8. ML Strategy(2)
进行误差分析(Carrying out error analysis)

假设正在调试猫分类器,然后取得了90%准确率,相当于10%错误. 看了一下算法分类出错的例子,注意到算法将一些狗分类为猫. 是否要花时间去针对狗的图片优化算法? – 通过错误分析来判断
错误分析:
- 100个错误标记的开发集样本, 手动检查开发集里有多少错误标记的样本是狗
- 如果100个中只有5%是狗, 那最多只能希望错误率从10%下降到9.5%
- 但如果50%都是狗的照片, 错误率可能就从10%下降到5%, 就可以集中精力减少错误标记的狗图的问题
Ideas for cat detection:
- Fix pictures of dogs being recognized as cats
- Fix great cats (lions, panthers, etc..) being misrecognized
- Improve performance on blurry images Make a table like this:
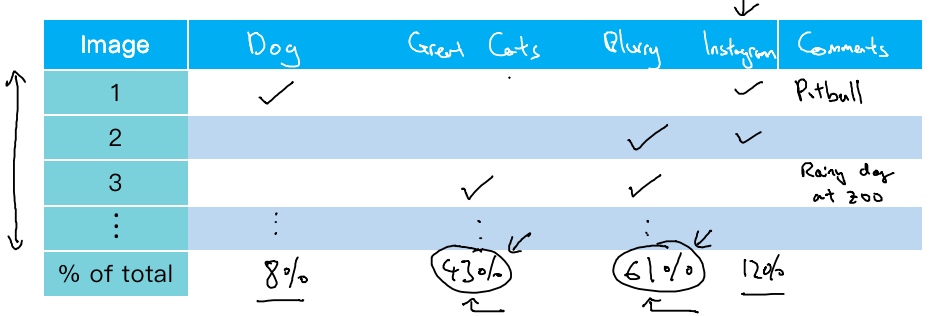
一行对应一个错误标记样本, 一列就对应要评估的想法. 最后统计每个错误类型的百分比.
Conclusion:
错误分析就是通过统计不同错误标记类型占总数的百分比,可以帮你发现哪些问题需要优先解决,或者给你构思新优化方向的灵感
清除标注错误的数据(Cleaning up Incorrectly labeled data)

The circled picture is wrongly classified.
BUT DL algorithms are quite robust to random errors in the training set. (Not the case if it is systematic error(如果做标记的人一直把白色的狗标记成猫,那就成问题了))
如果这些标记错误严重影响了你在开发集上评估算法的能力,那么就应该去花时间修正错误的标签。但是,如果它们没有严重影响到你用开发集评估成本偏差的能力,那么可能就不应该花宝贵的时间去处理.
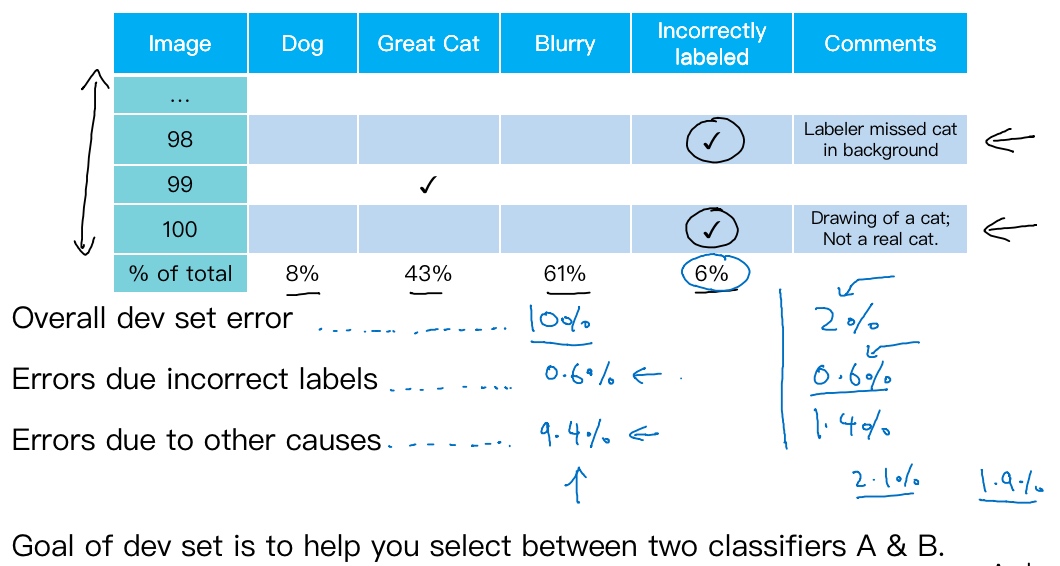
Scenario A:
系统达到了90%整体准确度,所以有10%错误率. 开发集上有10%错误,其中0.6%是因为标记出错,剩下的占9.4%,是其他原因导致的. 记出错导致的错误是总体错误的一小部分而已, 可以手工修正各种错误标签,但也许这不是当下最重要的任务.
Scenario B:
错误率降到了2%,但总体错误中的0.6%还是标记出错导致的, 其他原因导致的错误是1.4%. 当测得的那么大一部分的错误都是开发集标记出错导致的,那似乎修正开发集里的错误标签似乎更有价值.
决定要去修正开发集数据,手动重新检查标签,并尝试修正一些标签,这里还有一些额外的方针和原则需要考虑, Correcting incorrect dev/test set examples:
- Apply same process to your dev and test sets to make sure they continue to come from the same distribution
- Consider examining examples your algorithm got right as well as ones it got wrong. (要考虑同时检验算法判断正确和判断错误的样本, 这不是很容易做,所以通常不会这么做, 因为正确的样本太大)
- Train and dev/test data may now come from slightly different distributions.
快速搭建你的第一个系统,并进行迭代(Build your first system quickly, then iterate)
Depending on the area of application, the guideline below will help you prioritize when you build your system.

