C++
#include <iostream> // 头文件
using namespace std; // 命名空间
int main(){ // 程序开始执行的地方
cout << "Hello World"; // 输出
return 0; // 程序结束状态返回
}
基础语法和编译
C/C++的基本编译和执行过程
- 预处理 (pre processing)
- 编译 (compilation)
- 链接 (link)
- 执行可执行文件 (runtime)
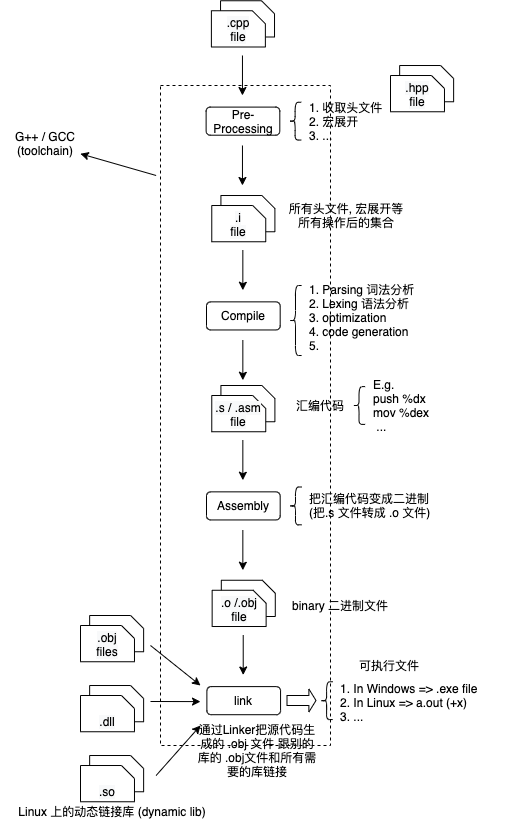
检视过程的command:
# 预处理 (pre processing)
cpp test.cpp > test.i // 将 .cpp 文件转成 .i 文件
# 编译 (compilation)
g++ -g -S test.i // 将 .i 文件转成 .s 文件
# 汇编 (Assembly)
as -0 test.o test.s // 将 .s 文件转成 二进制(.o) 文件
gcc -g -c test.c; objdump -d -M intel -S test.o // 将 cpp 代码插入到 .o 文件中, 方便阅读理解
# 链接 (linker)
ld -o myTest test.o ...[其他连接选项]
# 执行可执行文件
./myTest // 直接运行
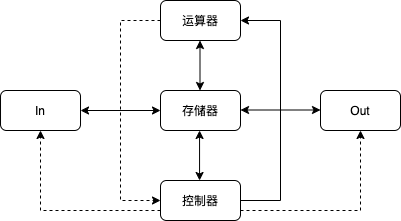
C/C++的计算机基础架构
- 冯诺依曼架构 (普林斯顿架构)
- 一种将程序指令存储器和数据存储器合并在一起的储存器架构
- 好处:
- 程序指令和数据的宽度相同 ==> 使用简单
- 寻址方式简单
- x86中央处理器就是使用该架构
- 计算机三个基本原则:
- 二进制逻辑
- 程序存储执行
- 计算机由5个部分组成
- 特点:
- 单处理机结构, 机器以存储器为中心, 采用程序存储思想
- 指令和数据一样可以参与运算
- 数据以二进制表示
- 将软件和硬件完全分离
- 指令由操作码和操作数组成
- 指令顺序执行
- 对手:
- 哈佛结构 (主要区别:指令和数据分开存储 )
C/C++核心调式技术: GDB
使用方式:
- 直接调式executable: gdb –tui
- 通过Emacs+GUD调式
- 通过Emacs+GUD去链接(attach)进程
Useful link:
内存模型基础
面向语言的核心 - 核心模型:
- 理解内存时透彻理解编程的基础
- 指针: 就是从一个地方把一个地址带过来
对象, 类型, 变量, 值
- 对象: 对象就是在内存中的一块空间
- 类型: 赋予的这块空间的一个类型
- 变量: 这块空间的名称
- 值: 在这块空间存放的信息/内容
类型的意义:
- 大小不同 (例如int是 4Byte; double是 8byte)
- 在一个强类型语言里, 类型是保证安全性和正确性的基础
基本内置类型:

- 1 Byte = 8 bit
- 有sign的话, sign为第一位, 使得可表示的值少一半
自定义类型:
- 也称复合类型
- string name = ‘Charon’;
- string 是一个复合类型(自定义类型)
- cin, cout 也是
指针
- 指针是一个类型, 其值为另一个变量的地址
- 指针变量声明的一般形式为:
type* pointerVarName- int *ip; // 一个整型的指针
- double *dp; // 一个 double 型的指针
- float *fp; // 一个浮点型的指针
- char *ch; // 一个字符型的指针
- int **mp; // 一个整型指针的指针

- 每一个变量都有一个内存位置,每一个内存位置都定义了可使用连字号(&)运算符访问的地址,它表示了在内存中的一个地址
- 指针大小: 在64位的系统是 8 bytes, 在32位的系统是 4 bytes
内存模型
- 堆
- 栈
- 其他
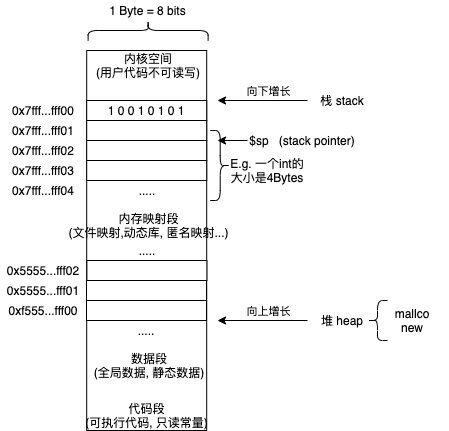
- 所有的变量都储存在栈中 (向下增长)
- stack pointer随着程序的运行不断向下
- 当遇到函数时, 执行函数, stack pointer继续向下;
