EE10BC7332B252542E311FA50C88B186AA6D3BAA90777310DDD8CEA35B5D7BF5B364A39A879DBB22F3B4983B99ACFB79919E29FA234F2406881
534:d=1 hl=3 l= 129 prim: INTEGER :FFDFAF3D203F5602EB0D593C870D08581C5AA7CAA1F4B042F8991AD869934E19C300A436ED97B06EB532A867B2B52DDAF26132D0749216E85DAD52C473BAA20E5DB821F64E7F2E5A566C4E21408E1A8EC6E6706827767FED6D81CE1252921D6AF26B91E2CB50CFBB269ADD51EA861ABBFD69EE6FB5F844068CDBC031A6DC2245
666:d=1 hl=3 l= 129 prim: INTEGER :CC3B8F3B39EB0C5C6876A765844BFA70F8BC49B85AAD65963C3B2DAE04D24A5CD7855978A888BE0482530B0603F3E7316483BDEA305D9C4CFFD715288EF33ABA2D424ECBA1672833C5F1EA398E46888F22CADEE7BD06317BF40076BE407900F4B03414BA439B2BC8AAA5693D6EDE6C7EE391591CB07F665E220E7E34E14A0CA5
798:d=1 hl=3 l= 129 prim: INTEGER :D49352741709677CCF28ECDD3359E977C23EB2ADCEF589466A60508440D9E785D19303DABA734E59FB61D5B5292C0AA79EBC8FC9CD3EDD9738D45931EAEFBFD8ED959F6990F76A5C14F6AFC6426A8CB7D798F50422DCF91518E8417AC96CA8D2040AC84DC21A262AD6BCCC6854CE0B01E95C0B82758C877F65A0DFC0A05EBC7D
930:d=1 hl=3 l= 128 prim: INTEGER :1EF377C57605951DFC06DF5F97291C8F3A62EE992DC4D17C6F2C58C3E29F2BFDDDFBAB8F899B0F91075F267086F0D3BCBC8AEAA12F2B40A0BAB511D3CFB634D43A3FAE4955F0983B20688522ABD92CA0E498F227149277B55D4924B5B8779E19770AAD897CED6B394203476BB3FDA95BA1894983FB8B932BF8E551631A316AB1
1061:d=1 hl=3 l= 129 prim: INTEGER :9401971EB1B7F8BEF78177CAEF8F2AA02FFF13DEC476D8CF648980AF812CB3AD934DF3A2DD206E9E046F997B5663DB3F8248A665AE812F67A5C845A5C252E59655F68D92DB2C38D16C67449A3130225CC5E83964BF9122B86CF3274E8C8AB56E395A564A0B48DC62FE22BF28BE26C7ABECF3ECC18F31076CAAA0120D95EF3E7F我们得到了一堆数字, 对照如下的说明, 就可以知道每个数字的含义.
RSAPrivateKey ::= SEQUENCE {
version Version,
modulus INTEGER, -- n
publicExponent INTEGER, -- e
privateExponent INTEGER, -- d
prime1 INTEGER, -- p
prime2 INTEGER, -- q
exponent1 INTEGER, -- d mod (p-1)
exponent2 INTEGER, -- d mod (q-1)
coefficient INTEGER, -- (inverse of q) mod p
otherPrimeInfos OtherPrimeInfos OPTIONAL
}Use RSA
清楚了公私钥格式以后, 我们来看看怎样直接使用 RSA 来加密数据.
因为加密的消息 m 必须要小于 n, 所以, 在日常应用中, RSA 不会用来直接加密消息, 而是用来加密一个对称秘钥, 再用这个对称秘钥加密消息.
当然, 直接加密一个消息自然是不会有任何问题的, 这里我们来演示一下.
# 生成我们的私密消息
$ echo "This is our secret message." > secret.txt
# 使用 RSA 加密, 注意要转换公钥格式到 PKCS8
$ openssl rsautl -encrypt -oaep -pubin -inkey <(ssh-keygen -e -m PKCS8 -f rsa.pub) -in secret.txt -out secret.txt.enc
# 加密以后的文件是 secret.txt.enc
# 接下来使用 RSA 解密, 同样要转换私钥格式
# 我们使用上文中得到的 PEM 格式私钥, rsa.pem
$ openssl rsautl -decrypt -oaep -inkey rsa.pem -in secret.txt.enc -out result.txt
# 验证一下是否得到了原始消息
$ cat result.txt
This is our secret message.上面我们提到的 RSA 加密过程, 也就是 $m^e \equiv c \pmod n$, 也被称为教科书式 RSA. 工程应用中, 不会直接这样处理, 而是会存在一个 Padding 的过程, 具体不再展开, 感兴趣可以去看 [RSA - theory and implementation][11].
注意, 密码学中有很多微妙的问题要考虑. 我们这里所做的一切都是为了学习和理解他们的工作原理, 而不是为了自己去实现他们. 千万不要自己去实现任何加密解密算法, 专业的事情交给专业的人员处理就好.
A Simple Demo
基于上面的理解, 我们来实现自己的 RSA 程序就不难了.
[rsademo][12] 是我使用 Go 开发的一个 RSA 实现. 可以解析 OpenSSH 的秘钥文件以及演示 RSA 加解密, 具体功能可以查看 GitHub 的 README.
使用 rsademo 加解密需要提供两个质数, 可以使用 [这个网站][13] 来生成.
现在我们使用 101 和 103 两个质数来生成加密所需的 n, e, d, 然后加密数字 1024.
$ rsademo -enc 101 103 1024
Key details:
p: 101
q: 103
n: 10403
\phi(n): 10200
e: 7
d: 8743
Encrypt message: 1024
Encrypt result: 9803可以发现, 加密以后的数字为 9803, 大家可以自行验证一下, $1024^7 \pmod {10403}$ 是不是等于 9803.
然后我们来进行解密:
$ rsademo -dec 101 103 9803
Key details:
p: 101
q: 103
n: 10403
\phi(n): 10200
e: 7
d: 8743
Decrypt cipher: 9803
Decrypt result: 1024最后得到了 1024
password-less login
OpenID
- 互联网上每一个网址(URL), 都指向一个独一无二的网页, 这说明网址具有唯一性. 因此, 可以用网址来标识用户
- 所以, 使用OpenID的网站, 不要求用户输入”用户名”, 而要求用户输入一个代表其身份的网址. 然后, 向该网址进行求证, 如果得到证实, 就允许用户登录, 从而实现”无密码登录”
- OpenID有两个很大的缺点
- 需要服务器端支持
- 是使用网址表示身份, 违背直觉, 普通用户难以理解
- OpenID的实质, 是让第三方网站认证用户身份
第三方账户
- 优点
- 比较直观, 用户容易接受
- 缺点
- 自身的业务, 从此多多少少要依赖第三方网站
oAuth
- OAuth协议其实与”第三方帐户”是一样的
- “第三方账户”是第三方网站提供用户身份认证, 属于”认证”服务(authentication); OAuth则是更进一步, 第三方网站允许你直接操作它的用户数据, 属于”授权”服务(authorization)
Email一次性登录
- 用户登录的时候, 只显示一个Email地址输入框, 用户输入Email地址以后, 网站就向该地址发出一封邮件, 里面包含了一个登录链接. 用户点击这个链接, 就证明他/她确实是这个邮箱的主人, 身份有效, 从而实现登录
- 登录链接只在一段时间内有效, 但是可以通过cookie, 让用户长时间处在登录状态. 如果cookie失效, 则重新向用户邮箱发出另一个登录链接即可
Base64
Base64是一种编码转换方式, 就是说选出64个字符 - 小写字母a-z, 大写字母A-Z, 数字0-9, 符号”+“, “/”(再加上作为垫字的”=“, 实际上是65个字符) - 作为一个基本字符集. 然后其他所有符号都转换成这个字符集中的字符.
转换方式可以分为四步:
- 将每三个字节作为一组, 一共是24个二进制位
- 将这24个二进制位分为四组, 每个组有6个二进制位
- 在每组前面加两个00, 扩展成32个二进制位, 即四个字节
- 根据下表, 得到扩展后的每个字节的对应符号, 这就是Base64的编码值
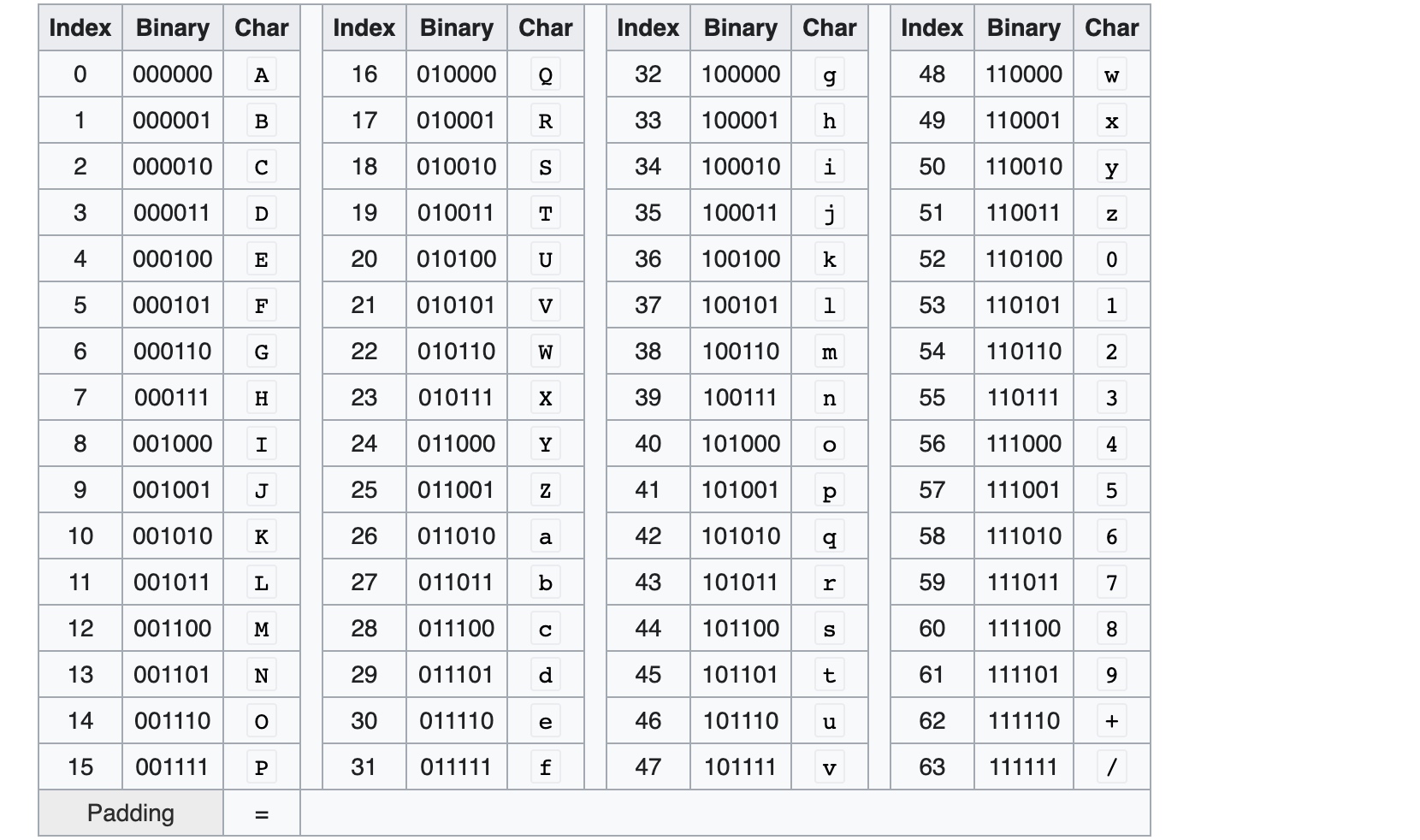 因为 Base64 将三个字节转化成四个字节, 因此Base64编码后的文本, 会比原文本大出三分之一左右.