Guideline:
- Set up development/ test set and metrics - Set up a target
- Build an initial system quickly
- Train training set quickly: Fit the parameters
- Development set: Tune the parameters
- Test set: Assess the performance
- Use Bias/Variance analysis & Error analysis to prioritize next steps
Build your first system quickly, then iterate (use that to do bias/variance analysis, error analysis…, use the result of analysis to help you prioritize where to go next)
使用来自不同分布的数据,进行训练和测试(Training and testing on different distributions)
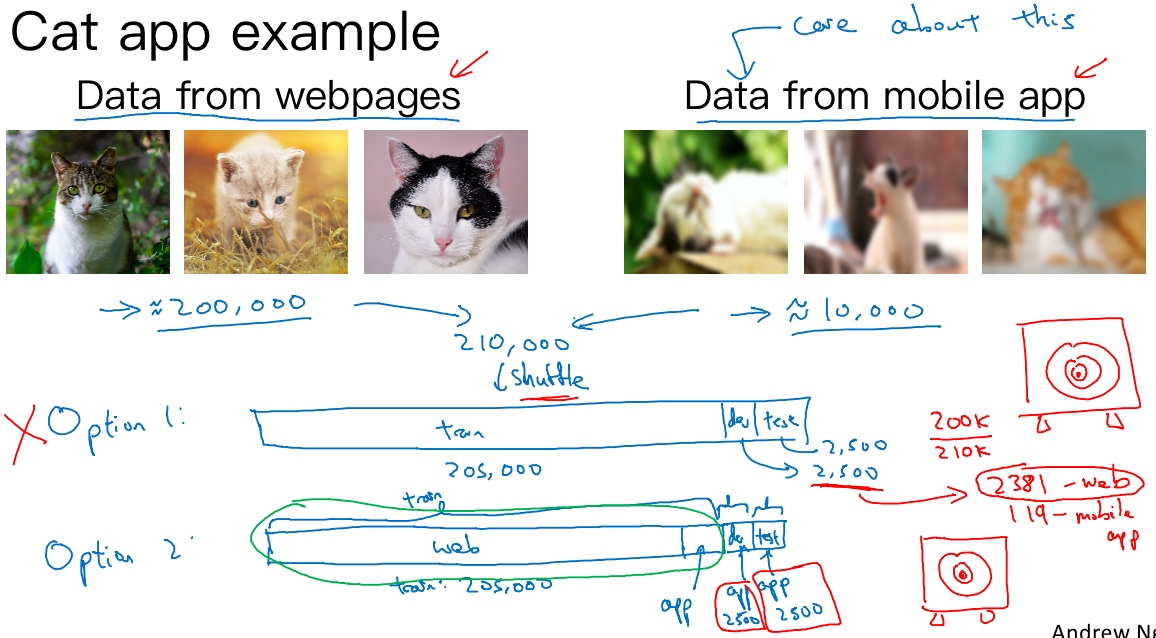
Example: Cat vs Non-cat
In this example, we want to create a mobile application that will classify and recognize pictures of cats taken and uploaded by users.
There are two sources of data used to develop the mobile app. The first data distribution is small, 10 000 pictures uploaded from the mobile application. Since they are from amateur users, the pictures are not professionally shot, not well framed and blurrier. The second source is from the web, you downloaded 200 000 pictures where cat’s pictures are professionally framed and in high resolution.
The problem is that you have a different distribution:
- small data set from pictures uploaded by users. This distribution is important for the mobile app.
- bigger data set from the web.
The guideline used is that you have to choose a development set and test set to reflect data you expect to get in the future and consider important to do well.
The data(total in 210 000) is split as follow:
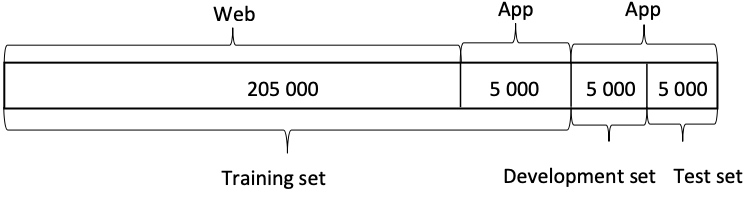 Train set: 20000Web+5000App
Train set: 20000Web+5000App
Dev set: 2500App
Test set: 2500App
The advantage of this way of splitting up is that the target is well defined(瞄准的目标就是想要处理的目标 - Data from Mobile App).
The disadvantage is that the training distribution is different from the development and test set distributions. However, this way of splitting the data has a better performance in long term.