- 函数执行完毕, stack pointer回到执行函数前的位置
- 然后程序继续运行, stack pointer继续向下 (会覆盖掉刚刚函数的位置)
- 而当new / malloc创建一个新的变量时, 这时的变量是在堆上面的 (向上增长)
- 堆不会自动销毁新开辟的空间, 需要手动delete
- 这就是动态内存
memory alignment:
- 假设内存地址由0开始, 正常运行下面两个变量
- char 的大小是 1 byte
- int 的的大小是 4 byte
- 正常运行的话, int的在内存的地址 减去 由0开始开始的地址应该是 5
- 但实际得到的结果是 8
- 因为在compile的时候, 它会自动将char补齐成4byte (memory alignment)
- 这样内存运行的时候都是以4的倍数去读取, 速度快很多
- 典型的用空间换时间
小结:
- 栈:在函数内部声明的所有变量都将占用栈内存
- 堆:这是程序中未使用的内存,在程序运行时可用于动态分配内存
- 很多时候无法提前预知需要多少内存来存储某个定义变量中的特定信息,所需内存的大小需要在运行时才能确定
- 通过 new 为给定类型的变量在运行时分配堆内的内存,这会返回所分配的空间地址
- 不再需要动态分配的内存空间,可以使用 delete 运算符,删除之前由 new 运算符分配的内存
语言基础
浮点数
- float: 单精度浮点值 (4 Byte)
- double: 双精度浮点值 (8 Byte)
- 目前所有的C/C++编译器都是采用IEEE所制定的标准浮点格式,即二进制科学表示法
- 以float为例:
- 4 byte = 32 bit
- 第一位为符号(Sign), 8位指数(Exponent) (指向小数点的位置), 23为小数(Mantissa)
- 公式:
$(-1)^S \times(1.M) \times 26{E-127}$
float型数据125.5转换为标准浮点格式
- 125二进制表示形式为1111101,小数部分表示为二进制为 1,则125.5二进制表示为1111101.1,由于规定尾数的整数部分恒为1 (由于公式 1.M),则表示为1.1111011*2^6,指数为6,加上127为133,则表示为10000101,而对于尾数将整数部分1去掉,为1111011,在其后面补0使其位数达到23位,则为
1111011000000000000000 则其二进制表示形式为
0 10000101 11110110000000000000000, 则在内存中存放方式为:00000000 低地址 00000000 11111011 01000010 高地址内存地址为 0x42eb0000
而反过来若要根据二进制形式求算浮点数如
0 10000101 11110110000000000000000由于符号为为0,则为正数. 指数为133-127=6,尾数为11110110000000000000000,则其真实尾数为1.1111011. 所以其大小为
1.1111011*2^6,将小数点右移6位,得到1111101.1,而1111101的十进制为125,0.1的十进制为1*2^(-1)=0.5,所以其大小为125.5
- 125二进制表示形式为1111101,小数部分表示为二进制为 1,则125.5二进制表示为1111101.1,由于规定尾数的整数部分恒为1 (由于公式 1.M),则表示为1.1111011*2^6,指数为6,加上127为133,则表示为10000101,而对于尾数将整数部分1去掉,为1111011,在其后面补0使其位数达到23位,则为
double, 双精度浮点值, 1位符号, 11位指数, 52位小数
运算符
- 代表 运算, 存储和 逻辑的基础
- 算术运算符 (运算)
- 指针也可以进行运算, 它本质上是地址, 地址也是个数
- +
- -
- *
- /
- %
- ++
- b = a++
- b 的值 是 a
- a先返回原有的值, 再加1, 再返回
- b = ++a
- b 的值 是 a+1
- a先加1, 再返回
- b = a++
- --
- 关系运算符 (逻辑)
- ==
- !=
- >
- <
- >=
- <=
- 逻辑运算符 (逻辑)
- &&
- ||
- !