因为 Base64 将三个字节转化成四个字节, 因此Base64编码后的文本, 会比原文本大出三分之一左右.
- 例子1 - Man 转成Base64编码:
- “M”、”a”、”n”的ASCII值分别是77、97、110, 对应的二进制值是01001101、01100001、01101110, 将它们连成一个24位的二进制字符串010011010110000101101110
- 将这个24位的二进制字符串分成4组, 每组6个二进制位:010011、010110、000101、101110
- 在每组前面加两个00, 扩展成32个二进制位, 即四个字节:00010011、00010110、00000101、00101110. 它们的十进制值分别是19、22、5、46
- 根据上表, 得到每个值对应Base64编码, 即T、W、F、u
- 因此, Man的Base64编码就是TWFu
- 例子2 - 汉字”严”转化成Base64编码:
- 注意, 汉字本身可以有多种编码, 比如gb2312、utf-8、gbk等等, 每一种编码的Base64对应值都不一样. 下面的例子以utf-8为例
- “严”的utf-8编码为E4B8A5, 写成二进制就是三字节的”11100100 10111000 10100101”
- 将这个24位的二进制字符串, 按照第3节中的规则, 转换成四组一共32位的二进制值”00111001 00001011 00100010 00100101”, 相应的十进制数为57、11、34、37,
- 根据上表, 得到每个值对应Base64编码就为5、L、i、l
- 所以, 汉字”严”(utf-8编码)的Base64值就是5Lil
Mac 上使用OpenSSL 生成RSA证书
OpenSSL是一个安全套接字层密码库,其包括常用的密码算法、常用的密钥生成和证书封装管理功能及SSL协议,并提供了丰富的应用程序以供测试. OpenSSL是一个开源的项目,其由三个部分组成:
- openssl命令行工具
- libencrypt加密算法库
- libssl加密模块应用库
步骤:
- 生成私钥(key文件):
openssl genrsa -out client.key 4096 - 生成签名请求(csr文件):
openssl req -new -key client.key -out client.csr - 签发证书:
openssl x509 -req -days 365 -in client.csr -signkey client.key -out client.crt
一键生成自签名证书:
openssl req -new -x509 -newkey rsa:4096 -keyout test.key -out test.crt
tips:
- 输入的密码必须大于等于4位
- Common Name可以输入:*.yourdomain.com,这种方式生成通配符域名证书
- 证书文件crt中存储的是证书信息与公钥信息,key文件存储的是私钥信息,csr是申请证书所需要的中间文件
Ref:
JWT - ValueError: Could not deserialize key data.
- https://blog.miguelgrinberg.com/post/json-web-tokens-with-public-key-signatures/page/2#comments
- https://stackoverflow.com/questions/56251161/valueerror-could-not-deserialize-key-data-during-jwt-encoding
not working:
from cryptography.hazmat.backends import default_backend
from cryptography.hazmat.primitives.serialization import load_pem_private_key
private_key = f'-----BEGIN RSA PRIVATE KEY-----{p_key}-----END RSA PRIVATE KEY-----'
# pri_key_binary = private_key.encode('ascii')
# private_key = open('./key/jwt-key').read()
priv_rsakey = load_pem_private_key(private_key, password='abc123', backend=default_backend())
encoded = jwt.encode(payload, priv_rsakey, algorithm='RS256')
res = jwt.decode(encoded, private_key, algorithms=['RS256'])
print('==='*10,res)JWT
JWT是目前最流行的跨域认证解决方案.
原理 - 服务器认证以后, 生成一个 JSON 对象, 发回给用户, 对象如下:
{
'name':'charon',
'role':'admin',
'expire':'20200718'
}之后用户与服务端通信的时候, 都要发回这个 JSON 对象. 服务器完全只靠这个对象认定用户身份. 为了防止用户篡改数据, 服务器在生成这个对象的时候, 会加上签名(秘匙+对象 => 签名).
JWT 的数据结构
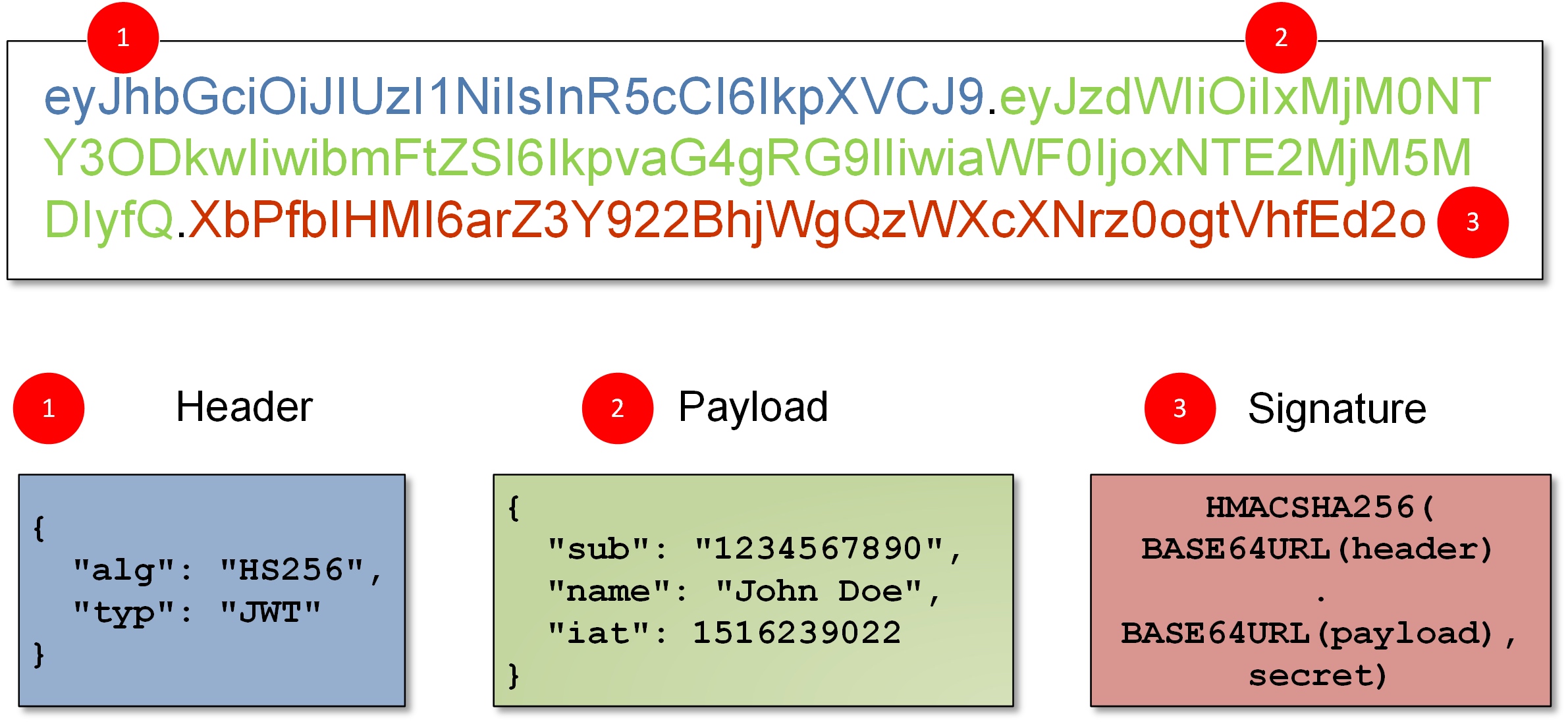
JWT 的三个部分:
- Header (头部)
- Payload (负载)
- Signature (签名)
写成一行就是: Header.Payload.Signature
Header
描述 JWT 的元数据, 通常是:
{
"alg": "HS256",
"typ": "JWT"
}- alg属性表示签名的算法(algorithm), 默认是 HMAC SHA256(写成 HS256)
- typ属性表示这个令牌(token)的类型(type), JWT 令牌统一写为JWT
要使用 Base64URL 算法转成字符串
Payload
来存放实际需要传递的数据. JWT 规定了7个官方字段, 供选用
iss (issuer):签发人
exp (expiration time):过期时间
sub (subject):主题
aud (audience):受众的url地址
nbf (Not Before):生效时间
iat (Issued At):签发时间
jti (JWT ID):编号除了官方字段, 还可以加自定义的私有字段
例子 :
{
"sub": "1234567890",
"name": "John Doe",
"admin": true
}
{
"iss": "http://charon.me",
"aud": "http://charon.me/jwt_auth/",
"jti": "4f1g23a12aa",
"iat": 1534070547,
"nbf": 1534070607,
"exp": 1534074147,
"uid": 1,
"sub": "testtest",
"data": {
"uname": "charon",
"uEmail": "[email protected]",
"uID": "0xA0",
"uGroup": "guest"
}
}注意: JWT 默认是不加密的, 任何人都可以读到, 所以不要把秘密信息放在这个部分
这个 JSON 对象也要使用 Base64URL 算法转成字符串
Signature
对前两部分的签名, 防止数据篡改
首先, 需要指定一个密钥(secret) (当利用非对称加密方法的时候, 这里的secret为私钥). 这个密钥只有服务器才知道, 不能泄露给用户. 然后, 使用 Header 里面指定的签名算法(默认是 HMAC SHA256), 按照下面的公式产生签名.
HMACSHA256(
base64UrlEncode(header) + "." +
base64UrlEncode(payload),
secret
)jwt的签名算法有三种:
- 对称加密HMAC【哈希消息验证码】: HS256/HS384/HS512
- 非对称加密RSASSA【RSA签名算法】:(RS256/RS384/RS512)
- ECDSA【椭圆曲线数据签名算法】:(ES256/ES384/ES512)
算出签名以后, 把 Header、Payload、Signature 三个部分拼成一个字符串, 每个部分之间用”点”(.)分隔, 就可以得到经过签名的JWT, 然后返回给用户.
验证
当验证签名的时候, 利用公钥或者密钥来解密Signature, 和 base64UrlEncode(header) + “.” + base64UrlEncode(payload) 的内容完全一样的时候, 表示验证通过
Base64URL
Header 和 Payload 串型化的算法是 Base64URL. 这个算法跟 Base64 算法基本类似, 但有一些小的不同.
JWT 作为一个令牌(token), 有些场合可能会放到 URL(比如 api.example.com/?token=xxx). Base64 有三个字符 + / = 在 URL 里面有特殊含义, 所以要被替换掉: =被省略, +替换成-, /替换成_
ECDSA, RSASSA, or HMAC ?
无论用的是 HMAC, RSASSA, ECDSA;密钥, 公钥, 私钥都不会发送给客户端, 仅仅会保留在服务端上.
- 对称的算法HMAC适用于单点登录, 一对一的场景中, 速度很快
- 但是面对一对多的情况, 比如一个APP中的不同服务模块, 需要JWT登录的时候, 主服务端(APP)拥有一个私钥来完成签名即可, 而用户带着JWT在访问不同服务模块的时候, 副服务端只要用公钥来验证签名就可以了. 从一定程度上也减少了主服务端的压力
- 不同成员进行开发的时候, 大家可以用统一的私钥来完成签名, 然后用各自的公钥去完成对JWT的认证, 也是一种非常好的开发手段
- 因此, 构建一个没有多个小型“微服务应用程序”的应用程序, 并且开发人员只有一组的, 选择HMAC来签名即可. 其他情况下, 尽量选择RSA
JWT 的使用方式
客户端收到服务器返回的 JWT, 可以储存在 Cookie 里面, 也可以储存在 localStorage.
此后, 客户端每次与服务器通信, 都要带上这个 JWT. 可以把它放在 Cookie 里面自动发送, 但是这样不能跨域, 所以更好的做法是放在 HTTP 请求的头信息Authorization字段里.
