Time Complexity and Space Complexity
在实现算法的时候通常会从两方面考虑算法的复杂度, 即时间复杂度和空间复杂度. 顾名思义, 时间复杂度用于度量算法的计算工作量;空间复杂度用于度量算法占用的内存空间.
渐进时间复杂度
理论上来说, 时间复杂度是算法运算所消耗的时间, 但是对于一个算法来说, 评估运行时间是很难的, 因为针对不同大小的输入数据, 算法处理所要消耗的时间是不同的, 因此通常关注的是时间频度, 即算法运行计算操作的次数, 记为T(n), 其中n称为问题的规模.
同样, 因为n是一个变量, n发生变化时, 时间频度T(n)也在发生变化, 所以称时间复杂度的极限情形称为算法的“渐近时间复杂度”, 记为O(n). 因为没办法用通常的评估方式来评估所有算法的时间复杂度, 因此使用渐进时间复杂度表示算法的时间复杂度, 下文中的时间复杂度均表示渐进时间复杂度.
python算法例子的解释:
def f(n):
a,b=0,0 #运行消耗t0时间
for i in range(n): #运行一次平均消耗t1时间
a = a + rand() #运行一次平均消耗t2时间
for j in range(n): #运行一次平均消耗t3时间
b = b + rand() #运行一次平均消耗t4时间上面例子中, 分别计算f(n)函数的时间复杂度与空间复杂度.
- 根据代码上执行的平均时间假设, 计算出来执行f(n)的时间为
- T(n)=t0+(t1+t2)*n+(t3+t4)*n
- T(n)=t0+(t1+t2+t3+t4)*n
- 而函数中申请了两个变量a,b, 占用内存空间为2.
上述T(n)是对函数f(n)进行的准确时间复杂度的计算. 但实际情况中, 输入规模n是影响算法执行时间的因素之一. 在n固定的情况下, 不同的输入序列也会影响其执行时间. 当n值非常大的时候, T(n)函数中常数项t0以及n的系数(t1+t2+t3+t4)对n的影响也可以忽略不计了, 因此这里函数f(n)的时间复杂度可以表示为O(n).
空间复杂度, 跟时间复杂度表示类似, 也可以用极限的方式来表示空间复杂度, 因为这里只声明了2个变量, 因此空间复杂度也是常数阶的, 因此这里空间复杂度计算为O(1).
时间复杂度的计算方法
因为计算的是极限状态下的时间复杂度, 因此存在两种特性:
- 按照函数数量级角度来说, 相对增长低的项对相对增长高的项产生的影响很小, 可忽略不计.
- 最高项系数对最高项的影响也很小, 因此也可以忽略不计. 针对第1点, 常见的时间复杂度有:
- 常数阶:
$O(1)$ - 对数阶:
$O(log_2 n)$ - 线性阶:
$O(n)$ - k次方阶:
$O(n^k)$ - 指数阶:
$O(2^n)$
- 常数阶:
根据上述两种特性, 总结时间复杂度的计算方法:
- 只取相对增长最高的项, 去掉低阶项;
- 去掉最高项的系数;
- 针对常数阶, 取时间复杂度为O(1).
时间复杂度例子
一. 对于一个循环,假设循环体的时间复杂度为 O(n),循环次数为 m,则这个 循环的时间复杂度为 O(n×m).
void aFunc(int n) {
for(int i = 0; i < n; i++) { // 循环次数为 n
print("Hello, World!\n"); // 循环体时间复杂度为 O(1)
}
}此时时间复杂度为 O(n × 1),即 O(n).
二. 对于多个循环,假设循环体的时间复杂度为 O(n),各个循环的循环次数分别是a, b, c…,则这个循环的时间复杂度为 O(n×a×b×c…). 分析的时候应该由里向外分析这些循环.
void aFunc(int n) {
for(int i = 0; i < n; i++) { // 循环次数为 n
for(int j = 0; j < n; j++) { // 循环次数为 n
printf("Hello, World!\n"); // 循环体时间复杂度为 O(1)
}
}
}此时时间复杂度为 O(n × n × 1),即 O(n^2).