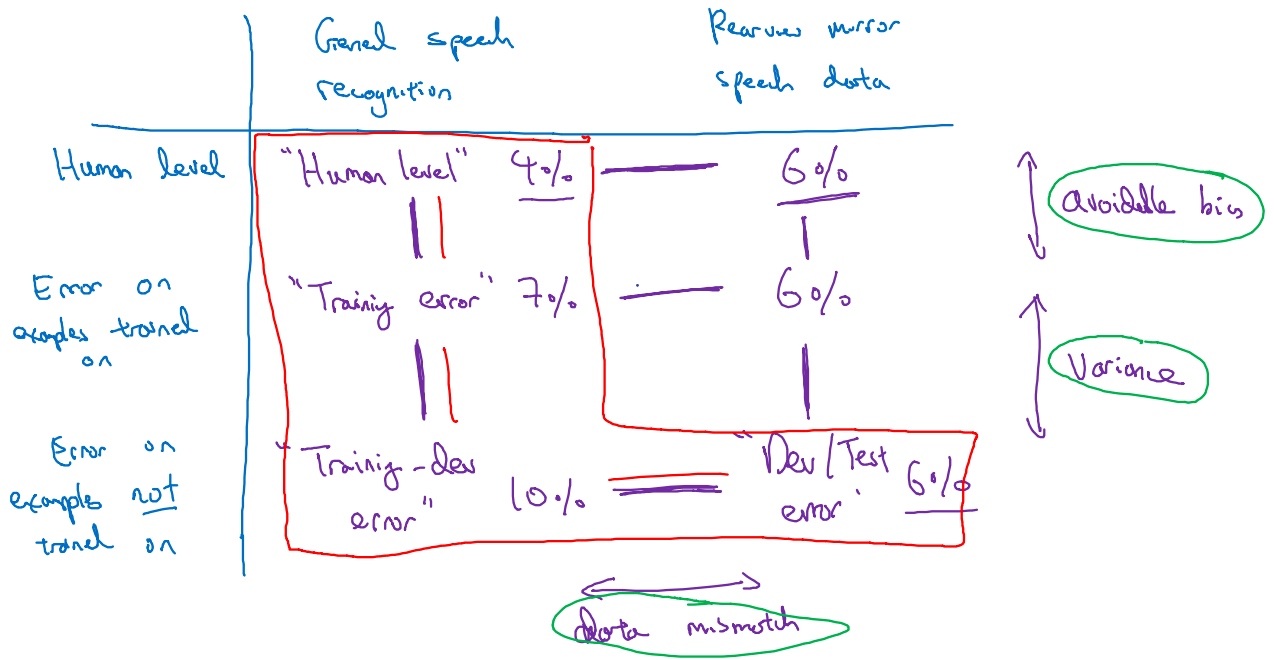
数据分布不匹配时,偏差与方差的分析(Bias and Variance with mismatched data distributions)
Bias and variance with mismatched data distributions
Example: Cat classifier with mismatch data distribution

When the training set is from a different distribution than the development and test sets, the method to analyze bias and variance changes.

Scenario A
If the development data comes from the same distribution as the training set, then there is a large variance problem and the algorithm is not generalizing well from the training set.
However, since the training data and the development data come from a different distribution, this conclusion cannot be drawn. There isn’t necessarily a variance problem. The problem might be that the development set contains images that are more difficult to classify accurately.
When the training set, development and test sets distributions are different, two things change at the same time. First of all, the algorithm trained in the training set but not in the development set. Second of all, the distribution of data in the development set is different.
It’s difficult to know which of these two changes what produces this 9% increase in error between the training set and the development set. To resolve this issue, we define a new subset called training- development set. This new subset has the same distribution as the training set, but it is not used for training the neural network.
Scenario B
The error between the training set and the training- development set is 8%. In this case, since the training set and training-development set come from the same distribution, the only difference between them is the neural network sorted the data in the training and not in the training development. The neural network is not generalizing well to data from the same distribution that it hadn’t seen before. Therefore, we have really a variance problem.
Scenario C
In this case, we have a mismatch data problem since the 2 data sets come from different distribution.
Scenario D
In this case, the avoidable bias is high since the difference between Bayes error and training error is 10 %.
Scenario E
In this case, there are 2 problems. The first one is that the avoidable bias is high since the difference between Bayes error and training error is 10 % and the second one is a data mismatched problem.
Scenario F
Development should never be done on the test set. However, the difference between the development set and the test set gives the degree of overfitting to the development set.
Bias/variance on mismatched training and dev/test sets:
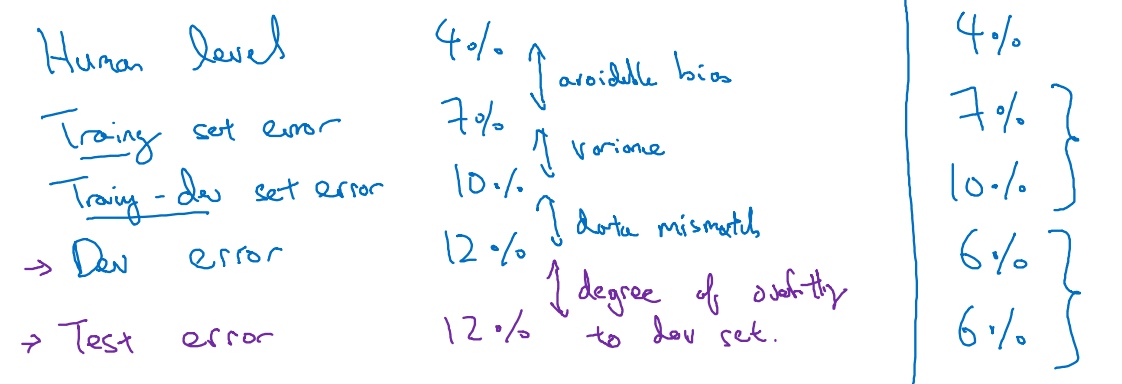
General formulation