Authorization: Bearer <token>另一种做法是, 跨域的时候, JWT 就放在 POST 请求的数据体里面
JWT 特点
- JWT 默认是不加密, 但也是可以加密的. 生成原始 Token 以后, 可以用密钥再加密一次
- JWT 不加密的情况下, 不能将秘密数据写入 JWT
- JWT 不仅可以用于认证, 也可以用于交换信息. 有效使用 JWT, 可以降低服务器查询数据库的次数
- JWT 的最大缺点是, 由于服务器不保存 session 状态, 因此无法在使用过程中废止某个 token, 或者更改 token 的权限(即 一旦 JWT 签发了, 在到期之前就会始终有效, 除非服务器部署额外的逻辑)
- JWT 本身包含了认证信息, 一旦泄露, 任何人都可以获得该令牌的所有权限. 为了减少盗用, JWT 的有效期应该设置得比较短. 对于一些比较重要的权限, 使用时应该再次对用户进行认证
- 为了减少盗用, JWT 不应该使用 HTTP 协议明码传输, 要使用 HTTPS 协议传输
OAuth2.0
OAuth的作用就是让”客户端”安全可控地获取”用户”的授权, 与”服务商提供商”进行互动. (OAuth 就是一种授权机制. 数据的所有者(user)告诉系统(resource server), 同意授权第三方应用(web/app=>client)进入系统, 获取这些数据. 系统从而产生一个短期的进入令牌(token), 用来代替密码, 供第三方应用(web/app=>client)使用)
使用令牌(token)特点:
- 令牌是短期的, 到期会自动失效, 用户自己无法修改; 密码一般长期有效, 用户不修改, 就不会发生变化
- 令牌可以被数据所有者撤销, 会立即失效; 密码一般不允许被他人撤销
- 令牌有权限范围(scope), 对于网络服务来说, 只读令牌就比读写令牌更安全; 密码一般是完整权限
名词解释:
- Third-party application:第三方应用程序, 又称”客户端”(client)
- HTTP service:HTTP服务提供商, 又称”服务提供商”
- Resource Owner:资源所有者, 又称”用户”(user)
- User Agent:用户代理, 指浏览器
- Authorization server:认证服务器, 即服务提供商专门用来处理认证的服务器
- Resource server:资源服务器, 即服务提供商存放用户生成的资源的服务器. 它与认证服务器, 可以是同一台服务器, 也可以是不同的服务器
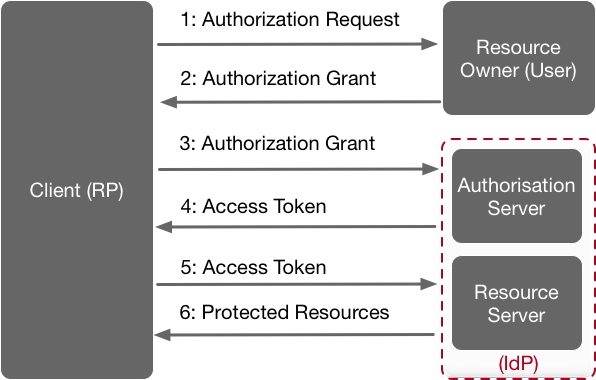
- 用户打开客户端以后, 客户端要求用户给予授权
- 用户同意给予客户端授权 (user input their credential)
- 客户端使用上一步获得的授权(user credential), 向认证服务器申请令牌
- 认证服务器对客户端进行认证以后, 确认无误, 同意发放令牌(access token)
- 客户端使用令牌(access token), 向资源服务器申请获取资源
- 资源服务器确认令牌无误, 同意向客户端开放资源(return data)
B是关键, 即用户怎样才能给于客户端授权. 有了这个授权以后, 客户端就可以获取令牌, 进而凭令牌获取资源
客户端的授权模式
客户端必须得到用户的授权(authorization grant), 才能获得令牌(access token). OAuth 2.0定义了四种授权方式:
- 授权码模式(authorization code)
- 简化模式(implicit)
- 密码模式(resource owner password credentials)
- 客户端模式(client credentials)
authorization code
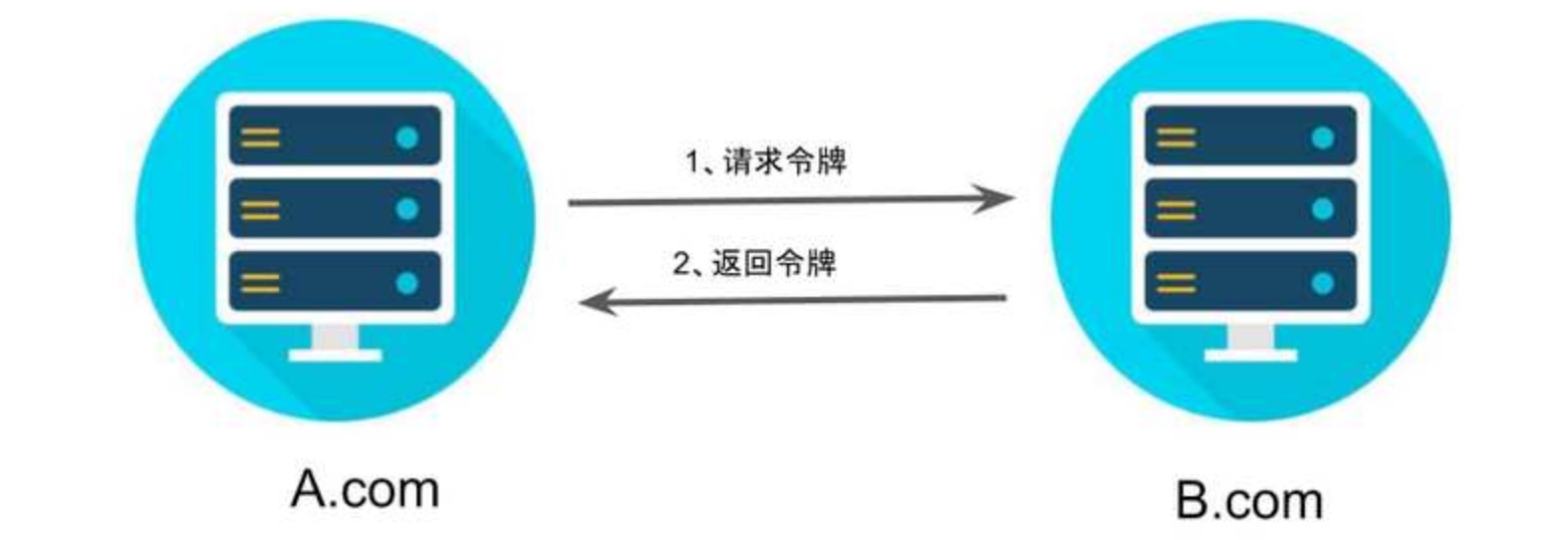
- 授权码模式(authorization code)是指第三方应用先申请一个授权码, 然后再用该码获取令牌
- 最常用的流程, 安全性也最高, 它适用于那些有后端的 Web 应用
- 授权码通过前端传送, 令牌则是储存在后端, 而且所有与资源服务器的通信都在后端完成. 这样的前后端分离, 可以避免令牌泄漏
步骤:
A 网站提供一个链接, 用户点击后就会跳转到 B 网站, 授权用户数据给 A 网站使用. A 网站跳转 B 网站的一个示意链接:
https://b.com/oauth/authorize? response_type=code& client_id=CLIENT_ID& redirect_uri=CALLBACK_URL& scope=read # response_type参数表示要求返回授权码(code) # client_id参数让 B 知道是谁在请求 # redirect_uri参数是 B 接受或拒绝请求后的跳转网址 # scope参数表示要求的授权范围
跳转后, B 网站会要求用户登录, 然后询问是否同意给予 A 网站授权. 用户表示同意, 这时 B 网站就会跳回
redirect_uri参数指定的网址. 跳转时, 会传回一个授权码https://a.com/callback?code=AUTHORIZATION_CODE # code参数就是授权码
A 网站拿到授权码以后, 就可以在后端, 向 B 网站请求令牌
https://b.com/oauth/token? client_id=CLIENT_ID& client_secret=CLIENT_SECRET& grant_type=authorization_code& code=AUTHORIZATION_CODE& redirect_uri=CALLBACK_URL # client_id参数和client_secret参数用来让 B 确认 A 的身份 # grant_type参数的值是AUTHORIZATION_CODE, 表示采用的授权方式是授权码 # code参数是上一步拿到的授权码 # redirect_uri参数是令牌颁发后的回调网址
B 网站收到请求以后, 就会颁发令牌. 具体做法是向
redirect_uri指定的网址, 发送一段 JSON 数据{ "access_token":"ACCESS_TOKEN", "token_type":"bearer", "expires_in":2592000, "refresh_token":"REFRESH_TOKEN", "scope":"read", "uid":100101, "info":{...} }access_token字段就是令牌, A 网站在后端拿到了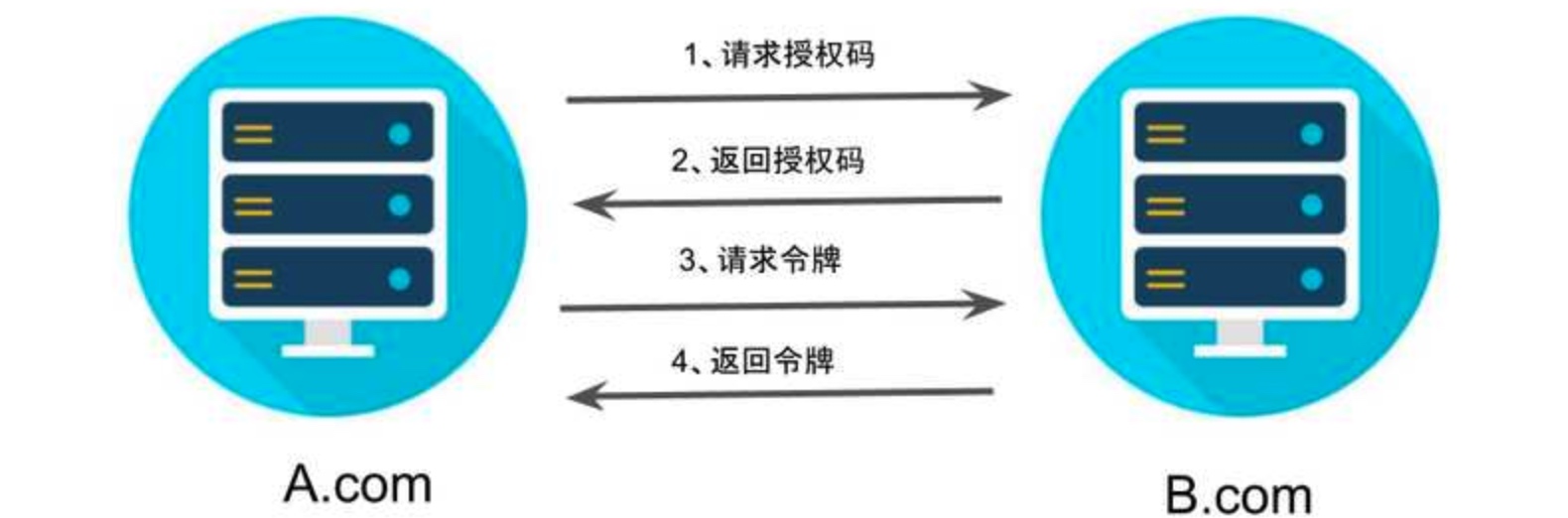
implicit
- 有些 Web 应用是纯前端应用, 没有后端, 所有必须将令牌储存在前端. 这种方式没有授权码这个中间步骤, 所以称为(授权码)”隐藏式”(implicit)
A 网站提供一个链接, 要求用户跳转到 B 网站, 授权用户数据给 A 网站使用:
https://b.com/oauth/authorize? response_type=TOKEN& client_id=CLIENT_ID& redirect_uri=CALLBACK_URL& scope=read # response_type参数表示为TOKEN, 表示要求直接返回令牌
跳转到 B 网站, 登录后同意给予 A 网站授权. 这时, B 网站就会跳回
redirect_uri参数指定的跳转网址, 并且把令牌作为 URL 参数, 传给 A 网站https://a.com/callback#token=ACCESS_TOKEN # token参数就是令牌, A 网站因此直接在前端拿到令牌
注意, 令牌的位置是 URL 锚点(fragment)(井号/number sign/hashtag/hash sign), 而不是查询字符串(querystring), 这是因为 OAuth 2.0 允许跳转网址是 HTTP 协议, 因此存在”中间人攻击”的风险, 而浏览器跳转时, 锚点不会发到服务器, 就减少了泄漏令牌的风险
#是用来指导浏览器动作的, 对服务器端完全无用. (服务器端收不到井号之后的讯息)
 这种方式把令牌直接传给前端, 是很不安全的. 因此, 只能用于一些安全要求不高的场景, 并且令牌的有效期必须非常短, 通常就是会话期间(session)有效, 浏览器关掉, 令牌就失效了.