- 位运算符 (逻辑, 运算)
- 对二进制操作数进行操作
- &
- |
- ^
- ~
- <<
- >>
- 赋值运算符 (存储)
- =
- +=
- -=
- *=
- /=
- %=
- <<=
- >>=
- &=
- ^=
- |=
- 其他运算符
- sizeof
- 返回变量大小
- Condition ? X : Y
- ,
- 会顺序执行一系列运算 E.g. i=1, i++, i*=10
- 少用
- . 和 ->
- 用于引用类,结构和共用体成员
- &
- 取地址符号
- *
- 指针内容
- sizeof
- 运算符优先顺序
引用 (Reference)
- 引用是一个类型
- 用来定义一个新的变量是一个另一个已存在的变量的别名 (alias)
- 别名的真正含义是他们指向同一个内存地址
一旦把引用初始化为某个变量, 就可以使用该引用名称来操作变量
int i = 42; int &r = i; // 现在 r 的值是 42 int *p = &i // 指针引用 vs 指针
- 引用r是指向与变量i同样的地址
- 指针p是分配新的内存地址, 装着(指向)变量i的地址
- 不同点小结:
- 不存在空指针. 引用必须连接到一块合法的地址
- 一旦引用被初始化为一个对象, 就不能被指向到另一个对象. 指针可以在任何时候指向到另一个对象
- 引用必须在创建时被初始化. 指针可以在任何时间被初始化
作用
- 在同一个地址绑定不同的别名
- 意味着不需要拷贝数据
- 从而达到性能优化
函数
return_type function_name (parameter list){
body of the function
}
- 函数的声明 (declaration)
return_type function_name (parameter list)
- 函数的传入参数与和返回参数
- 默认值一定是从最后开始
头文件
- .cpp文件 源文件
- .h文件 头文件
- C++语言支持’分别编译’ (separate compilation)
- 即比如两个 .cpp可以分别编译 (生成两个.obj文件)
- 如果.cpp 1 需要用到.cpp2的函数
- 在.h头文件写入.cpp2的函数声明, 两个.cpp文件都需要包含该头文件
#include是一个来自C语言的宏命令, 它在编译器进行编译之前, 即在预编译的时候就会起作用#include "..."使用自己定义的库#include <...>使用系统的库- 内容
- 应该只放函数的声明 (不放定义)
- 因为一个头文件的内容实际上是会被引入到多个不同的.cpp文件中, 如果放了定义, 就相当于在多个文件中出现了对一个符号(变量或函数)的定义, 重复编译是编译错误
- 全局变量
- 类
- 以及任何需要在不同源文件之间共享的
- 应该只放函数的声明 (不放定义)
- 用
#pragma once避免头文件重复使用
作用域 和 存储类
存储类(Storage Class):
auto
- C++11才有的 type deduction
根据值去自动推到它是什么类
auto pi = 3.14; // double auto msg('hello'); // cosst char* auto val = new auto(9); // int* 在堆上分配一个内存, 返回一个指针(指向整型的地址) auto x1=5, x2='r'; // 错误, 必须初始化为同一类型
register
- 定义存储在寄存器中而不是内存中的局部变量
register int res;- 但最终存储位置取决于编译器 和 在程序中如何使用该变量
- 高频率读取, 就可以定义为register
- 主要为了性能优化
- register速度 < ns
- cache速度 < 100ns
- memory速度 < ms
- disk速度 ~ s
- network速度 ~ s
- 定义存储在寄存器中而不是内存中的局部变量
static
- 其变量的生命周期不会在它进入和离开作用域时进行创建和销毁 (只被初始化一次, 保持局部变量的存在)
- 在内存中, 它不被保存在堆栈中, 而是保存在一个全局空间, 所以不会随着堆栈的释放/使用进行销毁
- 当static修饰全局变量时, 会使变量的作用域限制在声明它的文件内
extern
- 告诉编译器这个变量在别的地方定义了
- 链接的时候可以找到
作用域和生命周期
- 作用域是程序的一个区域 (一个花括号内)
- 三个地方
- 局部变量: 在函数或一个代码块内部声明的变量
- 形式参数: 在函数参数的定义中声明的变量
- 全局变量: 所有函数外部部声明的变量
- 注意:
- 局部变量的生命周期(lifetime)在作用域内, 随着堆栈的释放/使用进行销毁
- 全局变量的生命周期(lifetime)是execution time
分支和循环逻辑
- if (condition) { … } else { … }
- switch (var) { case condition: … break; … default: … }
- while (condition) { … }
- for (init; condition; increment) { … }
- do { … } while (condition)
控制流逻辑控制 (control flow)
- 循环控制 (作用于最近的循环体)
- break
- continue
- 控制流
- return
- goto
- throw exception or abort
- 不会继续运行
- 前面所有的运行会roll back
- Best practice
- 不要用 goto
- 不要嵌套循环超过3层
内联函数
typedef 关键字
- 一种简化复杂名称类型的手段
- 定义一种类型的别名
- 在C语言中, 声明struct新对象时, 必须带上typedef
用typedef来定义与平台无关的类型
typedef long double myReal;typedef long int *ptrInt64; ptrInt64 x;
内联函数
- inline是一个关键字, 用于程序中定义内联函数
- 内联函数是C++中的一种特殊函数
- 调用时并不通过函数调用的机制, 而是通过将函数体直接插入调用处(编译阶段)
- 这样可以大大减少由函数带来的开销, 从而提升程序运行效率
- 一般用于定义类的成员函数
- 优点:
- 效率高 (没有调用的开销)
- 编译器在调用内联函数时, 会检查它的参数类型, 保证调用正确
- 与类的普通成员函数相同
- 缺点:
- 内联函数的函数体不能太大
- 当函数体过大时, 编译器会自动放弃内联方式
- 内联函数的函数体不能太大
- Best practice
- 小巧的, 高频的, 重要的 使用inline
- 现在的编译器(C++11以上)都自动内联函数
宏
#define是C中的一个宏(marco)定义命令, 用来将一个标识符定义为一个字符串#define <宏名> <字符串>- E.g.