三. 对于顺序执行的语句或者算法,总的时间复杂度等于其中最大的时间复杂度.
void aFunc(int n) {
// 第一部分时间复杂度为 O(n^2)
for(int i = 0; i < n; i++) {
for(int j = 0; j < n; j++) {
printf("Hello, World!\n");
}
}
// 第二部分时间复杂度为 O(n)
for(int j = 0; j < n; j++) {
printf("Hello, World!\n");
}
}此时时间复杂度为 max(O(n^2), O(n)),即 O(n^2).
四. 对于条件判断语句,总的时间复杂度等于其中 时间复杂度最大的路径 的时间复杂度.
void aFunc(int n) {
if (n >= 0) {
// 第一条路径时间复杂度为 O(n^2)
for(int i = 0; i < n; i++) {
for(int j = 0; j < n; j++) {
printf("输入数据大于等于零\n");
}
}
} else {
// 第二条路径时间复杂度为 O(n)
for(int j = 0; j < n; j++) {
printf("输入数据小于零\n");
}
}
}此时时间复杂度为 max(O(n^2), O(n)),即 O(n^2).
时间复杂度分析的基本策略是:从内向外分析,从最深层开始分析. 如果遇到函数调用,要深入函数进行分析.
五.
void aFunc(int n) {
for (int i = 0; i < n; i++) {
for (int j = i; j < n; j++) {
printf("Hello World\n");
}
}
}当 i = 0 时,内循环执行 n 次运算,当 i = 1 时,内循环执行 n - 1 次运算……当 i = n - 1 时,内循环执行 1 次运算. 所以,执行次数
- T(n) = n + (n - 1) + (n - 2)……+ 1
- = n(n + 1) / 2
- = n^2 / 2 + n / 2.
根据上文说的 大O推导法 可以知道,此时时间复杂度为 O(n^2).
六.
void aFunc(int n) {
for (int i = 2; i < n; i++) {
i *= 2;
printf("%i\n", i);
}
}假设循环次数为 t,则循环条件满足 2^t < n.
可以得出,执行次数$t = log_2 (n)$,即 $T(n) = log_2(n)$,可见时间复杂度为 $O(log_2 (n))$,即 $O(log n)$.
七.
long aFunc(int n) {
if (n <= 1) {
return 1;
} else {
return aFunc(n - 1) + aFunc(n - 2);
}
}显然运行次数,T(0) = T(1) = 1,同时 T(n) = T(n - 1) + T(n - 2) + 1,这里的 1 是其中的加法算一次执行.
显然 T(n) = T(n - 1) + T(n - 2) 是一个斐波那契数列,通过归纳证明法可以证明,当 n >= 1 时 $T(n) < (5/3)^n$,同时当 n > 4 时 $T(n) >= (3/2)^n$.
所以该方法的时间复杂度可以表示为 $O((5/3)^n)$,简化后为 $O(2^n)$.
空间复杂度
空间复杂度指的是算法在内存上临时占用的空间, 包括程序代码所占用的空间, 输入数据占用的空间和变量占用的空间. 在递归运算时, 由于递归计算是需要使用堆栈的, 所以需要考虑堆栈操作占用的内存空间大小. 空间复杂度的计算也遵循渐进原则, 即参考时间复杂度与空间复杂度计算方法项.
空间复杂度的计算方法:
- 通常只考虑参数表中为形参分配的存储空间和为函数体中定义的局部变量分配的存储空间, 比如:
- 变量a=0在算法中空间复杂度为O(1)
- list_a=[0,1,… . ,n]的空间复杂度为O(n)
- set(list_a)的空间复杂度为O(1)
- 递归函数情况下, 空间复杂度等于一次递归调用分配的临时存储空间的大小乘被调用的次数.
以递归方法实现的斐波那契数列为例:
def fib(n):
if n < 3:
return 1
else:
return fib(n-2)+fib(n-1)斐波那契数列的序列依次为1,1,2,3,5,8,13… . . 特点是, 当数列的长度大于等于3时, 数列中任意位置的元素值等于该元素前两位元素之和.
