15. Sequence models & Attention mechanism
基础模型(Basic Models)
[Sutskever et al., 2014. Sequence to sequence learning with neural networks]
[Cho et al., 2014. Learning phrase representations using RNN encoder-decoder for statistical machine translation]
Sequence to sequence (seq2seq)模型在机器翻译和语音识别方面都有着广泛的应用.
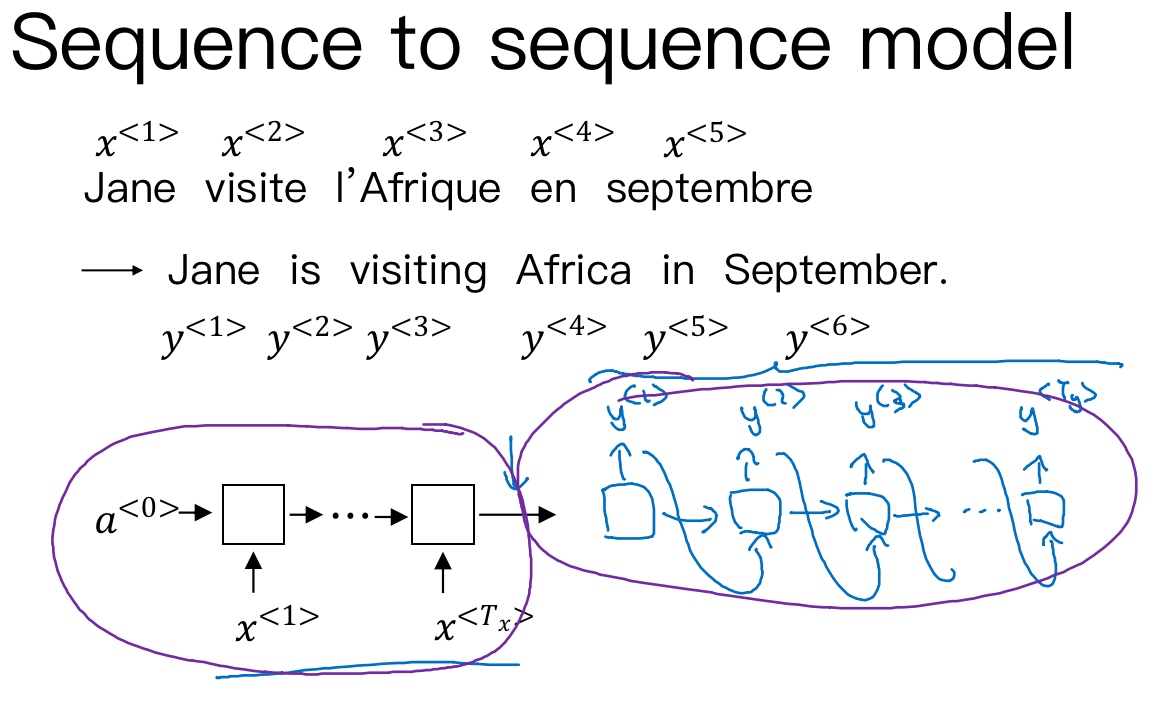
针对该机器翻译问题,可以使用’编码网络(encoder network)’ + ‘解码网络(decoder network)’ 两个RNN模型组合的形式来解决. encoder network将输入语句编码为一个特征向量, 传递给decoder network,完成翻译. 具体模型结构如下图所示.
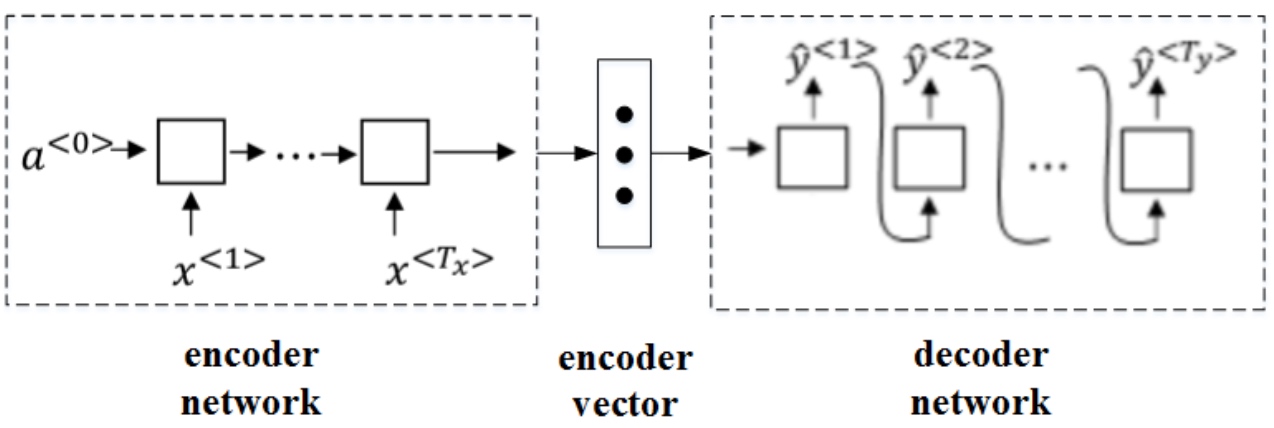
其中, encoder vector代表了输入语句的编码特征. encoder network和decoder network都是RNN模型, 可使用GRU或LSTM单元. 这种’encoder-decoder’模型, 在实际的机器翻译应用中有着不错的效果.