#define PI 3.1415926
- E.g.
- 带参数的宏定义:
#define <宏名>(<参数表>) <宏体>- E.g.
#define A(x) x
- E.g.
宏的实际问题
使用中, 当替换文本所表示的字符串为一个表达式时, 容易引起误解和误用. 例:
// 例1 #define N 2+2 void main(){ int a = N*N; // 就变成了 2+2*2+2 } // 例2 #define area(x) x*x void main(){ int y = area(2+2); // 2+2*2+2 }
宏的常用方法:
防止一个头文件被重复包含, 在.h文件中写入
#ifdef BODYDEF_H #define BODYDEF_H // 头文件内容 #endif现在更好的方法:
- 在.h文件中写入
#pragma once
- 在.h文件中写入
Const
- const是修饰符, 表示不变
- 修饰符 是 一个语义约束, 编译器会强制实施这个约束. 例如const告诉编译器某值是保持不变的
它用来修饰:
- 内置类型变量
- 自定义对象
- 成员函数
- 返回值
函数参数
const int a = 7; int b = a //correct a = 8; // error 不能再赋值 const int& c = b; c = 10; //error
const 和 指针
- 从右向左读
char * const cp; // cp is a const pointer to charconst char * p; // p is a pointer to const charchar const * p; // p is a pointer to char that is const
const 函数参数传递
- const + 值传递 (不要, 没意义)
- 传参本身意义就是把外面的值传到函数内部不要改变
- 值传递到函数后, 还需开辟另外的内存空间来储存, 有没有加const没区别
- const + 指针传递 (可以防止指针被意外串改)
- const + 引用传递 (Best practice, 可以用来代替值传递)
- 指向同一个地址, 所以有必要, 同样防止串改
- const + 值传递 (不要, 没意义)
const 函数返回值
- const + 内置类型的返回值 (不要, 没意义)
const int foo() { ... }
- const + 指针或引用
const string& foo() { ... }- 看情况, 如果返回会被修改就不要, 相反可加
- const + 内置类型的返回值 (不要, 没意义)
动态内存
- new 和 delete 运算符 (在C中是 malloc 和 free)
- 如果heap已被用完, 可能无法成功分配内存
使用时间:
- 在构造函数(函数初始化的时候会被调用)中使用new
在析构函数(结束生命周期的会被调用)中使用delete
double* pvalue = nullptr; //初始化为null的指针 double* pvalue1 = nullptr; pvalue = new double; // 为变量请求内存 pvalue1 = new double[20]; delete pvalue; // 释放pvalue所指向的内存 delete [] pvalue1;
递归和迭代
- 程序调用自身称为递归; 利用变量的原值推出新值称为迭代
- 递归优点:
- 大问题转成小问题(divide&conquer)
- 可以减少代码量, 可读性好
- 递归缺点:
- 调用浪费空间
- 递归太深容易造成堆栈的溢出
- 迭代优点:
- 代码运行效率好
- 时间只因循环次数增加而增加, 而且没有额外的空间开销
- 迭代缺点:
- 代码不如递归简洁
Best practice: 迭代不应超过三层
int fib(int n){ if(n<3) return 1; return fib(n-1)+fib(n-2); } void fib_driver(){ cout << 'test fib 1: ' << fib(1) << endl; cout << 'test fib 5: ' << fib(5) << endl; cout << 'test fib 10: ' << fib(10) << endl; } int main(){ fib_driver(); }
面向对象
类和对象
- 类
- ADT(abstract data type)
- 用户自定义的数据类型 / 操作
- 对象
- 是类生成的实体 (实体化)
- 数据成员
- 类型 + 变量
- 访问
- 通过外部调用
C里自定义类型: struct
- 没有封装
- 没有操作
仅是类型结构体
struct Vector{ int sz; // number of element double* elem; // pointer to element } void vector_init(Vector& v, int s){ v.elem = new double[s]; v.sz = s; } double read_and sum(int s){ Vector v; vector_init(v,s); for (int i=0; i!=s; ++i){ cin >> v.elem[i]; } double sum = 0; for (int i=0; i!=s; ++i){ sum += v.elem[i]; } return sum; } void f(Vector v, Vector& rv, Vector* pv){ int i1 = v.sz; // pass by value int i2 = rv.sz; // pass by reference int i3 = pv->sz; // pointer ->是指针操作符 }
C++:
class Vector{
private:
size_t sz; // number of element
double* elem; // pointer to element
public:
Vector(size_t s){ // 构造函数
: sz {size}, // C++ {} ()都可
elem(new double[s])
{
}
Vector(size_t s, double *element){ // 构造函数
: sz {size},
elem(element)
{
}
double& operator[](int i){
return elem[i]
}
size_t size() {
return sz;
}
~Vector(){ // 析构函数
delete [] elem;
}
};
double read_and sum(int s){
Vector myVector = v(s); // 初始化
for (int i=0; i!=s; ++i){
cin >> v[i]; // 相当于调用了Vector类中的操作符函数
}
double sum = 0;
for (int i=0; i!=s; ++i){
sum += v[i];
}
return sum;
}
void f(Vector v, Vector& rv, Vector* pv){
size_t i1 = v.size(); // pass by value
size_t i2 = rv.size(); // pass by reference
size_t i3 = pv->size(); // pointer ->是指针操作符
}
// Explict & Implicit
Vector v1 = 7; // OK: v1 has 7 elements
class Vector{
public:
explicit Vector(int s); // no implicit from int to vector
// ...