这种方式把令牌直接传给前端, 是很不安全的. 因此, 只能用于一些安全要求不高的场景, 并且令牌的有效期必须非常短, 通常就是会话期间(session)有效, 浏览器关掉, 令牌就失效了.
resource owner password credentials
用户把用户名和密码, 直接告诉该应用; 该应用就使用你的密码, 申请令牌, 这种方式称为”密码式”(password)
步骤:
A 网站要求用户提供 B 网站的用户名和密码. 拿到以后, A 就直接向 B 请求令牌.
https://oauth.b.com/token? grant_type=password& username=USERNAME& password=PASSWORD& client_id=CLIENT_ID # grant_type参数是授权方式, 这里的password表示"密码式" # username和password是 B 的用户名和密码
B 网站验证身份通过后, 直接给出令牌. 注意, 这时不需要跳转, 而是把令牌放在 JSON 数据里面, 作为 HTTP 回应, A 因此拿到令牌.
这种方式需要用户给出自己的用户名/密码, 显然风险很大, 因此只适用于其他授权方式都无法采用的情况, 而且必须是用户高度信任的应用
client credentials
凭证式(client credentials), 适用于没有前端的命令行应用, 即在命令行下请求令牌
步骤:
第一步, A 应用在命令行向 B 发出请求
https://oauth.b.com/token? grant_type=client_credentials& client_id=CLIENT_ID& client_secret=CLIENT_SECRET # grant_type参数等于client_credentials表示采用凭证式 # client_id和client_secret用来让 B 确认 A 的身份
B 网站验证通过以后, 直接返回令牌
这种方式给出的令牌, 是针对第三方应用的, 而不是针对用户的, 即有可能多个用户共享同一个令牌
令牌的使用
- A 网站拿到令牌以后, 就可以向 B 网站的 API 请求数据.
此时, 每个发到 API 的请求, 都必须带有令牌. 具体做法是在请求的头信息, 加上一个
Authorization字段, 令牌就放在这个字段里面curl -H "Authorization: Bearer ACCESS_TOKEN" \ "https://api.b.com" # ACCESS_TOKEN就是拿到的令牌
更新令牌
- OAuth 2.0 允许用户自动更新令牌
具体方法是:
- B 网站颁发令牌的时候, 一次性颁发两个令牌, 一个用于获取数据, 另一个用于获取新的令牌(
refresh token字段) 令牌到期前, 用户使用
refresh token发一个请求, 去更新令牌https://b.com/oauth/token? grant_type=refresh_token& client_id=CLIENT_ID& client_secret=CLIENT_SECRET& refresh_token=REFRESH_TOKEN # grant_type参数为refresh_token表示要求更新令牌 # client_id参数和client_secret参数用于确认身份 # refresh_token参数就是用于更新令牌的令牌
- B 网站颁发令牌的时候, 一次性颁发两个令牌, 一个用于获取数据, 另一个用于获取新的令牌(
B 网站验证通过以后, 就会颁发新的令牌.
2FA
双因素认证 (Two-factor authentication)
一般来说, 三种不同类型的证据, 可以证明一个人的身份:
- 秘密信息:只有该用户知道、其他人不知道的某种信息, 比如密码.
- 个人物品:该用户的私人物品, 比如身份证、钥匙.
- 生理特征:该用户的遗传特征, 比如指纹、相貌、虹膜等等.
这些证据就称为三种”因素”(factor). 因素越多, 证明力就越强, 身份就越可靠. 双因素认证就是指, 通过认证同时需要两个因素的证据.
方案:
- Security Device (device / mobile phone)
- SMS
- TOTP (Time-based One-time Password)
- 公认的可靠解决方案, 已经写入国际标准 RFC6238
- 步骤:
- 用户开启双因素认证后, 服务器生成一个密钥
- 服务器提示用户扫描二维码(或者使用其他方式), 把密钥保存到用户的手机. 也就是说, 服务器和用户的手机, 现在都有了同一把密钥
- 密钥必须跟手机绑定. 一旦用户更换手机, 就必须生成全新的密钥.
- 用户登录时, 手机客户端使用这个密钥和当前时间戳, 生成一个哈希, 有效期默认为30秒. 用户在有效期内, 把这个哈希提交给服务器
- 服务器也使用密钥和当前时间戳, 生成一个哈希, 跟用户提交的哈希比对. 只要两者不一致, 就拒绝登录
TOTP算法: 问题:手机客户端和服务器, 如何保证30秒期间都得到同一个哈希呢?
答案:
TC = floor((unixtime(now) − unixtime(T0)) / TS)
上面的公式中, TC 表示一个时间计数器, unixtime(now)是当前 Unix 时间戳, unixtime(T0)是约定的起始时间点的时间戳, 默认是0, 也就是1970年1月1日. TS 则是哈希有效期的时间长度, 默认是30秒. 因此, 上面的公式就变成下面的形式.
TC = floor(unixtime(now) / 30)
所以, 只要在 30 秒以内, TC 的值都是一样的. 前提是服务器和手机的时间必须同步.
然后就可以算出哈希了
TOTP = HASH(SecretKey, TC)
上面代码中, HASH就是约定的哈希函数, 默认是 SHA-1.
TOTP 有硬件生成器和软件(Google Authenticator)生成器之分, 都是采用上面的算法.
TCP/IP
- TCP/IP模型是一系列网络协议的总称, 这些协议的目的, 就是使计算机之间可以进行信息交换
- “协议”可以理解成机器之间交谈的语言, 每一种协议都有自己的目的
- TCP/IP模型一共包括几百种协议, 对互联网上交换信息的各个方面都做了规定
- 总称为’互联网协议’(Internet Protocol Suite)
- 四层结构, 自上而下是:
- Application Layer: 负责传送各种最终形态的数据, 是直接与用户打交道的层, 典型协议是HTTP、FTP等
- Transport Layer: 负责传送文本数据, 主要协议是TCP协议
- Internet Layer: 负责分配地址和传送二进制数据, 主要协议是IP协议
- Network Access Layer: 负责建立电路连接, 是整个网络的物理基础, 典型的协议包括以太网、ADSL等等
- 科学家在70年代设计互联网的原始目的, 就是为了传输文本. 所有协议最初都是为了这个目标而设计的, 互联网架构的核心就是文本对话
- 例子 - 用Telnet建立HTTP对话:
- telnet命令本身就是一个应用层协议, 它的作用是在两台主机间, 建立一个TCP连接, 也就是打开两台主机间文本传输的一个通道
- “telnet google.com 80”表示建立本机与google.com在80端口的一个文本传输通道
- 80端口是HTTP协议的端口
- 步骤:
homebrew install telnet- 在命令行输入
telnet google.com 80 - 按下
ctrl + ] - 输入
set localecho - 按回车两下
- 输入文本, 将直接和google.com主机进行对话
- 输入’hi’, 得到
400 Bad Request. 因为发言必须遵守HTTP协议, 这样Google才能看懂 
- 再次尝试并输入
GET / HTTP/1.1, 表示向google索要首页根文件, 使用的协议是HTTP的1.1版本 - 得到
200 OK和回应如下 
正向代理与反向代理
代理 - proxy - 代替某人来处理某事
常见的代理分两种:
- 正向代理
- 反向代理
不管哪种代理, 它们都位于客户端和服务器之间, 将传统的 客户端 <-> 服务器 通信变成了 客户端 <-> 代理 <-> 服务器 通信
正向代理
正向代理用于代理客户端, 此时在服务器看来, 代理就是客户端, 服务器不知道真正客户端的存在.
一般情况下, 代理和客户端位于一个内网中, (客户端 <-> 代理) <-> 服务器. 客户端不需要直接将请求发给服务器, 而是发给代理, 由代理代为请求服务器并返回结果.
作用:
- 突破限制
- 比如有五台服务器, 位于一个内网中, 但是只有一台可以访问公网. 那么此时通过配置这台服务器作为正向代理, 其他四台服务器便也都可以访问公网, 这个场景在云服务器中很常见
- 比如科学上网软件, 实际上也是一个正向代理. 由于计算机无法直接访问敏感网站, 但是代理服务器可以, 而计算机访问代理服务器又是没问题的. 因此, 通过使用代理服务器, 便可以间接访问到敏感的网站
- 流量控制与流量统计
- 由于所有的流量都经过代理, 通过配置代理, 可以对流量进行任意控制. 比如, 不允许访问淘宝等, 很多公司会对员工的网络访问进行限制, 便是通过正向代理实现
- 也可以对流量进行统计. 通过解析代理的访问日志, 使用一些类似 awstats 的工具, 便可以得到流量的详细统计信息
- 提升性能
- 正向代理可以缓存经常被访问的网站, 从而大幅提升访问速度
反向代理
反向代理用于代理服务器, 此时在客户端看来, 代理就是服务器, 客户端不知道真正服务器的存在.
一般情况下, 代理和服务器位于一个内网中, 客户端 <-> (代理 <-> 服务器). 服务器不需要直接和客户端沟通, 而是通过代理, 由代理接收客户端的请求, 再发送给服务器.
作用:
- 突破限制
- 比如内网中的某个服务器, 如果想要在公网访问, 我们可以配置内网中拥有公网IP的机器作为反向代理, 从而实现对内网服务的访问
- 负载均衡
- 可以部署多台服务器, 配置代理将请求转发给不同的服务器. 这里有很多算法可以使用, 比如最简单的轮流转发 (Round Robin). 这样, 当负载增大的时候, 客户端无需做任何修改, 服务端通过简单的增加服务器便可以应对
- 负载均衡的另一个好处是可以实现容灾容错. 如果某台服务器宕机了, 代理服务器会将请求转发到其他服务器上, 客户端不会受到任何影响.
- 访问加速
- 对于某些大型服务, 他们的服务器遍布各地, 通过使用反向代理, 当请求到来时, 代理可以将请求转发给最近的服务器, 从而让用户在最短时间内获得响应, 这一点其实和 CDN 的工作方式是一样的
透明代理和显式代理
透明代理 这个概念只有正向代理才有, 因为所有的反向代理在客户端看来都是透明的, 客户端不知道请求对象是反向代理还是真正的服务器.