这种模型也可以应用到图像捕捉领域 (image to sequence模型). 图像捕捉(Image Captioning),即捕捉图像中主体动作和行为,描述图像内容. 例如下面这个例子,根据图像,捕捉图像内容.
[Mao et. al., 2014. Deep captioning with multimodal recurrent neural networks]
[Vinyals et. al., 2014. Show and tell: Neural image caption generator]
[Karpathy and Li, 2015. Deep visual-semantic alignments for generating image descriptions]
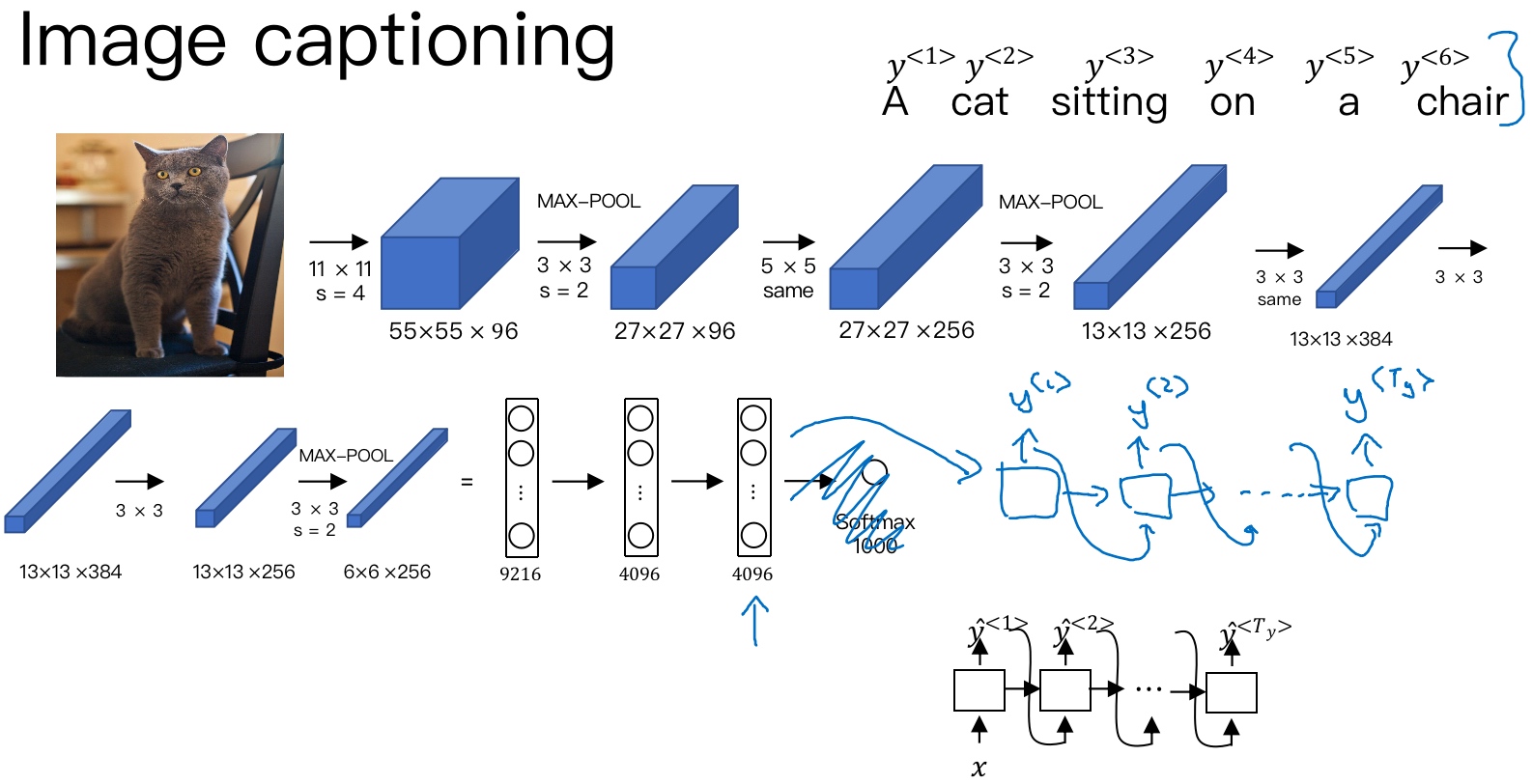
首先,可以将图片输入到CNN, 例如使用预训练好的AlexNet, 删去最后的softmax层, 保留至最后的全连接层. 则该全连接层就构成了一个图片的4096维特征向量(编码向量encoder vector), 表征了图片特征信息.
然后,将encoder vector输入至RNN, 即decoder network中,进行解码翻译.