处理数据不匹配问题(Addressing data mismatch)
This is a general guideline to address data mismatch:
- Perform manual error analysis to understand the error differences between training, development/test sets. Development should never be done on test set to avoid overfitting.
- Make training data or collect data similar to development and test sets. To make the training data more similar to your development set, you can use is artificial data synthesis.
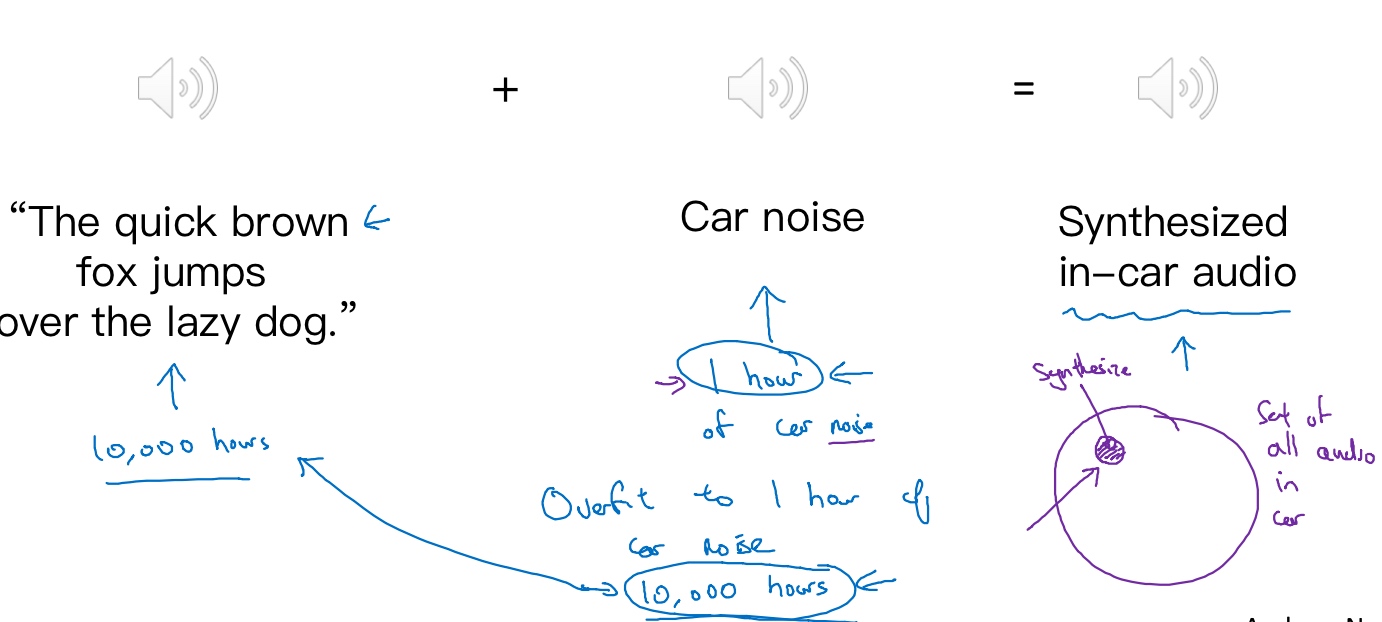
However, it is possible that if you might be accidentally simulating data only from a tiny subset of the space of all possible examples, and the model might be overfit this part of data.
迁移学习(Transfer learning)
Transfer learning refers to using the neural network knowledge for another application.
When to use transfer learning
- Task A and B have the same input 𝑥
- A lot more data for Task A than Task B
- Low level features from Task A could be helpful for Task B
Example 1: Cat recognition - radiology diagnosis
The following neural network is trained for cat recognition, but we want to adapt it for radiology diagnosis. The neural network will learn about the structure and the nature of images. This initial phase of training on image recognition is called pre-training, since it will pre-initialize the weights of the neural network. Updating all the weights afterwards is called fine-tuning.
For cat recognition
Input 𝑥: image
Output 𝑦 – 1: cat, 0: no cat

Radiology diagnosis
Input 𝑥: Radiology images – CT Scan, X-rays
Output 𝑦 :Radiology diagnosis – 1: tumor malign, 0: tumor benign