当使用正向代理的时候, 有两种方式:
- 客户端显式配置使用代理, 此时客户端知道正向代理的存在, 所以是显式代理
- 客户端没有进行任何配置, 但所有流量还是经过了代理, 因为客户端不知道代理的存在, 所以是透明代理
显式代理:
- 很多软件都提供设置代理选项, 比如 Chrome, 在设置完代理以后, Chrome 就会使用代理进行通信, 此时是显式代理
- 设置代理的时候需要设置代理协议, 常见的代理协议有
http,https,socks4,socks5 - 例子 - 使用 HTTP 协议代理 HTTPS 流量:
- HTTP 有一个 CONNECT 方法, 可以创建一条 HTTP 隧道, 用来转发任意的 TCP 流量
- 通过使用 CONNECT 方法, HTTP 协议可以代理任意的基于 TCP 的协议, 当然也包括 HTTPS
- 假设配置 Chrome 使用一个 HTTP 代理, 当 Chrome 遇到 HTTP 请求时, 直接转发给代理, 不做任何处理
- 当遇到 HTTPS 请求时, Chrome 会首先使用 CONNECT 方法请求代理, 请求中含有目标地址的的域名和端口, 代理收到以后, 会创建一条到目标地址的 TCP 链接, 创建成功以后, 返回 200 Connection established 给 Chrome. 之后, Chrome 会将 HTTPS 数据包发给代理, 而代理会原封不动的发给目标地址, 代理此时就像隧道一样, 沟通目标地址和客户端
透明代理:
- 显式代理必须要手动配置, 如果有很多客户端的话就很不方便.这个时候可以使用透明代理技术.
- 通过在路由器层将数据包直接转发给代理软件, 实现客户端无需配置, 但是仍然使用代理来访问网络.
- Q: 代理如何知道数据包的原始目标地址?
- 假设访问百度, 浏览器构建一个 HTTP 数据包, 目标地址为百度 IP 和 80 端口, 经过路由器的时候, 路由器转发给到了代理, 此时, 数据包的目标地址被修改为代理 IP 和代理端口.
- 当代理收到数据包以后, 如何知道数据包下一步该发送给谁呢?
- A:
- 因为 HTTP/1.1 要求所有的请求必须包含 HOST 头, 代理可以通过解析 HOST 得到目标地址
- 通过使用 SO_ORIGINAL_DST 选项获取数据包原始地址
SSL/TLS协议
SSL协议(Secure Sockets Layer)
TLS协议(Transport Layer Security)
作用
HTTP 是非常不安全的, 不安全的根源在于 HTTP 是明文传输. 不使用SSL/TLS的HTTP通信, 就是不加密的通信, d就等于所有信息明文传播, 因而带来了三大风险:
- 窃听风险(eavesdropping): 第三方可以获知通信内容
- 篡改风险(tampering): 第三方可以修改通信内容
- 冒充风险(pretending): 第三方可以冒充他人身份参与通信
SSL/TLS协议是为了解决这三大风险而设计的, 希望达到:
- 所有信息都是加密传播, 第三方无法窃听
- 具有校验机制, 一旦被篡改, 通信双方会立刻发现
- 配备身份证书, 防止身份被冒充
运行过程
SSL/TLS协议的基本思路是采用公钥加密法(Public-key cryptography) - RSA 非对称加密, 即客户端先向服务器端索要公钥, 然后用公钥加密信息, 服务器收到密文后, 用自己的私钥解密.
Q: 如何保证公钥不被篡改?
A: 将公钥放在数字证书(Public key certificate)中. 只要证书是可信的, 公钥就是可信的
Q: 公钥加密计算量太大, 如何减少耗用的时间?
A: 每一次对话(session), 客户端和服务器端都生成一个”对话密钥”(session key), 用它来加密信息. 由于”对话密钥”是对称加密, 所以运算速度非常快, 而服务器公钥只用于加密”对话密钥”本身, 这样就减少了加密运算的消耗时间
SSL/TLS协议的基本过程 (前两步称为握手阶段(handshake)):
- 客户端向服务器端索要并验证公钥
- 双方协商生成”对话密钥”
- 双方采用”对话密钥”进行加密通信
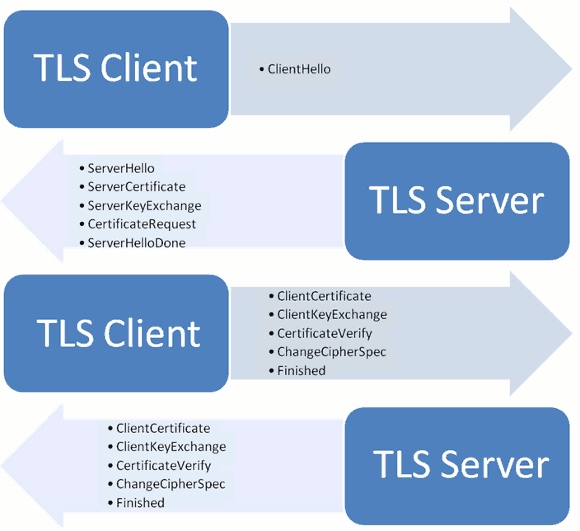
注意: “握手阶段”的所有通信都是明文的
客户端发出请求(ClientHello)
客户端(通常是浏览器)先向服务器发出加密通信的请求, 这被叫做ClientHello请求. 客户端主要向服务器提供以下信息:
- 支持的协议版本, 比如TLS 1.0版
- 一个客户端生成的随机数, 稍后用于生成”对话密钥”
- 支持的加密方法, 比如RSA公钥加密
- 支持的压缩方法
注意: 客户端发送的信息之中不包括服务器的域名, 即理论上服务器只能包含一个网站, 否则会分不清应该向客户端提供哪一个网站的数字证书. 这对于虚拟主机的用户来说, 这当然很不方便. 所以TLS协议加入了一个Server Name Indication扩展, 允许客户端向服务器提供它所请求的域名.
服务器回应(SeverHello)
服务器收到客户端请求后, 向客户端发出回应, 这叫做SeverHello. 服务器的回应包含以下内容:
- 确认使用的加密通信协议版本, 比如TLS 1.0版本. 如果浏览器与服务器支持的版本不一致, 服务器关闭加密通信
- 一个服务器生成的随机数, 稍后用于生成”对话密钥”
- 确认使用的加密方法, 比如RSA公钥加密
- 服务器证书
客户端回应
客户端收到服务器回应以后, 首先验证服务器证书. 如果证书不是可信机构颁布、或者证书中的域名与实际域名不一致、或者证书已经过期, 就会向访问者显示一个警告, 由其选择是否还要继续通信.
如果证书没有问题, 客户端就会从证书中取出服务器的公钥. 然后, 向服务器发送下面三项信息:
- 一个随机数. 该随机数用服务器公钥加密, 防止被窃听
- 编码改变通知, 表示随后的信息都将用双方商定的加密方法和密钥发送
- 客户端握手结束通知, 表示客户端的握手阶段已经结束
- 这一项同时也是前面发送的所有内容的hash值, 用来供服务器校验
上面第一项的随机数, 是整个握手阶段出现的第三个随机数, 又称”pre-master key”. 有了它以后, 客户端和服务器就同时有了三个随机数, 接着双方就用事先商定的加密方法, 各自生成本次会话所用的同一把”会话密钥”.
- Q: 为什么一定要用三个随机数, 来生成”会话密钥”?
- A:
- 不管是客户端还是服务器, 都需要随机数, 这样生成的密钥才不会每次都一样. 由于SSL协议中证书是静态的, 因此十分有必要引入一种随机因素来保证协商出来的密钥的随机性.
- 对于RSA密钥交换算法来说, pre-master-key本身就是一个随机数, 再加上hello消息中的随机, 三个随机数通过一个密钥导出器最终导出一个对称密钥
- pre master的存在在于SSL协议不信任每个主机都能产生完全随机的随机数, 如果随机数不随机, 那么pre master secret就有可能被猜出来, 那么仅适用pre master secret作为密钥就不合适了, 因此必须引入新的随机因素, 那么客户端和服务器加上pre master secret三个随机数一同生成的密钥就不容易被猜出了, 一个伪随机可能完全不随机, 可是是三个伪随机就十分接近随机了, 每增加一个自由度, 随机性增加的可不是一
服务器的最后回应
服务器收到客户端的第三个随机数pre-master key之后, 计算生成本次会话所用的”会话密钥”
向客户端最后发送下面信息:
- 编码改变通知, 表示随后的信息都将用双方商定的加密方法和密钥发送
- 服务器握手结束通知, 表示服务器的握手阶段已经结束
- 这一项同时也是前面发送的所有内容的hash值, 用来供客户端校验
至此, 整个握手阶段全部结束. 接下来, 客户端与服务器进入加密通信, 就完全是使用普通的HTTP协议(文本传输), 只不过用”会话密钥”加密内容.
HTTPS
HTTPS 便是 HTTP Over SSL, 使用 SSL 协议来加密 HTTP 通讯过程. SSL 协议本质上是提供了一个加密通道, 在这个通道中传输 HTTP, 便是 HTTPS 协议.
证书
要想进行 SSL 通信, 服务器需要有一个权威机构认证的证书. 证书是一个二进制文件, 里面包含有一些信息(服务器的公钥, 域名, 有效时间等). 和域名一样, 证书需要购买, 并且价格不菲. 下面是三个常用的购买证书的网站.
- GoGetSSL
- SSLs.com
- SSLmate.com
证书分为很多类型, 首先分为三级认证:
- 域名认证(Domain Validation, DV):最低级的认证, CA 只检查申请者拥有某个域名, 对于这种证书, 浏览器会在地址栏显示一把绿色的小锁
- 组织认证(Organization Validation, OV):CA 除了检查域名所有权以外, 还会审核组织信息. 对于这类认证, 浏览器会在地址栏中显示公司信息
- 扩展认证(Extended Validation, EV):最高级别的认证, 相比于组织认证, CA 会对组织信息进行更加严格的审核
除了三个级别以外, 证书还分为三个覆盖范围:
- 单域名证书:只能用于单一域名, a.com 的证书不能用于 www.a.com
- 通配符证书:可以用于域名下的所有子域名, *.a.com 的证书可以用于 a.com, 也可以用于 www.a.com
- 多域名证书, 可以用于多个域名, 比如 a.com, b.com
很显然, 认证级别越高, 覆盖范围越广, 证书价格越贵. 好消息是, 为了推广 HTTPS 协议, 电子前哨基金会 EFF 成立了 Let’s Encrypt, 可以提供免费证书
拿到证书以后, 可以用 SSL Certificate Check 检查一下, 信息是否正确
敏捷开发 (Agile Development)
- 迭代开发
- 敏捷开发的核心是迭代开发(iterative development). 敏捷一定是采用迭代开发 (重复开发)的方式.
- 对于大型软件项目, 传统的开发方式是采用一个大周期(比如一年)进行开发, 整个过程就是一次”大开发”;迭代开发的方式则不一样, 它将开发过程拆分成多个小周期, 即一次”大开发”变成多次”小开发”, 每次小开发都是同样的流程, 所以看上去就好像重复在做同样的步骤.
- E.g. SpaceX 公司想造一个大推力火箭, 将人类送到火星. 但是, 它不是一开始就造大火箭, 而是先造一个最简陋的小火箭 Falcon 1. 结果, 第一次发射就爆炸了, 直到第四次发射, 才成功进入轨道. 然后, 开发了中型火箭 Falcon 9, 九年中发射了70次. 最后, 才开发 Falcon 重型火箭. 如果 SpaceX 不采用迭代开发, 它可能直到现在还无法上天.
- 迭代开发将一个大任务, 分解成多次连续的开发, 本质就是逐步改进. 开发者先快速发布一个有效但不完美的最简版本, 然后不断迭代. 每一次迭代都包含规划、设计、编码、测试、评估五个步骤, 不断改进产品, 添加新功能. 通过频繁的发布, 以及跟踪对前一次迭代的反馈, 最终接近较完善的产品形态.
- 增量开发
- 迭代开发要求将开发分成多个迭代, 然后采用”增量开发”(incremental development)划分迭代.
- 所谓”增量开发”, 指的是软件的每个版本, 都会新增一个用户可以感知的完整功能. 也就是说, 按照新增功能来划分迭代.