选择最可能的句子(Picking the most likely sentence)
Sequence to sequence machine translation模型与language模型有一些相似,但也存在不同之处. 二者模型结构如下所示:
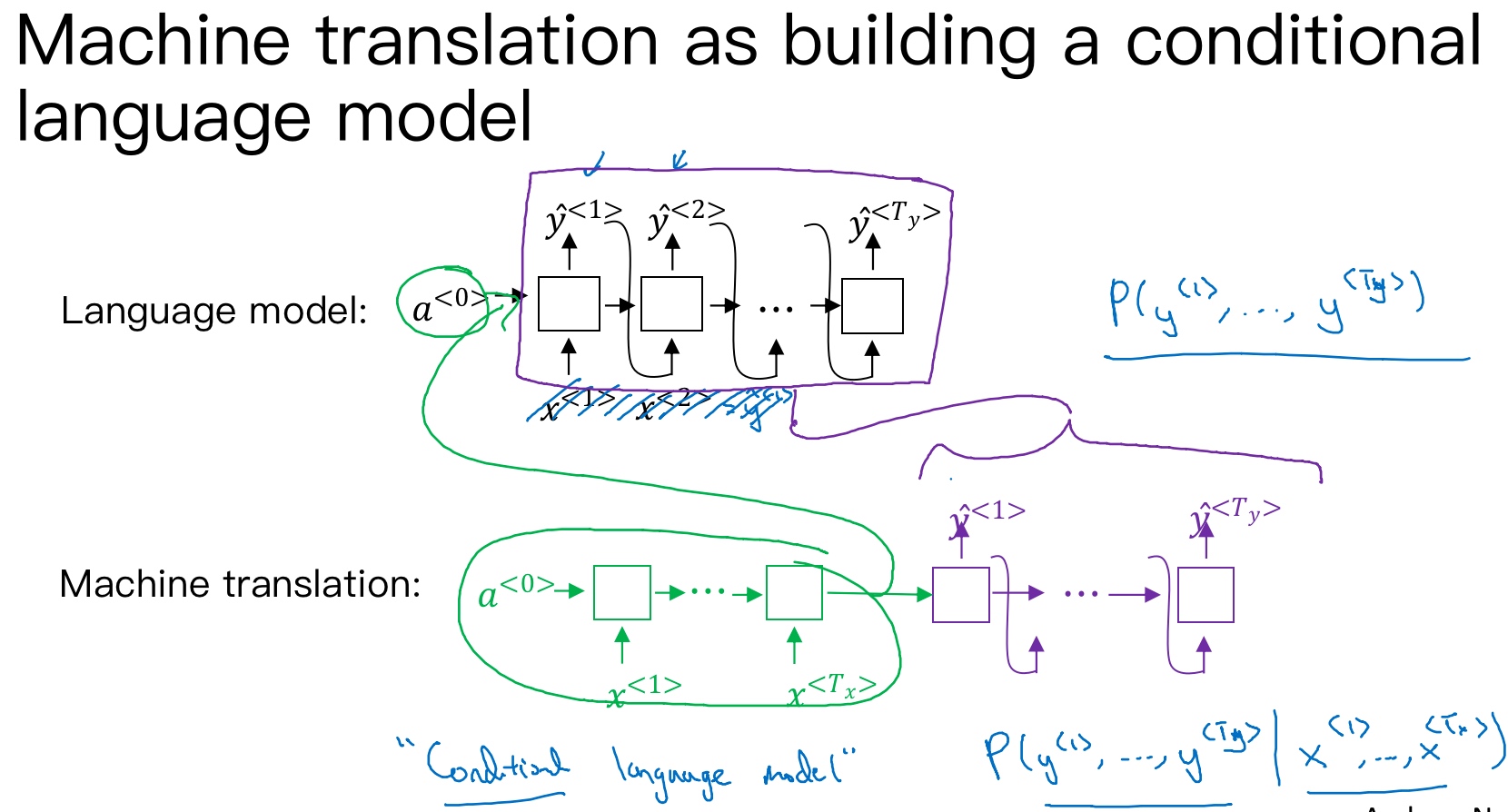
- Language model是自动生成一条完整语句,语句是随机的
- 而machine translation model是根据输入语句,进行翻译,生成另外一条完整语句
- 上图中,绿色部分表示encoder network,紫色部分表示decoder network.
- decoder network与language model是相似的,encoder network可以看成是language model的
$a^{<0>}$ - 语言模型总是以零向量开始,而encoder网络会计算出一系列向量来表示输入的句子
- decoder网络就可以以这个句子开始, 相当于它是模型的一个条件. 也就是说,在输入语句的条件下,生成正确的翻译语句.
- 因此,machine translation可以看成是有条件的语言模型(conditional language model). 这就是二者之间的区别与联系
- decoder network与language model是相似的,encoder network可以看成是language model的
所以,machine translation的目标就是根据输入语句,作为条件,找到最佳翻译语句,使其概率最大:
$max\ P(y^{<1>},y^{<2>},\cdots,y^{<T_y>}|x^{<1>},x^{<2>},\cdots,x^{<T_x>})$
例如, 同一句法语, 模型可能得到几个不同的英文翻译:

显然,第一条翻译“Jane is visiting Africa in September.”最为准确. 那我们的优化目标就是要让这条翻译对应的$P(y^{\lt 1 \gt},\cdots,y^{\lt T_y \gt}|x)$最大化:
$$\mathop{argmax}_{y^{<1>},...,y^{<T_y>}}{P(y^{\lt 1 \gt},\cdots,y^{\lt T_y \gt}|x)}$$
找到一个英语句子, 使得条件概率最大化.