}
Vector v1(7); // OK: v1 has 7 elements
Vector v2 = 7 // error: no implecit conversion from int to vector
变量做私有处理(private), 接口做公有处理(public)
类
- 成员
- 构造函数 (explicit)
- 可以有多个
- 显式, 加explicit标识符, 编译器就不会自动做隐式的转换 (看👆例子)
- 析构函数
- 初始化列表来初始化字段
分别编译
- 又称分离式编译
一个项目由若干个源文件共同实现,而每个源文件(.cpp)单独编译成目标文件(.obj),最后将所有目标文件连接起来形成单一的可执行文件(.exe)的过程
---------------test.h------------------- void f();//这里声明一个函数f ---------------test.cpp-------------- #include"test.h" void f(){ …//do something } //这里实现出test.h中声明的f函数 ---------------main.cpp-------------- #include"test.h" int main(){ f(); //调用f,f具有外部连接类型 }
上面程序在编译器内部的过程为:
- 在编译mian.cpp的时候,编译器并不知道f的实现,所以当碰到对f的调用时只是给出一个指示,指示连接器为它寻找f的实现体,所以main.obj中没有关于f实现的二进制代码
- 在编译test.cpp的时候,编译器找到了f的实现,所以在test.obj里有f实现的二进制代码
- 连接时,连接器在test.obj中找到f实现的二进制地址,然后将main.obj中未解决的f地址替换成该二进制地址
修饰符
- public
- private
- 外部不可见, 看不见就改不了, 安全性提高
- protected
- 子类可见
初始化类
- 加入initializer_list类型来实现构造函数,在新建对象时,就可以使用列表初始化的方式
- 在实例化的时候
构造函数的声明可以一部分放头文件里, 也可以一部分放源文件里
Vector v1(7); Vector v2 {1,2,3,4,5}; // 通过initializer_list来实现这个, 在初始化的时候就决定内容 class Vector{ private: size_t sz; // number of element double* elem; // pointer to element public: Vector(initializer_list<double> lst); // 这里只做声明, 实体在下面; 当然也可以全部写在一起 //Vector(initializer_list<double> lst) // : elem(new double[lst.size()]), // sz(lst.size()) //{ // std::copy(lst.begin(), lst.end(),elem) // 将lst 拷贝到 elem //} Vector(size_t s){ // 构造函数 : sz {size}, // C++ {} ()都可 elem(new double[s]) { } Vector(size_t s, double *element){ // 构造函数 : sz {size}, elem(element) { } double& operator[](int i){ return elem[i] } size_t size() { return sz; } ~Vector(){ // 析构函数 delete [] elem; } }; Vector::Vector(initializer_list<double> lst) : elem(new double[lst.size()]), sz(lst.size()) { std::copy(lst.begin(), lst.end(),elem) // 将lst 拷贝到 elem }
拷贝构造函数
进阶
多态和继承
- 多态 (polymorphism)
- 多态就是为了更好的帮助建模 (编程就是对给定范围的问题, 在抽象层面上的建模)
- 接口的多种不同的实现方式即为多态 (指同一个实体同时具有多种形式)
- 多态就是允许方法重名 参数或返回值可以是父类型传入或返回
- C++中,实现多态有以下方法:虚函数(核心),抽象类,覆盖,模板(重载和多态无关)
- 基类 (base class)
- 派生类 (derived class)
- 派生类拥有一些基类的属性(member var/func)
- 派生类的接口
- 接口窄化
- private继承 (原本基类的接口是public, private继承后该接口变私有)
- protected继承
- 接口窄化
- 多态就是为了更好的帮助建模 (编程就是对给定范围的问题, 在抽象层面上的建模)
- 继承 (inheritance)
- 接口 (interface)
抽象 (abstract)
#include <iostream> using namespace std; class Base{ public: void foo(){ cout << "base foon"; } }; //class Derived : public Base { // 继承 class Derived : private Base { public: void bar(){ foo(); } } int main(){ Derived d1; // d1.foo(); // 改成private继承后, 直接调用会报错 d1.bar(); return 0; }
模块化 ==> 高内聚 (一个类的内部, 是高度内聚的, 仅在内部使用), 低耦合 (跟外部的依赖性低)
多继承和虚函数
一个类可以从多个地方继承, 但可能会导致
- 钻石问题(diamond problem)
- class D{ … }
- class B : public D{ … }
- class A : public D{ … }
- class C : public B{ … },public A{ … }
- 问题: class C 继承了两次 class D
- 解决: virtual继承
- class D{ … }
- class B : virtual public D{ … }
- class A : virtual public D{ … }