计算时间复杂度:
$O(2^n)$. 计算方法:通过归纳证明的方法, 尝试计算数列中第8个元素的值的递归调用次数:- fib(8)= fib(7)+fib(6)
- = {fib(6)+fib(5)}+{fib(5)+fib(4)}
- = ({fib(5)+fib(4)}+{fib(4)+fib(3)})+({fib(4)+fib(3)}+{fib(3)+fib(2)})
- = … . .
- 每次调用递归时, 递归调用次数都是以程序中调用递归次数即2的指数形式增长的. 第一层递归时, 调用了2次fib(n)函数;第二层递归时, 第一层的2次递归调用分别又要调用2次, 即调用了
$2^2$次;第三层递归调用了$2^3$次, 以此规律, 不难算出时间复杂度为$O(2^n)$
计算空间复杂度:
$O(n)$. 计算方法:同样使用归纳证明的方法, 尝试推导数列中第6个元素值的内存占用情况.- 调用函数fib(6),此时因为有形参n传递, 在栈中为n申请内存资源, 为了方便, 以fib(6)表示栈中元素. 此时栈中有fib(6);
- 根据函数内的递归调用关系, 为了计算fib(6), 需要fib(5)和fib(4)的值, 此时发生形参传递, 栈中有fib(6),fib(5),fib(4);
- 为了计算fib(4), 需要fib(3)和fib(2)的值, 此时栈中有fib(6),fib(5),fib(4),fib(3),fib(2), 但是由于fib(2)=1, 此时fib(2)函数计算完成, fib(2)出栈, 此时栈中有fib(6),fib(5),fib(4),fib(3).
- 为了计算fib(3), 需要fib(2)和fib(1)的值, 此时栈中有fib(6),fib(5),fib(4),fib(3),fib(2),fib(1). 但是fib(2)=1,fib(1)=1,计算完成, fib(2)和fib(1)出栈. 此时得到fib(3)的值为2, fib(3)出栈;
- 由此出栈顺序, fib(4),fib(5),fib(6)也会随计算完成出栈. 不难发现, 在此次递归计算的过程中, 内存中最多消耗了6个内存资源, 由归纳证明法得出fib(n)的空间复杂度为O(n).
Master Theorem(主方法)
Merge Sort:
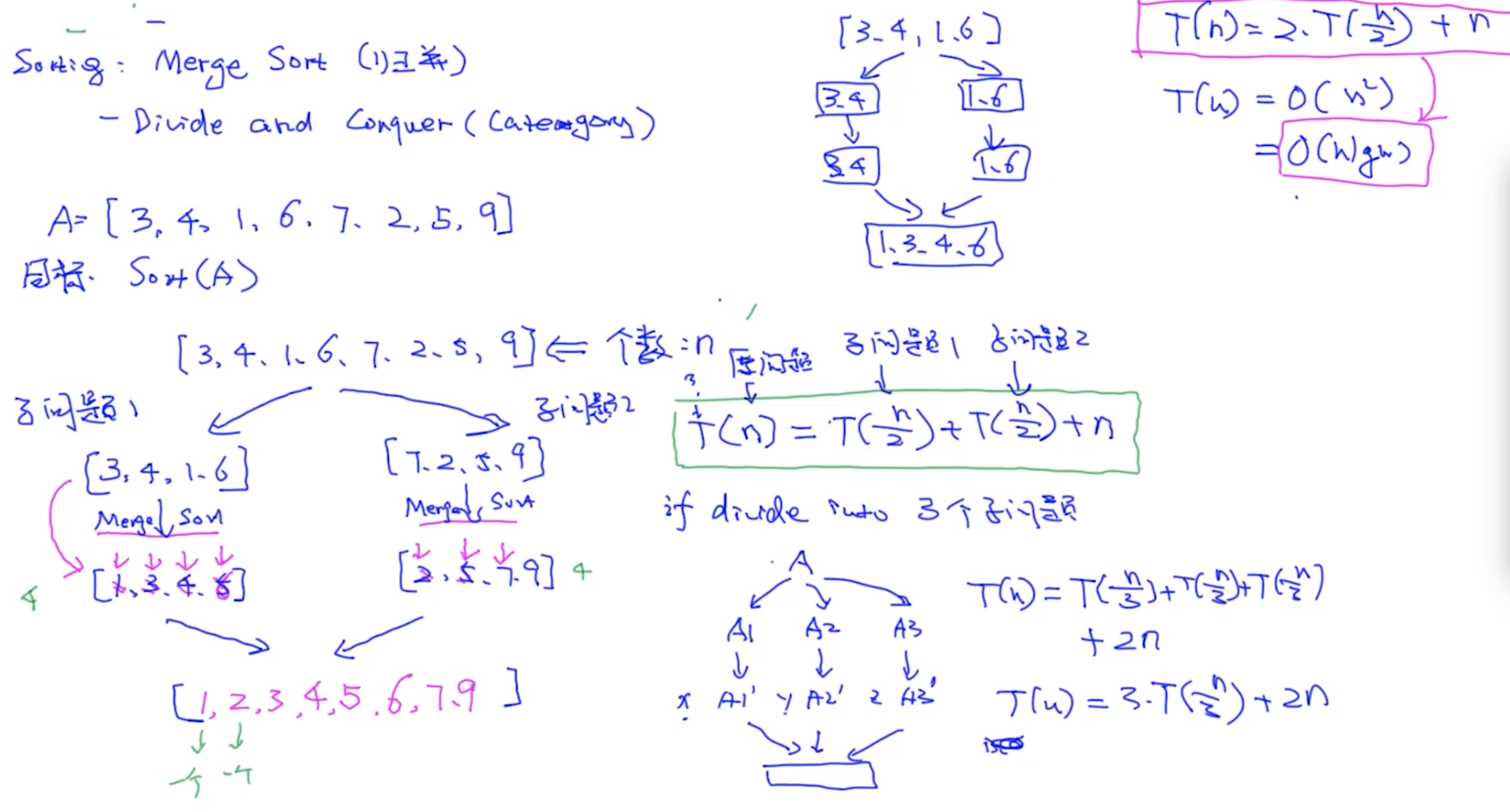 T(n)是一个未知/自定义函数, 表示算法需要执行的运算次数
T(n)是一个未知/自定义函数, 表示算法需要执行的运算次数
- 分成2份的话, T(n) = 2*T(n/2) + n
- 分成3份的话, 合并的时候要做两次 T(n) = 3*T(n/3) + 2n
问题: 如何将 T(n) = 2*T(n/2) + n (递归写法的复杂度) 转换成 O(nlogn) !!!?
- 通过主定理 (master therom)
Master Theorem是为了计算含有递归调用的算法的时间复杂度的. 因为算法中如果含有递归调用算法的情况下使用归纳证明的方法计算时间复杂度是相当困难的, 因此需要利用Master Theorem来帮助计算复杂情况下的算法的时间复杂度, Master Theorem定理如下:

Master Theorem的一般形式是$T(n) = a T(n / b) + f(n),$ $a >= 1, b > 1$. 递归项f(n)理解为一个高度为$log_b n$ 的a叉树, 这样总时间频次为 $(a ^ {log_b n}) - 1$, 右边的f(n)假设为 $nc$, 那么对比一下这两项就会发现 T(n)的复杂度主要取决于 $log_b a$ 与 $f(n)$ 的大小. ($log_b a$表示以b为底, a的对数)因此下面总结了使用Master Theorem的三种case的简单判断:
计算$log_b a$的值, 比较$n^(log_b a)$与$f(n)$的大小:
若
$n^{(log_b a)}>f(n)$,时间复杂度为$O(n^(log_b a))$(case 1)若
$n^{(log_b a)}<f(n)$,时间复杂度为$O(f(n))$(case 3)若
$n^{(log_b a)}=f(n)$,时间复杂度为$O(n^{(log_b a)}*(log n)^{k+1})$(case 2)- 其中k值为f(n)中如果有log对数项时, 该对数项的指数为k, 例如, 如果f(n)=log n , k=1;f(n)=n,k=0
例子:

常规套路呢, 就是比较$n^{(log_b a)}$与$f(n)$的值, 比较出来就可以套用上述公式, 但是一定要注意公式中的限制条件, 如a必须为常数项等.