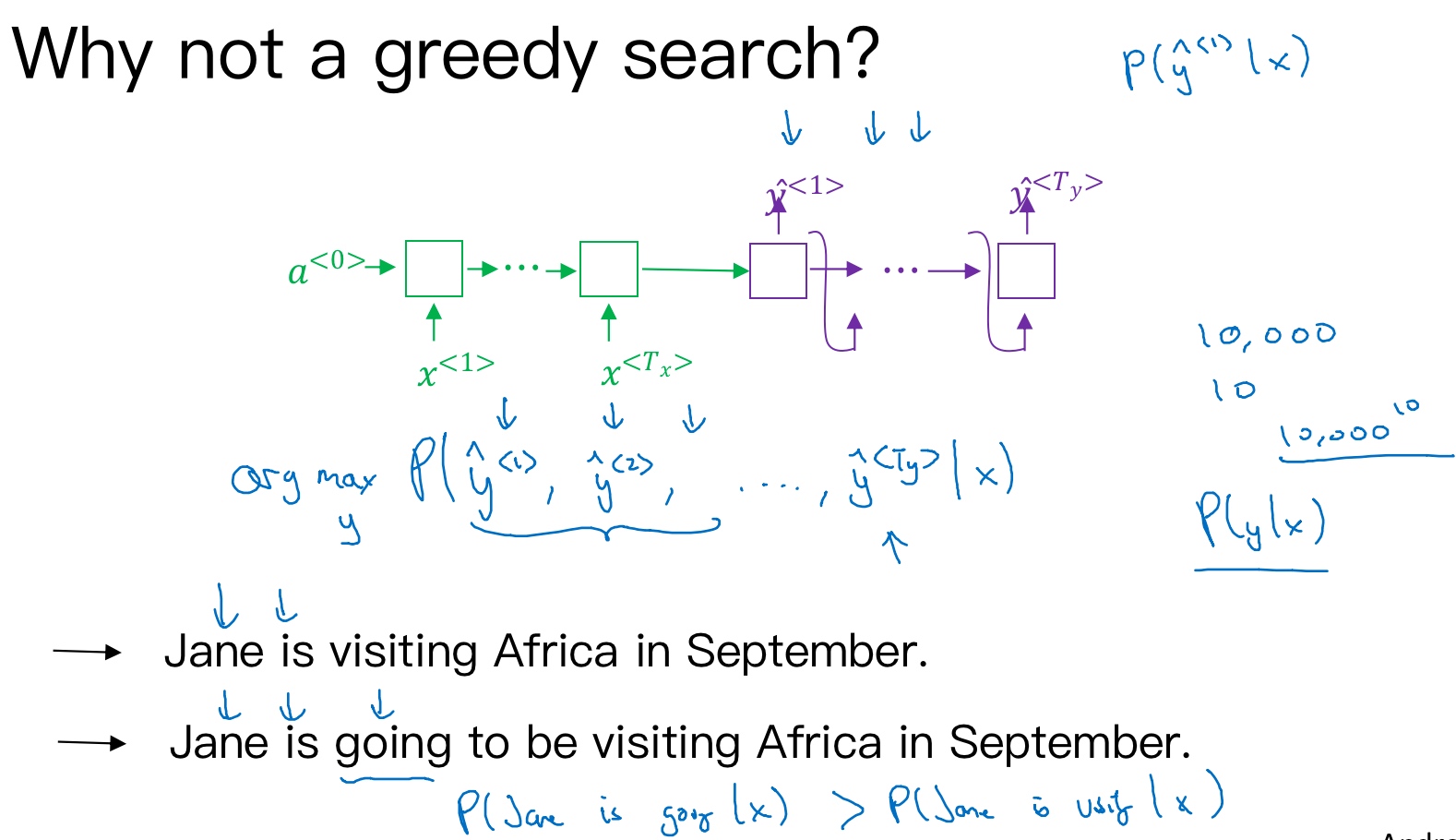
实现优化目标的方法之一是使用贪婪搜索(greedy search). Greedy search根据条件语言模型挑选出最有可能的一个词,每次只寻找一个最佳单词(概率最高)作为翻译输出,力求把每个单词都翻译准确. 例如,首先根据输入语句,找到第一个翻译的单词’Jane’, 然后再找第二个单词’is’, 再继续找第三个单词’visiting’, 以此类推, 这也是其“贪婪”名称的由来.
Greedy search存在一些缺点.
- 首先,因为greedy search每次只搜索一个单词,没有考虑该单词前后关系,概率选择上有可能会出错. 例如,上面翻译语句中,第三个单词’going’比’visiting’更常见,模型很可能会错误地选择了’going’, 而错失最佳翻译语句.
- 其次,greedy search一次仅仅挑选一个词, 大大增加了运算成本,降低运算速度. 如果字典中有10,000个单词(即每个softmax output都是10,000),并且翻译可能有10个词,那么可能的组合就有10,000的10次方
因此,greedy search并不是最佳的方法. 而Beam Search,使用近似最优的查找方式,最大化输出概率,寻找最佳的翻译语句.
集束搜索(Beam Search)
Greedy search每次是找出预测概率最大一个的单词,而beam search则是每次找出预测概率最大的B个单词. 集束搜索算法会有一个参数B表示取概率最大的单词个数(beam width), 可调. 本例中,令B=3, 表示一次会考虑3个结果.