Guideline
- Delete last layer of neural network
- Delete weights feeding into the last output layer of the neural network
- Create a new set of randomly initialized weights for the last layer only
- New data set (𝑥, 𝑦)
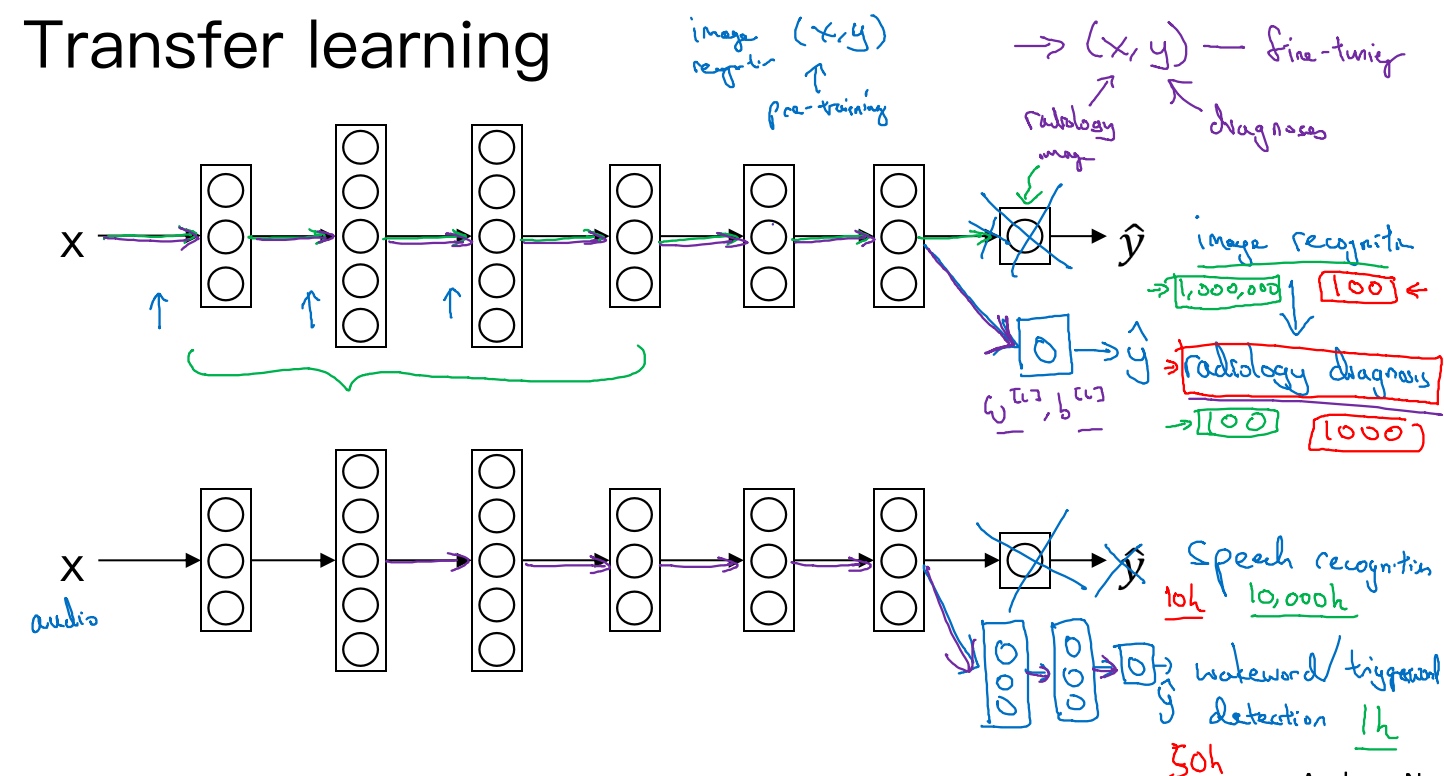
When transfer learning makes sense/be applicable
- Task A and B have the same input x. (like both are images, vedio…)
- You have a lot more data for Task A than Task B. (Transfering from a problem with a lot of data to a problem with relatively little data)
- Low level features from A could be helpful for learning B. (low level features like edge detection..)
多任务学习(Multi-task learning)
Multi-task learning refers to having one neural network do simultaneously several tasks.
Example: Simplified autonomous vehicle
The vehicle has to detect simultaneously several things: pedestrians, cars, road signs, traffic lights, cyclists, etc. We could have trained four separate neural networks, instead of train one to do four tasks. However, in this case, the performance of the system is better when one neural network is trained to do four tasks than training four separate neural networks since some of the earlier features in the neural network could be shared between the different types of objects. (One neural network doing 4 things results in better performance than training 4 separate nn)

The input $x^{(i)}$ is the image with multiple labels
The output $y^{(i)}$ has 4 labels which are represents:

Neural Network architecture:

Also, the cost can be compute such as it is not influenced by the fact that some entries are not labeled.
(omit that term from summation but just sum over only the values where there is a label)
Example:
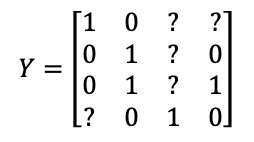
When multi-task learning makes sense:
- Training on a set of tasks that could benefit from having shared lower-level features.
- Usually: Amount of data you have for each task is quite similar. (recall transfer learning)
- Can train a big enough neural network to do well on all the tasks.
Rich Carona发现:
多任务学习和训练单个神经网络相比会降低性能的唯一情况就是神经网络还不够大。但如果可以训练一个足够大的神经网络,那么多任务学习肯定不会或者很少会降低性能.
在实践中,多任务学习的使用频率要低于迁移学习. 一个例外是计算机视觉,物体检测。在那些任务中,人们经常训练一个神经网络同时检测很多不同物体,这比训练单独的神经网络来检测视觉物体要更好
什么是端到端的深度学习?(What is end-to-end deep learning?)
End-to-end deep learning is the simplification of a processing or learning systems into one neural network. (以前有一些数据处理系统或者学习系统,它们需要多个阶段的处理. 端到端深度学习就是忽略所有这些不同的阶段,用单个神经网络代替它)
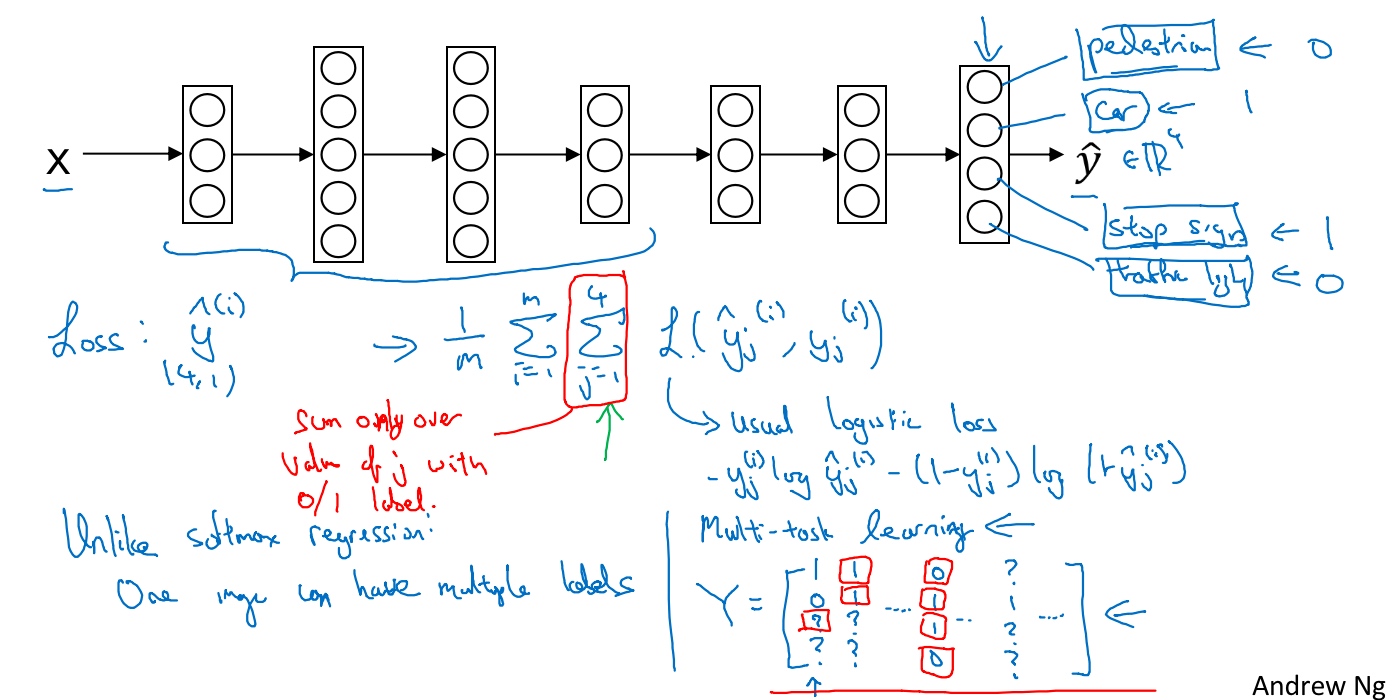
Example - Speech recognition model
The traditional way - small data set works well