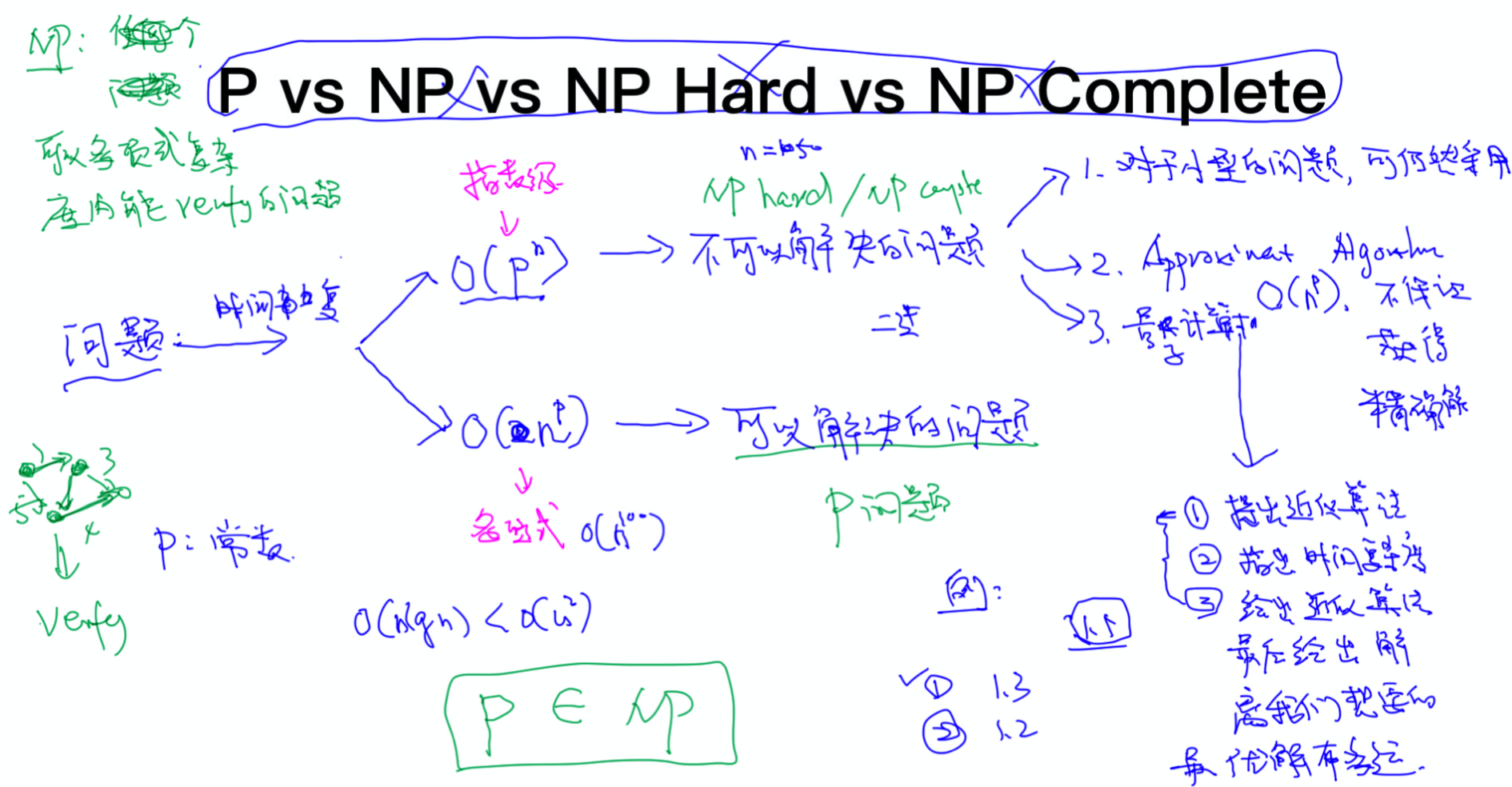
P,NP, NP hard, NP complete