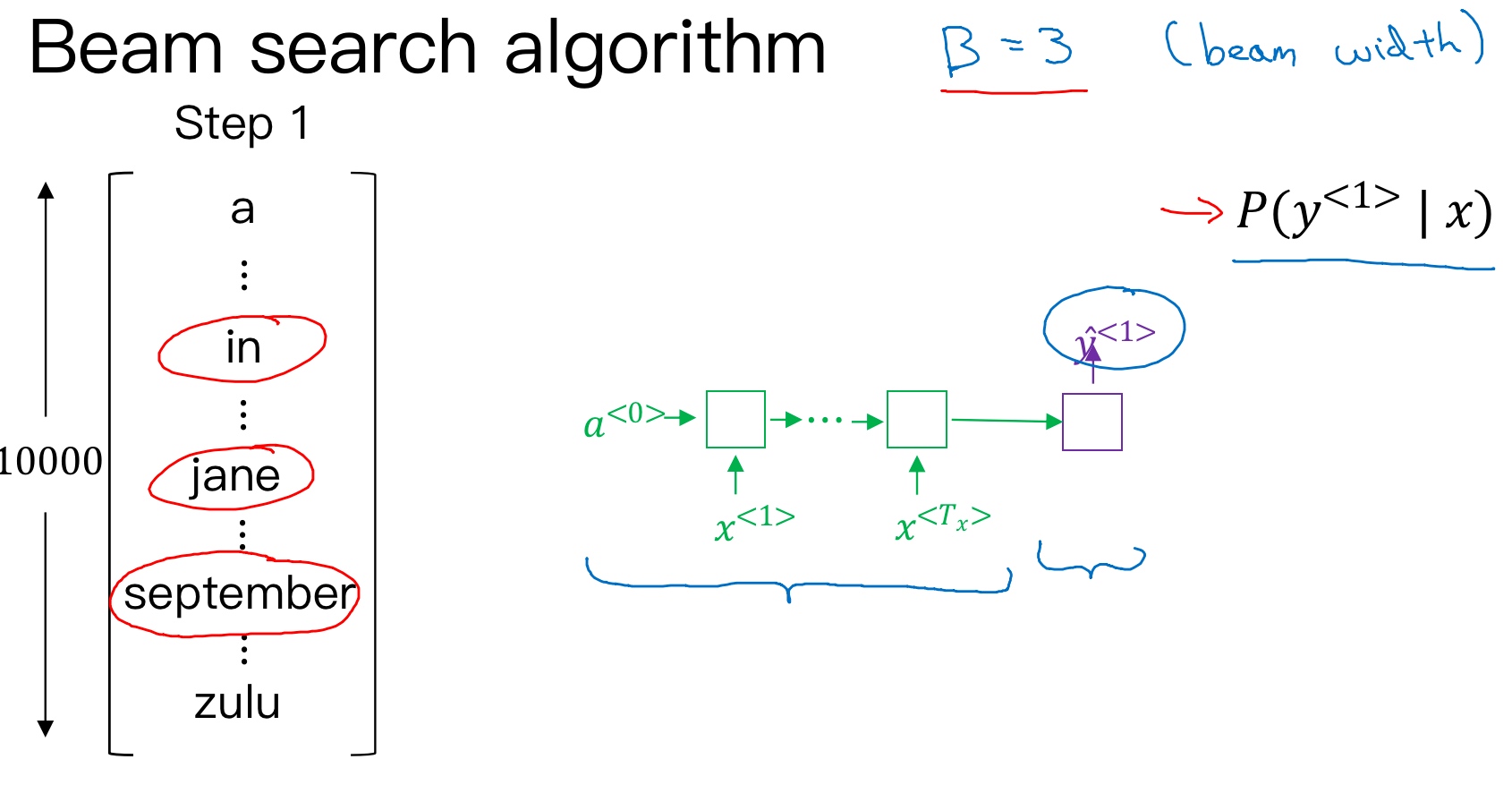
按照beam search的搜索原理,首先,先从词汇表中找出翻译的第一个单词概率最大的B个预测单词 (softmax层会输出10,000个概率值, 取前三个存到计算机内存里). 例如上面的例子中,预测得到的第一个单词为:in,jane,september.