- class C : public B{ … },public A{ … }
- 虚函数 (virtual function):
- 多态的核心结构 (多态是在runtime的时候才能确定它的表现 (在编译的时候无法确定), 通过继承来体现出来)
- 编译时期的绑定, 早绑定 (静态绑定)
- 运行时期的绑定, 晚绑定 (动态绑定)
- 虚函数就是告诉编译器, 基类的函数有可能被子类重新定义 -> 动态绑定
code:
#include <iostream>
using namespace std;
class Base{
public:
void foo(){
cout << "base foo\n";
}
};
//class Derived : public Base { // 继承
class Derived : private Base {
public:
void foo(){
cout << "derived foo\n";
}
}
int main(){
Derived d1;
Base* b1 = &d1; // 对派生类的类型进行强制转换成基类, 指针指着的是派生类的地址, 但是call b1.foo() 打印 base foo 而不是 derived foo
// 原因: base的foo 和 derived的foo 都在 derived的内存空间里, 因为函数在编译的时候就绑定(静态/早绑定)了, 所以call base的foo就rerurn其结果
b1.foo(); // base foo
// d1.foo(); // derived foo
return 0;
}
解决办法: 在基类和派生类的函数前面加virtual, 其意义就是告诉编译器, 基类的函数有可能被子类重新定义 -> 动态绑定
在derived的内存里就是 装着一个vtable的指针, 指向另一块名为vtable的内存空间, 装着foo函数调用指针
简单理解就是: 加了virtual关键字, 调用的时候先调用派生类, 再调用基类; 不加的话, 同样是先进入派生类, 什么都不做, 再到基类, 调用了基类 再调用派生类
构造函数 和 析构函数 同理
例子:
// ========== myVectort.hpp ==========
#pragma once
class Container{
public:
virtual double& operator[](int i);
virtual int size();
virtual ~Container(){}
};
class Vector_container : public Container{
public:
Vector_container(initilizer_list<double> vec)
: v(vec){}
~Vector_container() {}
virtual double& operator[](int i){
return v[i];
};
virtual int size(){
return v.size();
};
private:
Vector v;
};
#include<list>
class List_container : public Container{
public:
List_container(initilizer_list<double> list
: lst(list){}
~List_container() {}
virtual double& operator[](int i){
// return lst[i];
// 新语法 range based for loop / iterator
for (auto& x : lst){
if (i==0) return x;
--i;
}
// ?
throw out_of_range("list container")
};
virtual int size(){
return lst.size();
};
private:
std::list<double> lst;
};
void display(Contaienr& c){ // 调用display的时候它不在乎是哪个Container的派生类; display 对 c 的实现毫不知情, 仅对c的接口进行操作
const int sz = c.size();
for (int i =0; i < size; ++i){
cout << c[i]<< endl;
}
}
void g(){
Vector_container vc {10,9,8,0};
display(vc);
}
void h(){
List_container vc {1,2,4,0};
display(vc);
}
继承 -> 隐藏设计细节 <- 接口实现分开 <- 简化调用方的流程
纯虚函数 和 纯接口类
纯虚函数就是在虚函数后面加一个 = 0 的符号 ==> pure virtual
- 一个类中有一个纯虚函数, 该类就变成纯虚类(又称纯接口类)
- 特点:
- 不可以被实例化
- 但可以有成员变量
- 好处就是作为纯接口, 不用担心误实例化它
- 这是在C++的做法, 但是例如在java中直接引用关键字 interface
- 特点:
code:
class Box{
public:
vitual double getVolume() = 0;
private:
double width;
double length;
}
纯接口类
- 纯接口类一般用作抽象的基类, 提供一个适当/同用/标准化的接口
- 派生类通过继承抽象基类, 就把所有类似的操作继承下来了
- 外部可见(公有)函数在抽象基类中是以纯虚函数的形式存在
- 这些纯虚函数在相应的派生类中必须被实现
- 重要意义: 解耦合
C++数据抽象
- 只向外界提供关键信息, 并隐藏其后台的实现细节
- 数据抽象是一种依赖于借口和实现分离的编程/设计思想
- 例如cout, 公共接口不变, 底层实现可以自由改变
设计策略: 抽象把代码分离为接口和实现. 所以在设计组件时, 必须保持接口独立于实现, 这样即使改变底层, 接口也将保持不变. 任何程序使用接口, 接口都不受影响, 只需重新编译即可. (Flexibility)
数据封装:
- 两要素:
- 程序语句(代码) - 执行部分 - 函数
- 程序数据 - 程序信息, 受函数影响
- 封装是OOP中把数据和操作数据的函数绑定在一起的概念, 避免受到外界干扰/误用, 确保安全
- 数据隐藏
- 封装是把数据和操作数据的函数捆绑在一起的机制
- 数据抽象是仅向用户暴露数据接口, 而把具体细节隐藏起来的机制
- public, private, protected
继承的好处