The hybrid way - medium data set

The End-to-End deep learning way – large data set works even better

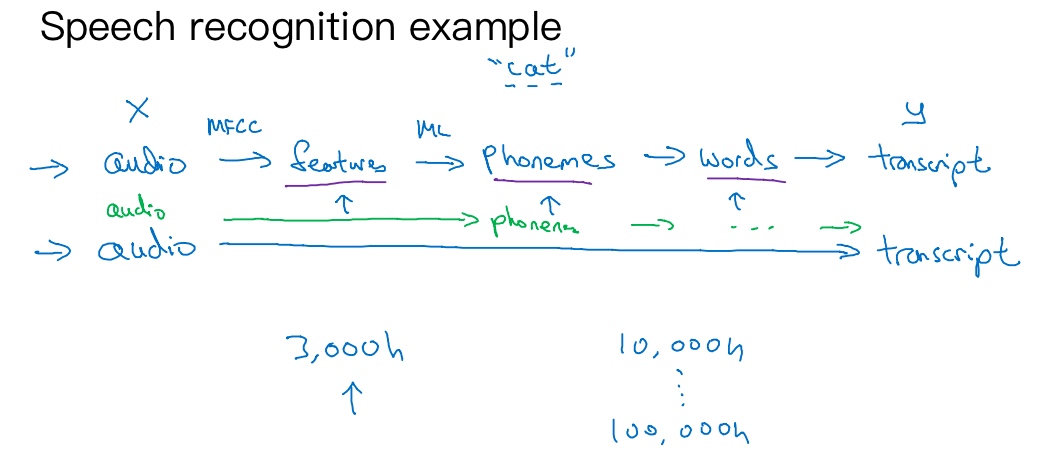
End-to-End approach:
Image -> Identity
BUT best practice:
- One nn to detect the face
- One nn to identify the person
Why is it that the 2 steps approach works better:
- Each of the 2 problems is actually much simplier
- Have a lot of data for each of the 2 sub-tasks!!!!
End-to-end deep learning cannot be used for every problem since it needs a lot of labeled data. It is used mainly in audio transcripts, image captures, image synthesis, machine translation, steering in self-driving cars, etc.
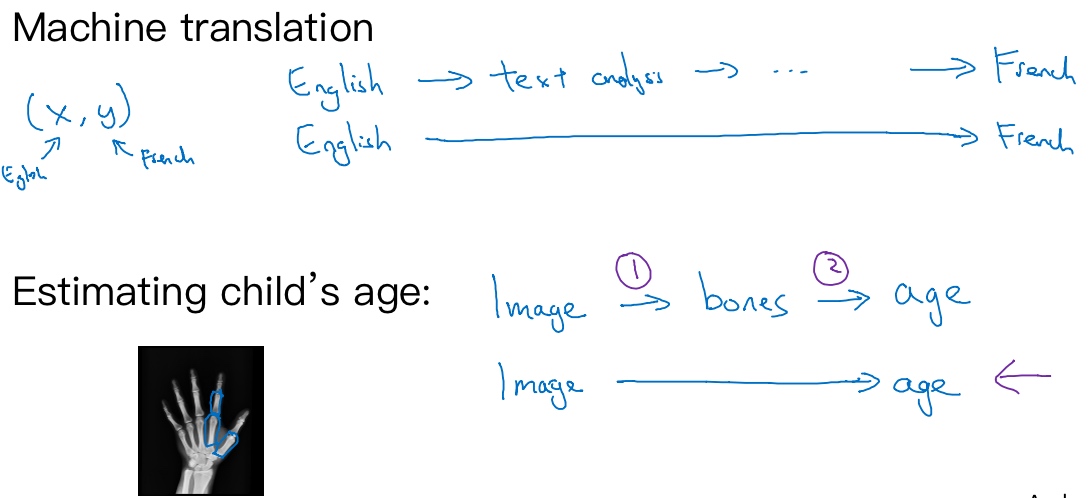
机器翻译。传统上,机器翻译系统也有一个很复杂的流水线,比如英语机翻得到文本,然后做文本分析,基本上要从文本中提取一些特征之类的,经过很多步骤,你最后会将英文文本翻译成法文。因为对于机器翻译来说的确有很多(英文,法文)的数据对,端到端深度学习在机器翻译领域非常好用,那是因为在今天可以收集x-y对的大数据集,就是英文句子和对应的法语翻译。所以在这个例子中,端到端深度学习效果很好。
估计一个孩子的年龄, 处理这个例子的一个非端到端方法,就是照一张图,然后分割出每一块骨头,所以就是分辨出哪段骨头应该在哪里. 然后,知道不同骨骼的长度,你可以去查表,查到儿童手中骨头的平均长度,然后用它来估计孩子的年龄,所以这种方法实际上很好。
是否要使用端到端的深度学习?(Whether to use end-to-end learning?)
Before applying end-to-end deep learning, you need to ask yourself the following question: Do you have enough data to learn a function of the complexity needed to map x and y?
Pro:
- Let the data speak
- By having a pure machine learning approach, the neural network will learn from x to y. It will be able to find which statistics are in the data, rather than being forced to reflect human preconceptions.
- Less hand-designing of components needed