概率表示为:$P(\hat y^{<1>} | x)$
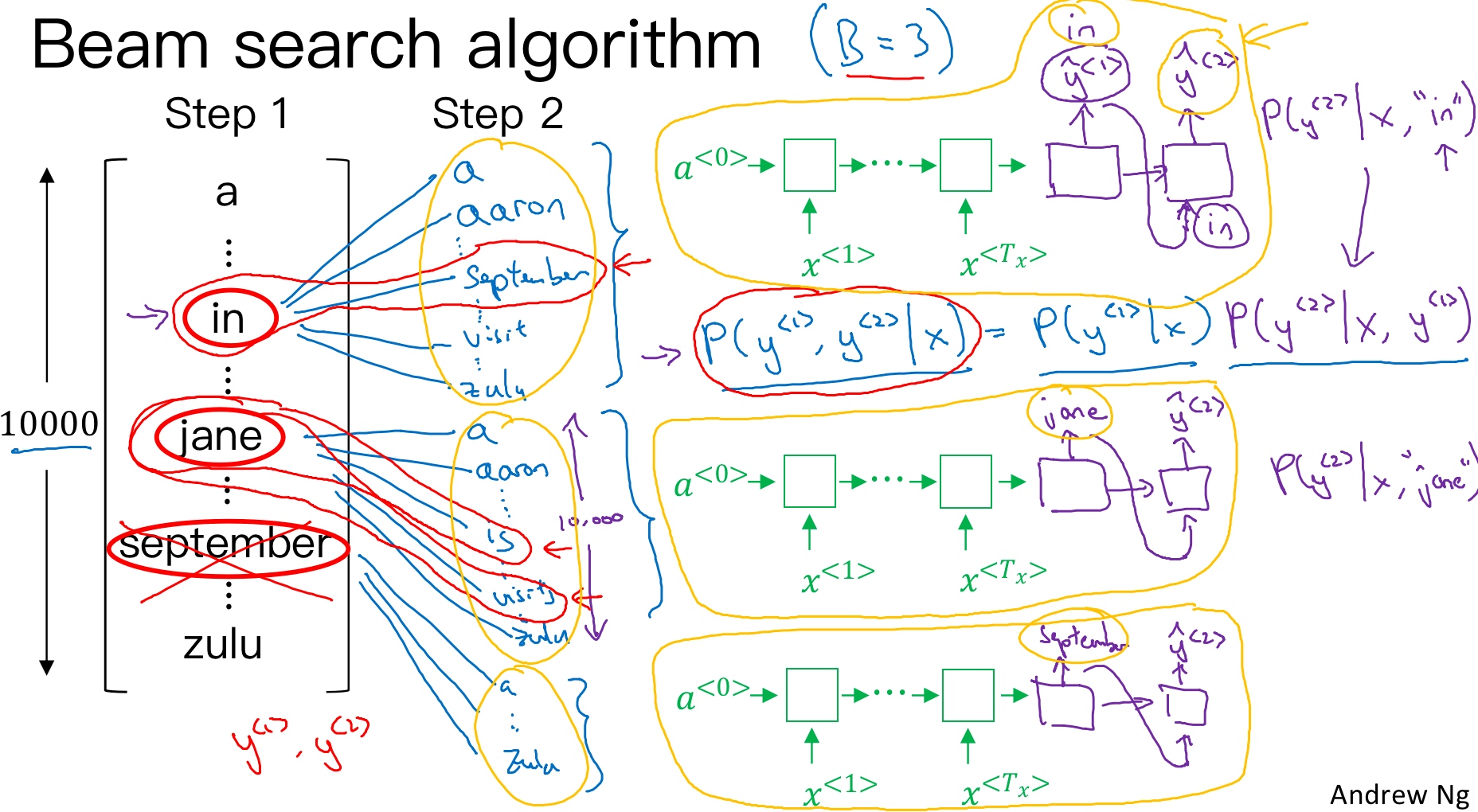
然后,再分别以in,jane,september为条件,计算每个词汇表单词作为预测第二个单词的概率.
在给定法语句子和翻译结果的第一个单词(in/jane/september)的情况下, 这个网络就可以用来评估第二个单词的概率 (注意, 它找的不是有最大概率的第二个单词, 而是有最大概率的第一个、第二个单词对). 按照条件概率的准则,这个可以表示成第一个单词的概率乘以第二个单词的概率 $P(y^{<1>},y^{<2>} | x) = P(y^{<1>}| x)P(y^{<2>} | x,y^{<1>})$
由于B=3, 并且词汇表里有10,000个单词, 那么最终会有3乘以10,000也就是30,000个可能的结果. (因为对于第二个单词的选择, in, jane, september各自分别有10,000个选择)
最后, 从这30,000个结果中选择概率最大的3个作为第二个单词的预测值, 得到:in september,jane is,jane visits
概率表示为:$P(\hat y^{<2>}|x,\hat y^{<1>})$
此时,得到的前两个单词的3种情况的概率为:
$P(\hat y^{<1>},\hat y^{<2>}|x)=P(\hat y^{<1>} | x)\cdot P(\hat y^{<2>}|x,\hat y^{<1>})$
值得一提的是, 由于集束宽等于3,所以有三个网络副本(上图3个黄圈), 每个网络的第一个单词不同,而这三个网络可以高效地评估第二个单词所有的30,000个选择. 所以不需要初始化30,000个网络副本,只需要使用3个网络的副本就可以快速的评估softmax的输出,即$\hat y^{<2>}$的10,000个结果
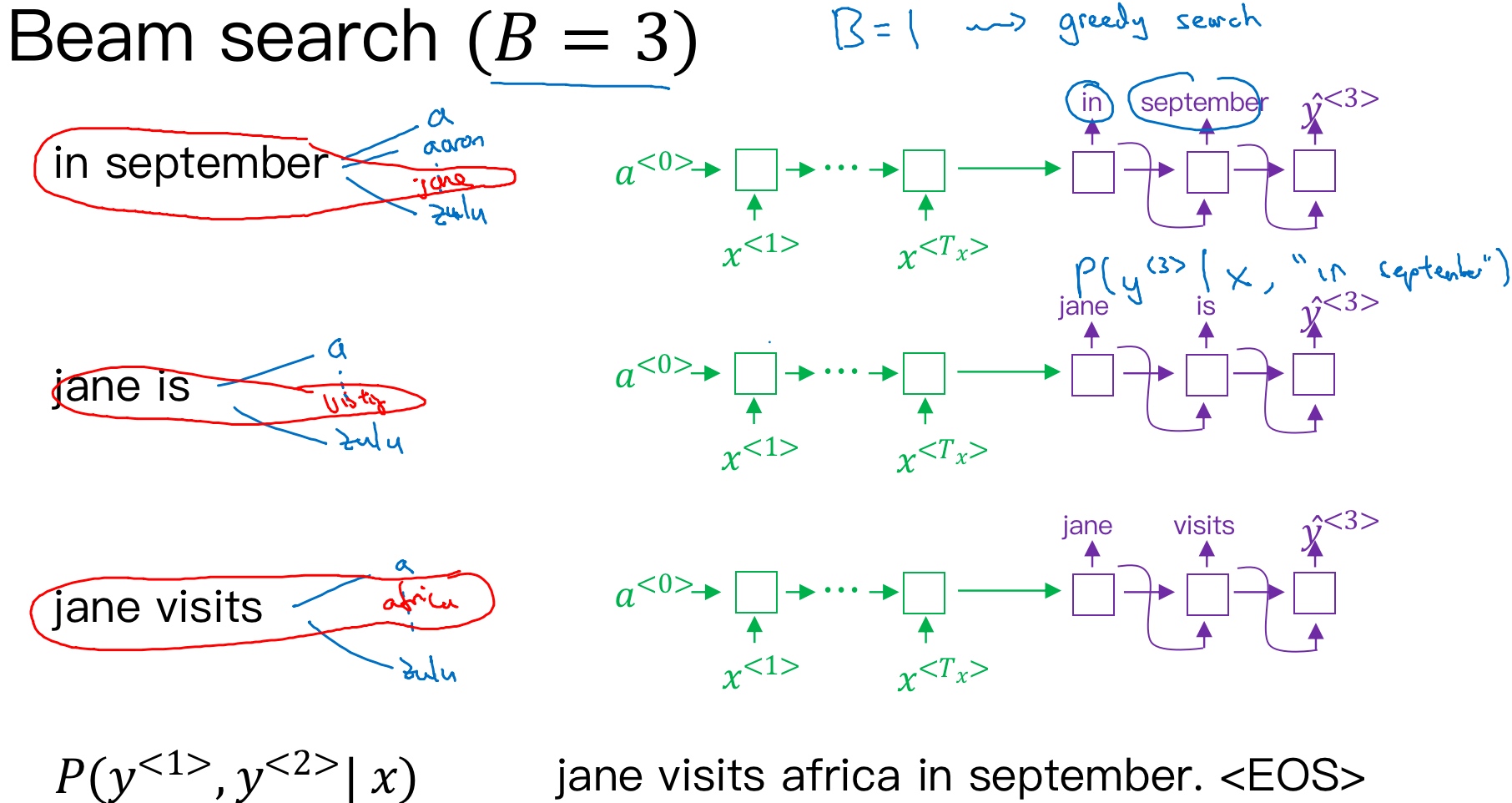
接着,再预测第三个单词. 方法一样,分别以in september,jane is,jane visits为条件,计算每个词汇表单词作为预测第三个单词的概率. 从中选择概率最大的3个作为第三个单词的预测值,得到:in september jane,jane is visiting,jane visits africa.
概率表示为:$P(\hat y^{<3>}|x,\hat y^{<1>},\hat y^{<2>})$
此时,得到的前三个单词的3种情况的概率为:
$P(\hat y^{<1>},\hat y^{<2>},\hat y^{<3>}|x)=P(\hat y^{<1>} | x)\cdot P(\hat y^{<2>}|x,\hat y^{<1>})\cdot P(\hat y^{<3>}|x,\hat y^{<1>},\hat y^{<2>})$