- E.g. 房产公司开发一个10栋楼的小区. 如果采用增量开发的模式, 该公司第一个迭代就是交付一号楼, 第二个迭代交付二号楼……每个迭代都是完成一栋完整的楼. 而不是第一个迭代挖好10栋楼的地基, 第二个迭代建好每栋楼的骨架, 第三个迭代架设屋顶……
- 增量开发加上迭代开发, 才算真正的敏捷开发.
- 好处
- 早期交付: 大大降低成本.
- 还是以房产公司为例, 如果按照传统的”瀑布开发模式”, 先挖10栋楼的地基、再盖骨架、然后架设屋顶, 每个阶段都等到前一个阶段完成后开始, 可能需要两年才能一次性交付10栋楼. 也就是说, 如果不考虑预售, 该项目必须等到两年后才能回款.
- 敏捷开发是六个月后交付一号楼, 后面每两个月交付一栋楼. 因此, 半年就能回款10%, 后面每个月都会有现金流, 资金压力就大大减轻了.
- 降低风险: 及时了解市场需求, 降低产品不适用的风险.
- 哪一种情况损失比较小:10栋楼都造好以后, 才发现卖不出去, 还是造好第一栋楼, 就发现卖不出去, 从而改进或停建后面9栋楼?
- 对于软件项目来说, 先有一个原型产品, 了解市场的接受程度, 往往是项目成功的关键. 有一本书叫做《梦断代码》, 副标题就是”20+个程序员, 三年时间, 4732个bug, 100+万美元, 最后失败的故事”, 这就是没有采用敏捷开发的结果. 相反的, Instagram 最初是一个地理位置打卡 App, 后来发现用户不怎么在乎地理位置, 更喜欢上传照片, 就改做照片上传软件, 结果成了独角兽.
- 由于敏捷开发可以不断试错, 找出对业务最重要的功能, 然后通过迭代, 调整软件方向. 相比传统方式, 大大增加了产品成功的可能性. 如果市场需求不确定, 或者你对该领域不熟悉, 那么敏捷开发几乎是唯一可行的应对方式.
- 早期交付: 大大降低成本.
- 如何进行每一次迭代
- 虽然敏捷开发将软件开发分成多个迭代, 但是也要求, 每次迭代都是一个完整的软件开发周期, 必须按照软件工程的方法论, 进行正规的流程管理.
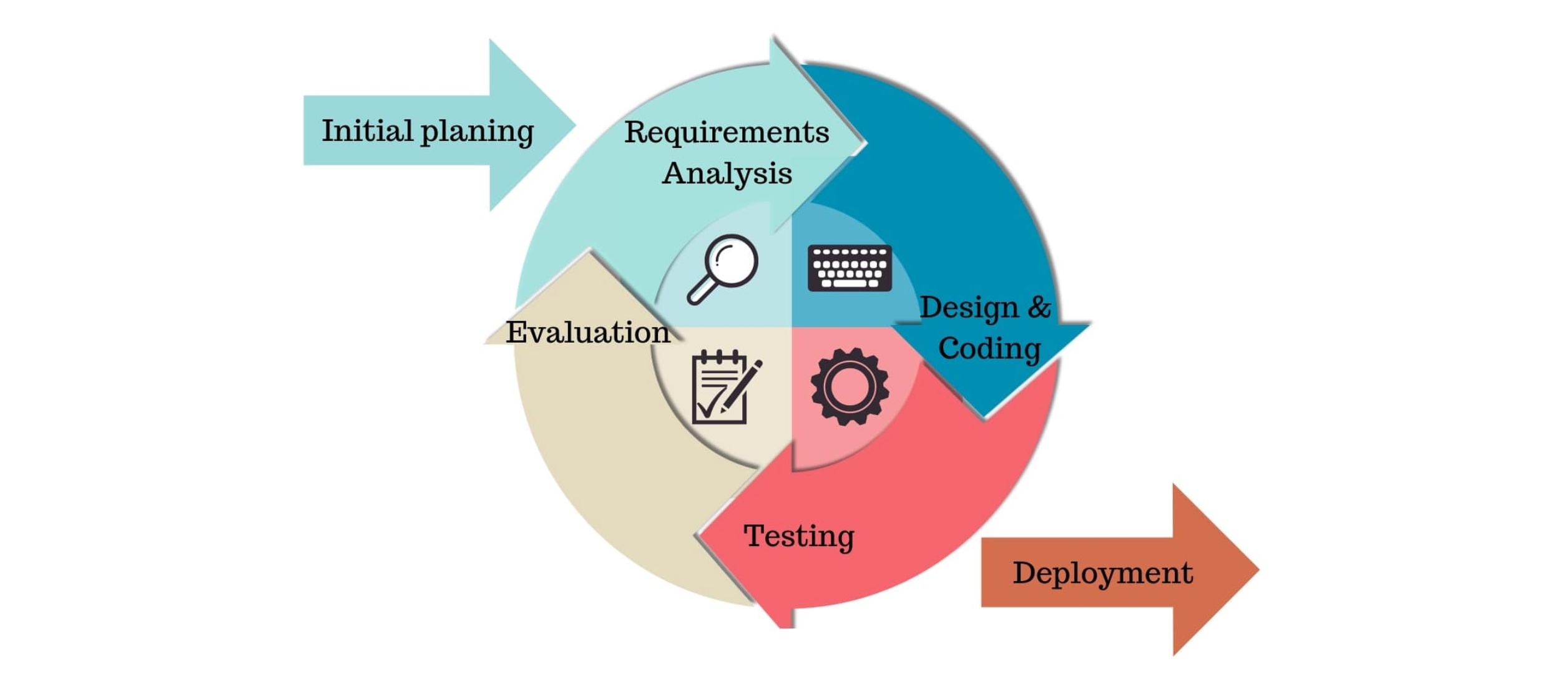
- 每次迭代都必须依次完成以下五个步骤(每个迭代大约持续2~6周):
- 需求分析(requirements analysis)
- 设计(design)
- 编码(coding)
- 测试(testing)
- 部署和评估(deployment / evaluation)
- 价值观
- 程序员的主观能动性, 以及程序员之间的互动, 优于既定流程和工具.
- 软件能够运行, 优于详尽的文档.
- 跟客户的密切协作, 优于合同和谈判.
- 能够响应变化, 优于遵循计划.
- 十二条原则
- 通过早期和持续交付有价值的软件, 实现客户满意度.
- 欢迎不断变化的需求, 即使是在项目开发的后期. 要善于利用需求变更, 帮助客户获得竞争优势.
- 不断交付可用的软件, 周期通常是几周, 越短越好.
- 项目过程中, 业务人员与开发人员必须在一起工作.
- 项目必须围绕那些有内在动力的个人而建立, 他们应该受到信任.
- 面对面交谈是最好的沟通方式.
- 可用性是衡量进度的主要指标.
- 提倡可持续的开发, 保持稳定的进展速度.
- 不断关注技术是否优秀, 设计是否良好.
- 简单性至关重要, 尽最大可能减少不必要的工作.
- 最好的架构、要求和设计, 来自团队内部自发的认识.
- 团队要定期反思如何更有效, 并相应地进行调整
CI/CD
- 持续集成
- 持续集成指的是, 频繁地(一天多次)将代码集成到主干
- 互联网软件的开发和发布, 已经形成了一套标准流程, 最重要的组成部分就是持续集成(Continuous integration, 简称CI)
- 好处:
- 快速发现错误. 每完成一点更新, 就集成到主干, 可以快速发现错误, 定位错误也比较容易.
- 防止分支大幅偏离主干. 如果不是经常集成, 主干又在不断更新, 会导致以后集成的难度变大, 甚至难以集成.
- 持续集成的目的, 就是让产品可以快速迭代, 同时还能保持高质量. 它的核心措施是, 代码集成到主干之前, 必须通过自动化测试. 只要有一个测试用例失败, 就不能集成.
- 持续集成并不能消除Bug, 而是让它们非常容易发现和改正
- 持续交付
- 持续交付(Continuous delivery)指的是, 频繁地将软件的新版本, 交付给质量团队或者用户, 以供评审. 如果评审通过, 代码就进入生产阶段
- 持续交付可以看作持续集成的下一步. 它强调的是, 不管怎么更新, 软件是随时随地可以交付的
- 持续部署
- 持续部署(continuous deployment)是持续交付的下一步, 指的是代码通过评审以后, 自动部署到生产环境
- 持续部署的目标是, 代码在任何时刻都是可部署的, 可以进入生产阶段
- 持续部署的前提是能自动化完成测试、构建、部署等步骤
持续部署与持续交付的区别:
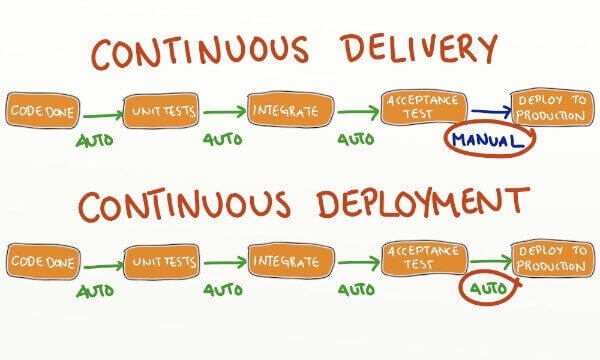
CICD流程:
- 提交: 流程的第一步, 是开发者向代码仓库提交代码. 所有后面的步骤都始于本地代码的一次提交(commit)
- 测试(第一轮): 代码仓库对commit操作配置了钩子(hook), 只要提交代码或者合并进主干, 就会跑自动化测试(第一轮至少要跑单元测试). 测试种类:
- 单元测试:针对函数或模块的测试
- 集成测试:针对整体产品的某个功能的测试, 又称功能测试
- 端对端测试:从用户界面直达数据库的全链路测试
- 构建: 通过第一轮测试, 代码就可以合并进主干, 就算可以交付了
- 交付后, 就先进行构建(build), 再进入第二轮测试. 所谓构建, 指的是将源码转换为可以运行的实际代码, 比如安装依赖, 配置各种资源(样式表、JS脚本、图片)等等
- 常用的构建工具如下:
- Jenkins
- Travis
- Codeship
- Strider
- Jenkins和Strider是开源软件, Travis和Codeship对于开源项目可以免费使用. 它们都会将构建和测试, 在一次运行中执行完成.