- 接口继承 (Interface Inheritance) - 通过纯虚函数 - 实现解耦合
- 实现继承 (Implementation Inheritance) - 通过继承基类函数, 不用重新定义
- 具体的类实例化, 通常通过对于接口(基类)的指针来实现
- 低耦合
Casting
在runtime需要知道具体是什么类型的时候, 需要用到casting (强制类型转换)
- const_cast
(expr): 用于修改类型的const属性 - dynamic_cast
(expr): dynamic_cast在运行时执行转换, 验证转换的有效性. - static_cast
- reinteperor_cast
避免内存泄漏
new 的 pointer没有及时释放, 会造成内存的泄漏. 通过unique_ptr来做指针的保护
命名空间
- 命名空间就是定义了一个范围
- 类本身就是一个特殊的命名空间
- 嵌套的命名空间 和 匿名命名空间
Best practice: 不要放在头文件
namespace My_code{ class complex{ // ... }; } // ======== int My_code::main(){ complex x {1,2}; } // ======== int main(){ return My_code::main(); }
类的不可改性 Immutability
- const 成员函数
void foo() cosnt{}// read only func - const 成员变量
const A a; a.foo()// foo也必须是const - class 为 final
class A final {} - 完全不可改 和 部分不可改
模板和泛型编程
- 把编译时间的事情放到runtime时候做: 动态绑定 (late binding)
- 多态, flexibility
- 把runtime的事情放在编译时候做: 模板元编程
- …
模板
- 泛型编程的基础, 泛型编程(Generic programming)以一种独立于任何特定类型的编程
- 创建泛型类或函数的蓝图或公式. 库容器, 比如迭代器和算法, 都是泛型编程
- 每个容器都有一个单一的定义, 比如 向量, 可以定义许多不同类型的向量, 如 vector
或 vector - 可以使用模板来定义函数和类
函数模板:
template <class type>
ret-type func-name(parameter list){
// ...
}
// 具体例子:
template <typename T> // T代表type
inline T const& Max(T const& a, T const& b){
return a < b ? b:a;
}
int main(){
int i = 9;
int j = 10;
double i1 = 9.1;
double j1 = 10.1;
cout << Max(i,j) << endl;
cout << Max(i1,j1) << endl;
}
类模板
template <class type>
class class-name{
...
}
// ========
template <class T1, class T2>
class A{
T1 data1;
T2 data2;
}
// ==== 简易版vector模板 ====
template <typename T>
class Vector{
private:
size_t sz;
T* elem;
public:
explicit Vector(size_t size);
T& operator[](int i);
size_t size(){
return elem(new T[s]);
}
Vector(const Vector& other);
~Vector() {delete[] elem;}
};
template <typename T>
Vector<T>::Vector(size_t size)
: sz {size},
elem(new T[s])
{
}
template <typename T>
Vector<T>::Vector(const Vector& other)
: sz(size()),
elem(new T[sz]){
for (int i=0; i != sz; i++){
elem[i] = other.elem[i];
}
}
template <typename T>
const T& Vector<T>::operator[](int i) const{
if (i < 0 || i>= size())
throw out_of_range("")
return elem[i];
}
// 使用Vector
Vector<std::string> strVec;
Vector<int> intVec;
全特化 和 偏特化
条件分支
元编程
模板高级特性
STL和数据结构
STL(Standard Template Library) 标准模板库, 提供通用的模板类和函数, 实现多种常用的算法和数据结构
STL核心三组件组件:
- 容器(Containers): 用来管理某一类对象的集合 如 deque, list, vector, map等
- 算法(Algorithms): 用于容器, 执行各种操作的方式, 如 初始化, 排序, 搜索, 转换等
- 迭代器(iterators): 英语遍历对象集合的元素
容器(Containers)
- 顺序容器
- Vector, deque, list
- Vector: random access
- List: doubly linked list
- Vector, deque, list
- 关联容器
- Set, multiset, map, multimap
- 基于hash table的容器
- unordered_map, unordered_set
- 其他
- Stack(LIFO), queue(FIFO), Priority_Queue
容器和多态:
- vector
vs; // 前面是基类, 后面不能放派生类了 - vector
- vector
vector
- std::vector
- 分配内存:
- doubling: 双倍增长分配内存, 8, 16, 32 ….
reserve(size()==0?8:2*size()); - Elem
- Space
- Last
- doubling: 双倍增长分配内存, 8, 16, 32 ….