以此类推,每次都取概率最大的三种预测. 最后,选择概率最大的那一组作为最终的翻译语句.
Jane is visiting Africa in September.
值得注意的是,如果参数B=1,则就等同于greedy search. 实际应用中,可以根据不同的需要设置B为不同的值. 一般B越大,机器翻译越准确,但同时也会增加计算复杂度
改进集束搜索(Refinements to Beam Search)

Beam search中,最终机器翻译的概率是乘积的形式(集束搜索就是最大化这个概率):
$arg\ max\prod_{t=1}^{T_y} P(\hat y^{<t>}|x,\hat y^{<1>},\cdots,\hat y^{<t-1>})$
多个概率相乘可能会使乘积结果很小,远小于1,造成数值下溢(numerical underflow, 数值下溢就是数值太小了, 导致电脑的浮点表示不能精确地储存). 为了解决这个问题,可以对上述乘积形式进行取对数log运算,就变成了:
$arg\ max\sum_{t=1}^{T_y} P(\hat y^{<t>}|x,\hat y^{<1>},\cdots,\hat y^{<t-1>})$
因为取对数运算,将乘积转化为求和形式,避免了数数值的舍入误差(rounding errors)或者说数值下溢(numerical underflow),使得数据更加稳定有效.
log函数式严格单调递增(strictly monotonically increasing)函数, 最大化log P(y|x)的结果应该和最大化 P(y|x) 的结果是一样的. 如果有一个y值能够使log P(y|x)最大化, 那么也一定可以使P(y|x)最大化. 所以实际工作中,总是记录概率的对数和(the sum of logs of the probabilities),而不是概率的乘积(the production of probabilities)
这种概率表达式还存在一个问题,就是机器翻译的单词越多,乘积形式或求和形式得到的概率就越小 (概率log的值通常小于等于1,所以加起来的项越多,得到的结果越负),这样会造成模型倾向于选择单词数更少的翻译语句,使机器翻译受单词数目的影响,这显然是不太合适的. 因此,一种改进方式是进行长度归一化(normalize this by the number of words in your translation),这样就是取每个单词的概率对数值的平均了, 消除语句长度影响(this significantly reduces the penalty for outputting longer translations).