- 测试(第二轮): 构建完成, 就要进行第二轮测试. 如果第一轮已经涵盖了所有测试内容, 第二轮可以省略, 当然, 这时构建步骤也要移到第一轮测试前面
- 第二轮是全面测试, 单元测试和集成测试都会跑, 有条件的话, 也要做端对端测试. 所有测试以自动化为主, 少数无法自动化的测试用例, 就要人工跑
- 需要强调的是, 新版本的每一个更新点都必须测试到. 如果测试的覆盖率不高, 进入后面的部署阶段后, 很可能会出现严重的问题
- 部署: 通过了第二轮测试, 当前代码就是一个可以直接部署的版本(artifact). 将这个版本的所有文件打包(
tar filename.tar *)存档, 发到生产服务器- 生产服务器将打包文件, 解包成本地的一个目录, 再将运行路径的符号链接(symlink)指向这个目录, 然后重新启动应用. 这方面的部署工具有Ansible, Chef, Puppet等
- 回滚: 一旦当前版本发生问题, 就要回滚到上一个版本的构建结果.最简单的做法就是修改一下符号链接, 指向上一个版本的目录
DevOps
DevOps(英文Development和Operations的组合)是一组过程、方法与系统的统称,用于促进开发(应用程序/软件工程)、技术运营和质量保障(QA)部门之间的沟通、协作与整合
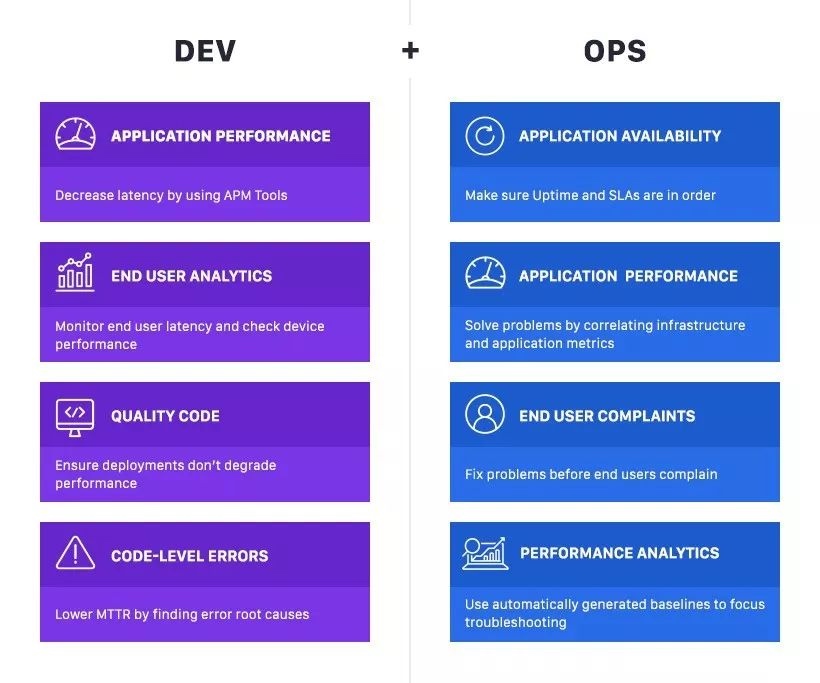
业界真正开始大规模落地 DevOps, 离不开容器化技术. “Docker”起到了决定性作用,通过编写 Dockerfile,第一次可以让开发者轻松定义软件运行环境,并且能通过 CI/CD 标准化流程去交付它. 不过这么多容器运维起来仍然麻烦,于是 google 在 2014 年开源“k8s”(Kubernetes); 2015 年 CNCF(Cloud Native Computing Foundation 云原生计算基金会)成立,正式将“k8s”作为核心,建立了一个巨大的生态系统. 有了“docker”和“k8s”技术上助力,加速了开发和运维角色的融合,于是 DevOps 不再是空中楼阁(落地).
发展阶段:
微服务 => 容器化 => 云原生
在云原生(Cloud Native)时代, 有三个核心技术:
- 关于 开发 的 CloudIDE
- CloudIDE 将开发环境搬到了云上,而且可以和研发平台深度整合,为开发者提供极致的编程体验,再也不用关心我在哪里开发,只要有浏览器,打开就可以编码
- 关于 运行 的 Service Mesh
- 中间件在云时代会逐渐融入到 Service Mesh 技术下,服务路由、限流降级等开发者将不再关心
- E.g. AWS API gateway
- 关于 运维 的 Serverless
- Serverless 技术让自动扩缩,容量评估变为历史,开发者再也不关心机器在哪
- E.g. AWS lambda
MACBOOK
Mac键盘符号和修饰键说明
- ⌘ Command
- ⇧ Shift
- ⌥ Option
- ⌃ Control
- ↩︎ Return/Enter
- ⌫ Delete
- ⌦ 向前删除键(Fn+Delete)
- ↑ 上箭头
- ↓ 下箭头
- ← 左箭头
- → 右箭头
- ⇞ Page Up(Fn+↑)
- ⇟ Page Down(Fn+↓)
- Home Fn + ←
- End Fn + →
- ⇥ 右制表符(Tab键)
- ⇤ 左制表符(Shift+Tab)
- ⎋ Escape (Esc)
pycharm 快捷键:
- cmd b 跳转到声明处(cmd加鼠标)
- opt + 空格 显示符号代码 (esc退出窗口 回车进入代码)
- cmd []光标之前/后的位置
- opt + F7 find usage
- cmd backspace 删除当前行
- cmd +c 复制光标当前行,剪切同理
- cmd + f 当前文件搜索(回车下一个 shift回车上一个)
- cmd + r 当前文件替换
- shift + cmd + f 全局搜索
- shift + cmd + R 全局替换
- cmd+o 搜索class
- shift + cmd + o 搜索文件
- opt + cmd + o 搜索符号(函数等)
- cmd + l 指定行数跳转
- shift enter 在行中的时候直接到下一行
- cmd + 展开当前
- cmd - 折叠当前
- shift cmd + 展开所有
- shift cmd - 折叠所有
- cmd / 注释/取消注释一行
- opt + cmd + / 批量注释(pycharm不生效)
- ctr + tab 史上最NB的导航窗口(工程文件列表、文件结构列表、命令行模式、代码检查、VCS等, 下面两个是可以被替换的)
- alt + F12 打开命令行栏
- cmd + F12 显示文件结构
- cmd j 代码智能补全
- alt + F1 定位编辑文件所在位置:
- cmd + F6 更改变量
- opt + cmd + t 指定代码被注释语句或者逻辑结构、函数包围
- Tab / Shift + Tab 缩进、不缩进当前行
- opt + cmd + l 代码块对齐
- cmd+d 在下一行复制本行的内容
go to folder command: command+shift+G
software:
- turbo boost switchcer
- Iterm2:
brew cask install iterm2
关闭 macOS Google Chrome 黑暗模式风格 (Chrome随Mac系统的暗黑模式改变的). 步骤:
- 打开终端:
- 执行命令:
defaults write com.google.Chrome NSRequiresAquaSystemAppearance -bool YES - 重启浏览器:修改效果恢复正常-白色效果
- 重新使用暗黑模式:
defaults write com.google.Chrome NSRequiresAquaSystemAppearance -bool NO
Jupyter Notebook Viewer
- https://github.com/tuxu/nbviewer-app
- can either download the app from that page or install using brew cask:
brew cask install jupyter-notebook-viewer - If the preview is not working you should reload quicklook.
Just open a terminal windows and run. It worked for me on macOS High Sierra.
qlmanage -r
NP-hardness
- 多项式级的复杂度:O(1), O(n),O(n^2),O(lg(n)),O(nlg(n))
- 非多项式级的复杂度:O(2^n),O(n!)
NP:
- P问题:可以在多项式时间内找到解决该问题的算法
- NP问题:可以在多项式的时间里验证该问题的一个解
- NPC问题:是一个NP问题, 并且所有的NP问题都可以约化到该问题
- NP-hard问题:不一定是一个NP问题, 但所有的NP问题都可以约化到该问题
ref:
Hugo Blog
Theme: https://github.com/luizdepra/hugo-coder
official doc: https://gohugo.io/getting-started/quick-start/
用S3+cloudfront托管
网页加载时, 只要不是服务器动态生成的内容, 都属于静态资源. 由于静态资源不用动态生成, 所以可以发到 CDN 加快网页加载. 本文介绍如何通过亚马逊网络服务的 S3 + CloudFront 实现一个自己的 CDN, 分发静态资源
https://www.sankalpjonna.com/posts/hosting-your-entire-web-application-using-s3-cloudfront
用 firebase 来托管博客
firebase 提供的免费托管特性如下:
- 可存储的免费空间为 1 GB
- 每个月免费流量为 10 GB
- 可免费自定义域名, 并配有免费 SSL 证书
- 免费 CDN
- 可回滚的部署历史记录
创建项目
首先登录 https://console.firebase.google.com 创建一个新项目. 注意, 创建过程中页面会默认生成一个 Project ID, 也可以自己填写, 它将决定网站托管在 firebase 上的子域名, 比如填入 google, 则最后你的博客将托管在 google.firebase.com 域名 - 一旦创建后就不能再修改
安装 Firebase 命令行工具
需要预先安装 firebase-tools, 这是一个基于 Node.js 的工具包, 通过 npm 或是 yarn来安装:
$ yarn global add firebase-toolsfirebase login
在终端窗口执行 firebase login, 浏览器会自动打开一个请求授权的网址.
返回一串 token, 将该 token 拷入命令行回车即可完成登录.
初始化 firebase
命令行下登录 firebase 后, 切换到博客根目录, 初始化:
$ cd HugoBlog
$ firebase init
🔥🔥🔥🔥🔥🔥🔥🔥 🔥🔥🔥🔥 🔥🔥🔥🔥🔥🔥🔥🔥 🔥🔥🔥🔥🔥🔥🔥🔥 🔥🔥🔥🔥🔥🔥🔥🔥 🔥🔥🔥 🔥🔥🔥🔥🔥🔥 🔥🔥🔥🔥🔥🔥🔥🔥
🔥🔥 🔥🔥 🔥🔥 🔥🔥 🔥🔥 🔥🔥 🔥🔥 🔥🔥 🔥🔥 🔥🔥 🔥🔥
🔥🔥🔥🔥🔥🔥 🔥🔥 🔥🔥🔥🔥🔥🔥🔥🔥 🔥🔥🔥🔥🔥🔥 🔥🔥🔥🔥🔥🔥🔥🔥 🔥🔥🔥🔥🔥🔥🔥🔥🔥 🔥🔥🔥🔥🔥🔥 🔥🔥🔥🔥🔥🔥
🔥🔥 🔥🔥 🔥🔥 🔥🔥 🔥🔥 🔥🔥 🔥🔥 🔥🔥 🔥🔥 🔥🔥 🔥🔥
🔥🔥 🔥🔥🔥🔥 🔥🔥 🔥🔥 🔥🔥🔥🔥🔥🔥🔥🔥 🔥🔥🔥🔥🔥🔥🔥🔥 🔥🔥 🔥🔥 🔥🔥🔥🔥🔥🔥 🔥🔥🔥🔥🔥🔥🔥🔥
You're about to initialize a Firebase project in this directory:
/Users/Charon/Documents/HugoBlog
? Which Firebase CLI features do you want to setup for this folder? Press Space to select features, then Ente
r to confirm your choices. (Press <space> to select)
❯◯ Database: Deploy Firebase Realtime Database Rules
◯ Firestore: Deploy rules and create indexes for Firestore
◯ Functions: Configure and deploy Cloud Functions
◯ Hosting: Configure and deploy Firebase Hosting sites
◯ Storage: Deploy Cloud Storage security rules因为只是要托管静态博客, 所以选择 Hosting: Configure and deploy Firebase Hosting sites
稍后关联一个 Firebase 项目
再往后则是:
? What do you want to use as your public directory? (public)
因为静态博客在构建后是放在 dist 目录的, 所以这里填入 dist (默认为 public 目录)
最终, firebase init 命令会生成两个文件:
- firebase.json
- .firebaserc
firebase.json 里面可以做很多事情, 比如设置静态资源的缓存时间:
{
"hosting": {
"public": "dist",
"ignore": ["firebase.json", "**/.*", "**/node_modules/**"],
"headers": [
{
"source": "**/*.@(jpg|jpeg|gif|png|svg|ico)",
"headers": [
{
"key": "Cache-Control",
"value": "no-cache"
}
]
},
{
"source": "**/*.@(js|css)",
"headers": [
{
"key": "Cache-Control",
"value": "max-age=31536000"
}
]
}
]
}
}预览
在部署之前, 可以执行 firebase serve 预览一下, 省得部署后才发现有问题:
$ firebase serve
=== Serving from '/Users/Charon/Documents/HugoBlog'...
i hosting: Serving hosting files from: dist
✔ hosting: Local server: http://localhost:5000部署
接下来就可以部署:
$ firebase deploy --only hosting自定义域名
部署完成后, 就能在
关联自定义域名, 在Hosting 面板下有相应操作指南.
不过, 配置完自定义域名后, 会有两个网址:
.firebaseapp.com - 自定义域名.com
前者是关不掉的. 这是一个问题, 因为搜索引擎会从两个网址抓取到一样的内容, 对 SEO 来讲, 这非常糟糕, 搜索引擎可能会判断为内容抄袭、重复, 导致你的自定义域名被降权. 所以最好使用 rel=canonical 之类的方案给搜索引擎一个说明.