example:
// general usage
vector<Entry> phone_book = {
{'David':123},
{'Karl': 321},
{'lala': 543}
}
// solid example
#include <vector>
#include <iostream>
using std::vector;
int main(){
vect<int> vecInt;
vecInt.push_back(42);
vecInt.push_back(100);
vecInt.push_back(12);
cout << vecInt.size() << std::endl;
cout << vecInt.capacity() << std::endl;
for (auto& i : vecInt){
cout << i << endl;
}
// vector<int>::iterator iter = vecInt.begin();
vector<int>::const_iterator iter = vecInt.cbegin();
while (iter != vecInt.end()){
cout << 'value of vecInc: ' << *iter << endl;
}
return 0;
}
list
list & vector 使用一样
#include <iostream>
#include <list>
#include <string>
#include <algorithm>
using namespace std;
int main(){
list<int> intList {1,2,3,4,5};
list<int>::iterator p = intList.begin();
cout << "1st p: " << *p << endl;
advance(p,2);
cout << "2nd p: " << *p << endl;
advance(p,2);
cout << "2nd p: " << *p << endl;
auto q = intList.end();
q--;
cout << "1st q: " << *q << endl;
cout << distance(p,q)<<endl;
iter_swap(p,q);
for (auto& e: intList){
cout << e << " ";
}
}
map
- std::map
- RB-tree (红黑树 平衡的binary tree)
- std::unorder_map
- hash table
- std::set
- not key, just value
- std::unorder_set
- hash table
sample:
map<string, int> phone_book = {
{'David':123},
{'Karl': 321},
{'lala': 543}
}
unordered_map<string, int> phone_book = {
{'David':123},
{'Karl': 321},
{'lala': 543}
}
int get_number(const string& s){
return phone_book[s];
}
// ==========
#include <iostream>
#include <vector>
#include <list>
#include <map>
#include <string>
#include <algorithm>
using namespace std;
int main(){
map<string, int> mapOfWords;
mapOfWords.insert(std::make_pair("earth",1));
mapOfWords.insert(std::make_pair("ocean",2));
mapOfWords["sun"] = 3;
// auto it = mapOfWords.cbegin();
for (auto& elem: mapOfWords){
cout << "key: " << elem.first << "; value: " << elem.second << endl;
}
if(mapOfWords.find("sun") != mapOfWords.end()) {
cout << "sun found" << endl;
}
return 0;
}
算法
- unique_copy
- back_inserter
- -–
- find
- -–
- transform
- for_each
code:
#include <iostream>
#include <vector>
#include <list>
#include <map>
#include <string>
#include <algorithm>
using namespace std;
int main(){
vector<string> quote {"This","is", "C++"};
vector<string> res;
transform(begin(quote),end(quote),back_inserter(res),
[](const string& word){
return "<"+word+">";
});
for_each(begin(res),end(res),
[](const string& word){
cout << word << " ";
});
return 0;
}
补充和回顾
IOS (输入输出流)
头文件
- 输出流 ofstream: 创建文件并写入信息
- 输入流 ifstream: 从文件读取信息
- 文件流 fstream: 同时具有输入输出
example:
#include <iostream>
#include <fstream>
using namespace std;
int main(){
ofstream outfile;
outfile.open("myfile.data");
cout << "enter some data\n";
char data[100];
cin.getline(data,100);
outfile << data << endl;
outfile.close();
ifstream infile;
inflie.open("myfile.data");
inflie >> data;
// .. more code about data
inflie.close();
return 0;
}
异常
- 在运行期间转移程序控制权的方式
- 三个关键字:
- throw
- try
- catch
- 抛出异常 throw
- 捕获异常 try catch
- try中的代码可能抛出异常 throw
- try后面通常跟着一个或多个catch
example:
#include <iostream>
#include <exception>
#include <string>
using namespace std;
class MyException : public exception{
public:
string msg() const{
return "my exception";
}
}
class A{
public:
A() { cout << "A constructor called" << endl;}
~A() { cout << "A destructor called" << endl;}
}
int main(){
double division(int a, int b){
if (b==0) throw "Division by zero condition";
return (a/b);
}
try{
A a; // 会先清空A内存在抛出异常
int z = division(2,0);
cout << z << endl;
throw MyException();
} catch (const char* msg){
cerr << msg << endl;
}
} catch(MyException& e){
std::cout << "MyException caught\n";
std::cout << e.msg();
}
}
C++标准异常:
- exception
- bad_alloc
- bad_cast
- bad_exception
- bad_typeid
- -–
- logic_error
- domain_error
- invalid_argument
- length_error
- out_of_range
- -–
- runtime_error
- overflow_error
- range_error
- underflow_error
使用异常情况:
- 在当前情况下无法解决错误
- 避免undefined behavior
- 滥用异常会导致性能损耗
资源管理: 智能指针
模板类, 帮忙管理内存 - 有使用的时候抓住指针, 没有使用自己释放
- unique_ptr
- shared_ptr
- weak_ptr
example:
#include <memory>
#include <iostream>
using namespace std;
class ResourceType{
public void foo() { cout << "foo called\n"; }
}
int main(){
//Resourcetype* nakedPtr = new ResourceType; //不安全
unique_ptr<ResourceType> r1 {std::make_unique<RecesourceType>()};
auto r2 {std::make)unique<RecesourceType>()};
unique_ptr<ResourceType> r3 = r2;
r1 -> foo();
return 0;
}