- It simplifies the design work flow.
Cons:
- May need large amount of labeled data
- It cannot be used for every problem as it needs a lot of labeled data.
- Excludes potentially useful hand-designed component
- Data and any hand-design’s components or features are the 2 main sources of knowledge for a learning algorithm. If the data set is small than a hand-design system is a way to give manual knowledge into the algorithm.
Apply ene-to-end deep learning:
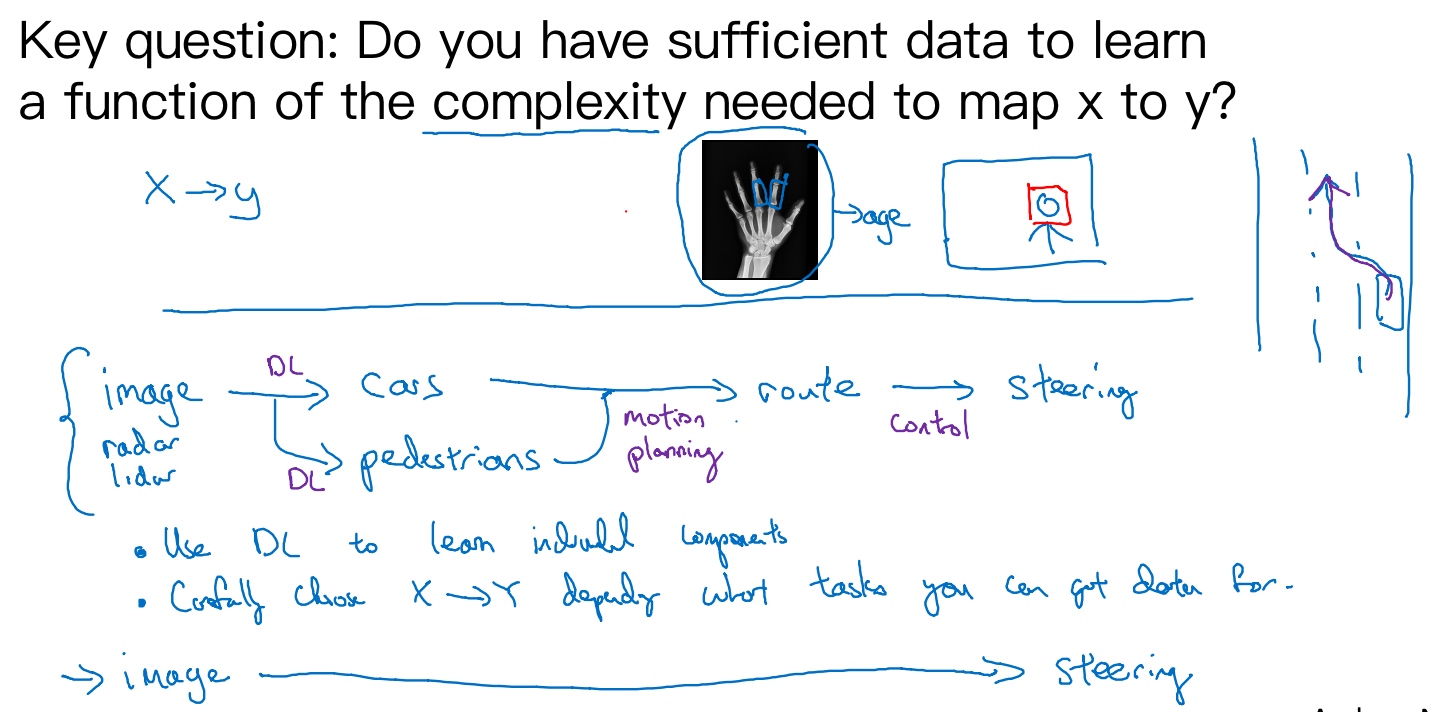
一个更复杂的例子,你可能知道我一直在花时间帮忙主攻无人驾驶技术的公司drive.ai,无人驾驶技术的发展其实让我相当激动,你怎么造出一辆自己能行驶的车呢?好,这里你可以做一件事,这不是端到端的深度学习方法,你可以把你车前方的雷达、激光雷达或者其他传感器的读数看成是输入图像。但是为了说明起来简单,我们就说拍一张车前方或者周围的照片,然后驾驶要安全的话,你必须能检测到附近的车,你也需要检测到行人,你需要检测其他的东西,当然,我们这里提供的是高度简化的例子。
弄清楚其他车和形如的位置之后,你就需要计划你自己的路线。所以换句话说,当你看到其他车子在哪,行人在哪里,你需要决定如何摆方向盘在接下来的几秒钟内引导车子的路径。如果你决定了要走特定的路径,也许这是道路的俯视图,这是你的车,也许你决定了要走那条路线,这是一条路线,那么你就需要摆动你的方向盘到合适的角度,还要发出合适的加速和制动指令。所以从传感器或图像输入到检测行人和车辆,深度学习可以做得很好,但一旦知道其他车辆和行人的位置或者动向,选择一条车要走的路,这通常用的不是深度学习,而是用所谓的运动规划软件完成的。如果你学过机器人课程,你一定知道运动规划,然后决定了你的车子要走的路径之后。还会有一些其他算法,我们说这是一个控制算法,可以产生精确的决策确定方向盘应该精确地转多少度,油门或刹车上应该用多少力。
- Use DL to learn individual components
- Carefully choose x->y depending on what task you can get data for
这个例子就表明了,如果你想使用机器学习或者深度学习来学习某些单独的组件,那么当你应用监督学习时,你应该仔细选择要学习的x到y映射类型,这取决于那些任务你可以收集数据。相比之下,谈论纯端到端深度学习方法是很激动人心的,你输入图像,直接得出方向盘转角,但是就目前能收集到的数据而言,还有我们今天能够用神经网络学习的数据类型而言,这实际上不是最有希望的方法,或者说这个方法并不是团队想出的最好用的方法。而我认为这种纯粹的端到端深度学习方法,其实前景不如这样更复杂的多步方法。因为目前能收集到的数据,还有我们现在训练神经网络的能力是有局限的。