比如博客首页 HTML 代码中会有这样一行:
<link rel="canonical" href="https://charon.me/"/>本地测试
hugo serve生成静态文件command
hugo自动部署
shell script - deploy.sh
#!/bin/bash
hugo
firebase deploy --only hostingrun
./deploy.shHugo & MWEB
Mweb 的另一个优势是无缝插图, 不需要单独拷贝副本到 Hugo 的 /static/img 文件夹中.
MWeb 恰好一个步骤实现了两种不同需求, 只需要启动 MWeb 的外部模式, 要插图时, 只需直接粘贴图片, 或者将图片直接拖到 MWeb 正在编辑的文档中. 图片会自动存储到 /static/img 文件夹中
为了使 Mweb 图床系统增加对 /hugo/static/img 路径的支持, 需要进行设置:
首先用 ⌘+E 引入外部文件夹 (或者直接拖曳 Hugo 目录至 Mweb 左侧目录树):
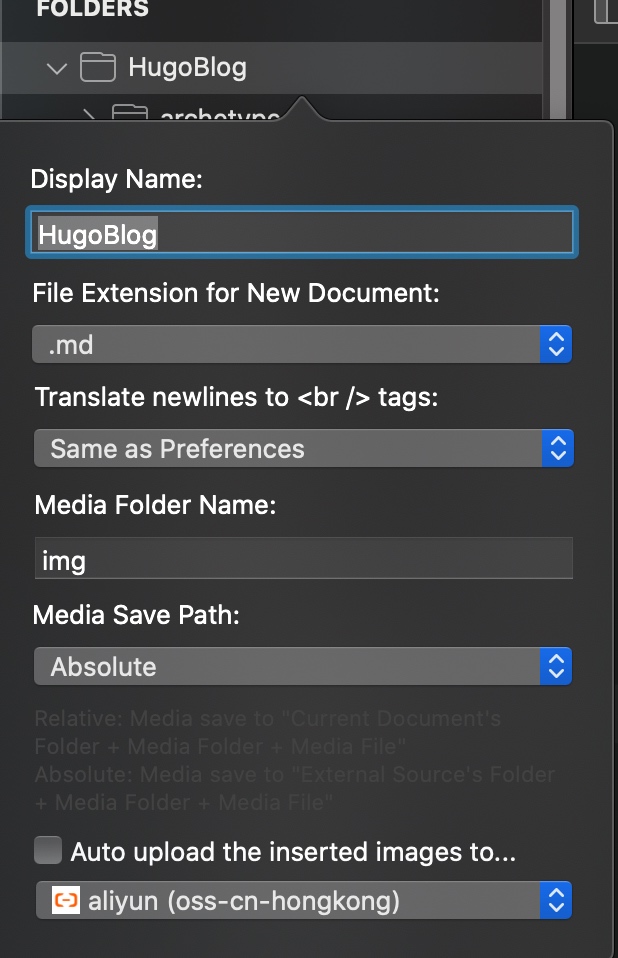
由于 Hugo 的静态资源文件放在 static 目录下, 对于 MWeb 解析来说比较尴尬, 而通常用户会将图片放在诸如 static/img 的文件夹下, 所以解决方案之一是对 static/img 做软链
$ cd <path_to_Hugo>
$ ln -s static/img ./img
//如果要取消, 直接rm删除软链即可同时, 把 Media Folder Name 改为 img, 并把路径改为 Absolute 模式 (右键, edit 得到上图)
Hugo render markdown Table of Content (TOC)
在 /layout/posts/single.html 中引用
{{ if .Params.toc }}
<h4>{{ .TableOfContents }}</h4>
{{ end }}去掉 if 就是全局使用了
Hugo fail to render latex problem
Hugo 的 markdown 渲染模块 blackfriday 会将
`$ 或是 $`$中的 _ 中识别为 <em> 段落, 导致渲染错误.
多数 Markdown 引擎都并不支持数学公式, 所以
`$X_i + Y_i$` 在这些引擎眼中并没有什么特殊含义, 只是普通的 Markdown 文本. 这就麻烦大了, 因为数学公式里的某些字符对 Markdown 来说可能是特殊语法, 例如下划线可能是表示斜体, 那前面这个公式可能会被翻译为
`$X<em>i + Y</em>i$`为了保护公式的内容不被 Markdown 引擎翻译掉, 只好把公式保护在代码标签中, 也就是前后加两个反引号, 例如
``$X_i + Y_i$``这样公式内部的字符不会被当做 Markdown 文本, 而是会被原样输出, 如生成
<code>`$X_i + Y_i$`</code>创建一个新的文件在 /layout/partials/posts 文件夹 名为 mathjax_support.html
<script type="text/javascript" async src="https://cdn.mathjax.org/mathjax/latest/MathJax.js?config=TeX-AMS-MML_HTMLorMML"> MathJax.Hub.Config({ tex2jax: { inlineMath: [['`$','$`'], ['\\(','\\)']], displayMath: [['`$$','$$`']], processEscapes: true, processEnvironments: true, skipTags: ['script', 'noscript', 'style', 'textarea', 'pre'], TeX: { equationNumbers: { autoNumber: "AMS" }, extensions: ["AMSmath.js", "AMSsymbols.js"] } } }); MathJax.Hub.Queue(function() { // Fix <code> tags after MathJax finishes running. This is a // hack to overcome a shortcoming of Markdown. Discussion at // https://github.com/mojombo/jekyll/issues/199 var all = MathJax.Hub.getAllJax(), i; for(i = 0; i < all.length; i += 1) { all[i].SourceElement().parentNode.className += ' has-jax'; } }); MathJax.Hub.Config({ // Autonumbering by mathjax TeX: { equationNumbers: { autoNumber: "AMS" } } }); </script> <style> code.has-jax { font: inherit; font-size: 100%; background: inherit; border: inherit; color: #515151; } </style>在 /layout/posts/single.html 中引用
{{ partial "posts/mathjax_support.html" . }}
这样就全局使用mathjax数学公式了
然后在.md中, 无法正常显示在Latex就用``圈起来
在mweb中全局替换方法:
1. Command + f
2. `$ Any $` replace all by ``$ Any $``ref:
Utterances comment Systemt
- 创建github repo, 记得是public
在 /layout/posts/utterance.html 中引用
{{ if .Site.Params.utteranc.enable }} <div class="post bg-white"> <script src="https://utteranc.es/client.js" repo= "{{ .Site.Params.utteranc.repo }}" issue-term="{{ .Site.Params.utteranc.issueTerm }}" theme="{{ .Site.Params.utteranc.theme }}" crossorigin="anonymous" async> </script> <noscript>Please enable JavaScript to view the <a href="https://github.com/utterance">comments powered by utterances.</a></noscript> </div> {{ end }}在config.toml下添加 (repo名字大小写敏感)
[params.utteranc] enable = true repo = "Charonnnnn/blog-utterances-comments" issueTerm = "pathname" theme = "github-light"
Disqus comment system: https://www.yuque.com/shenweiyan/cookbook/disqus-for-hugo
Hugo 站点统计信息
在_default/baseof 的head里面加
<!-- 不蒜子 --> <script async src="//busuanzi.ibruce.info/busuanzi/2.3/busuanzi.pure.mini.js"></script> <!-- 不蒜子计数初始值纠正 --> <script src="//cdn.bootcss.com/jquery/3.2.1/jquery.min.js"></script> <script> $(document).ready(function() { var int = setInterval(fixCount, 50); function fixCount() { if (document.getElementById('busuanzi_container_site_uv').ownerDocument.defaultView.getComputedStyle(document.getElementById('busuanzi_container_site_uv'), null).display === 'inline') { clearInterval(int); document.getElementById('busuanzi_value_site_uv') = parseInt(document.getElementById('busuanzi_value_site_uv').innerHTML) + parseInt('1000000000000'); } } }); </script>在 /layout/posts/single.html 中引用
<!-- Pageview count--> <span id="busuanzi_container_page_pv"> <i class="fas fa-eye"></i> <span id="busuanzi_value_page_pv" style="color:rgb(38, 142, 177)"></span> views </span>在 /layout/partial/footer.html 中引用
<p> <span id="busuanzi_container_site_pv"> Pageviews: <span id="busuanzi_value_site_pv"></span> </span> <span id="busuanzi_container_site_uv"> Viewers: <span id="busuanzi_value_site_uv"></span> </span> </p>
字体更改
在_default/baseof 的head里面
old:
<link href="https://fonts.googleapis.com/css?family=Lato:400,700%7CMerriweather:300,700%7CSource+Code+Pro:400,700" rel="stylesheet">https://fonts.googleapis.com/css?family=Fira+Mono:400,700new:
<link href="https://fonts.googleapis.com/css?family=Fira+Mono:400,700" rel="stylesheet">在 assets/scss/_variable.scss中修改
// Fonts
$text-font-family: Consolas, Monaco, Menlo, Consolas, monospace;
// $text-font-family: Merriweather, Georgia, serif;
$heading-font-family: Lato, Helvetica, sans-serif;
$code-font-family: 'Source Code Pro', 'Lucida Console', monospace;Google Analytics and Adsence (TBC)
刷访问量 (not working)
代理池:
code
from bs4 import BeautifulSoup
import requests
User_Agent = 'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:43.0) Gecko/20100101 Firefox/43.0'
header = {}
header['User-Agent'] = User_Agent
url = 'https://www.xicidaili.com/wt/1'
req = requests.get(url, headers=header)
res = req.text
soup = BeautifulSoup(res,'html.parser')
ips = soup.findAll('tr')
with open('proxy.txt','w') as f:
for x in range(1,len(ips)):
ip = ips[x]
tds = ip.findAll("td")
ip_temp = tds[1].contents[0]+":"+tds[2].contents[0]+"\n"
# print(tds[1].contents[0]+"\t"+tds[2].contents[0])
print(ip_temp)
f.write(ip_temp)
f.closeimport socket
import time
import random
import requests
from bs4 import BeautifulSoup
socket.setdefaulttimeout(3)
header = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8',
'cache-control': 'max-age=0',
'cookie': '_ga=GA1.2.225936849.1575446526; _gid=GA1.2.753094098.1575446526; _gat_gtag_UA_153869723_1=1',
'if-modified-since': 'Wed, 04 Dec 2019 00:01:11 PST',
'if-none-match': '2206f5fe3533650f10213abc2820f964506a7a3bc3f7312118347bad4f8daafe',
'referer': 'https://charon.me/posts/transformer/',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'same-origin',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
}
user_agent_list = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)',
'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0',
'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
]
proxys = []
with open('proxy.txt', 'r') as f:
lines = f.readlines()
for i in range(0,len(lines)):
# ip = lines[i].strip().split(",")
# proxy_host = "http://"+ip[0]+":"+ip[1]
proxy_host = "http://"+lines[i].strip()
# print(proxy_host)
proxy_temp = {"http": proxy_host}
proxys.append(proxy_temp)
# print(proxys)
urls = {"https://charon.me/",
"https://charon.me/posts/leetcode/time_complexity/",
"https://charon.me/posts/bert",
"https://charon.me/posts/gpt-2/",
"https://charon.me/posts/transformer/",
"https://charon.me/posts/attention/",
}
j=1
print('Begin')
for i in range(100):
for proxy in proxys:
# print(proxy)
for url in urls:
# print(url)
try:
user_agent = random.choice(user_agent_list)
header['User-Agent'] = user_agent
req = requests.get(url=url, headers=header, proxies=proxy)
# res = req.text
req.raise_for_status()
req.encoding = req.apparent_encoding
print ("sucessful",j)
j+=1
time.sleep(5)
except Exception as e:
print(proxy)
print(e)
continue
print('End')