$arg\ max\ \frac{1}{T_y}\sum_{t=1}^{T_y} P(\hat y^{<t>}|x,\hat y^{<1>},\cdots,\hat y^{<t-1>})$
实际应用中,有时会用一个更柔和的方法(a softer approach), 通常会引入归一化因子$\alpha$:
$arg\ max\ \frac{1}{T_y^{\alpha}}\sum_{t=1}^{T_y} P(\hat y^{<t>}|x,\hat y^{<1>},\cdots,\hat y^{<t-1>})$
若$\alpha=1$,则完全进行长度归一化;若$\alpha=0$,则不进行长度归一化. 一般令$\alpha=0.7$, 效果不错. $alpha$就是算法另一个超参数(hyper parameter), 需要调整大小来得到最好的结果.

- 如果束宽很大,你会考虑很多的可能,你会得到一个更好的结果,但是算法会运行的慢一些,内存占用也会增大,计算起来会慢一点
- 而如果你用小的束宽,结果会没那么好,因为你在算法运行中,保存的选择更少,但是你的算法运行的更快,内存占用也小
- 例子中用了束宽为3,所以会保存3个可能选择,在实践中这个值有点偏小. 在产品中,经常可以看到把束宽设到10
值得一提的是,与BFS (Breadth First Search) 、DFS (Depth First Search) (这些都是精确的搜索算法(exact search algorithms))算法不同,beam search (approximate search algorithm)运算速度更快,但是并不保证一定能找到正确的翻译语句(找到argmax的准确的最大值)
集束搜索的误差分析(Error analysis in beam search)
Beam search束搜索算法是一种近似搜索算法(an approximate search algorithm),也被称作启发式搜索算法(a heuristic search algorithm), 它不总是输出可能性最大的句子,它仅记录着B为前3或者10或是100种可能. 实际应用中,如果机器翻译效果不好,需要通过错误分析,判断是RNN模型问题还是beam search算法问题.
一般来说,增加训练样本、增大beam search参数B都能提高准确率. 但是,这种做法并不能得到我们期待的性能,且并不实际.

首先,为待翻译语句建立人工翻译,记为$y^*$. 在RNN模型上使用beam search算法,得到机器翻译,记为$\hat y$. 显然,人工翻译$y^*$最为准确.
- Jane visite l’Afrique en septembre.
- Human: Jane visits Africa in September.
$y^*$ - Algorithm: Jane visited Africa last September.
$\hat y$
这样,整个模型包含两部分:RNN (seq2seq / encoder-decoder)和beam search算法.
然后,将输入语句输入到RNN模型中,分别计算输出是$y^*$的概率$P(y^*|x)$和$\hat y$ 的概率$P(\hat y|x)$

接下来就是比较$P(y^*|x)$和$P(\hat y|x)$的大小:
$P(y^*|x) \gt P(\hat y|x)$:Beam search算法有误$P(y^*|x) \lt P(\hat y|x)$:RNN模型有误

如果beam search算法表现不佳,可以调试参数B;若RNN模型不好,则可以增加网络层数,使用正则化,增加训练样本数目等方法来优化.
Bleu 得分(选修)(Bleu Score (optional))
[Papineni, Kishore& Roukos, Salim & Ward, Todd & Zhu, Wei-jing. (2002). BLEU: a Method for Automatic Evaluation of Machine Translation.10.3115⁄1073083.1073135.]
使用bleu score (bilingual evaluation understudy (双语评估替补)), 对机器翻译进行打分.
- 在戏剧界,侯补演员(understudy)学习资深的演员的角色,这样在必要的时候,他们就能够接替这些资深演员。而BLEU的初衷是相对于请评估员(ask human evaluators),人工评估机器翻译系统(the machine translation system),BLEU得分就相当于一个侯补者,它可以代替人类来评估机器翻译的每一个输出结果

首先,对原语句建立人工翻译参考,一般有多个人工翻译(利用验证集/测试集). 例如下面这个例子:
- French: Le chat est sur le tapis.
- Reference 1: The cat is on the mat.
- Reference 2: There is a cat on the mat.
上述两个人工翻译都是正确的,作为参考. 相应的机器翻译如下所示:
- French: Le chat est sur le tapis.
- Reference 1: The cat is on the mat.
- Reference 2: There is a cat on the mat.
- MT output: the the the the the the the.
如上所示,机器翻译为’the the the the the the the.‘, 效果很差. Bleu Score的宗旨是机器翻译越接近参考的人工翻译,其得分越高,方法原理就是看机器翻译的各个单词是否出现在参考翻译中.
最简单的准确度评价方法是看机器翻译的每个单词是否出现在参考翻译中. 显然,上述机器翻译的每个单词都出现在参考翻译里,准确率为$\frac77=1$ ,其中,分母为机器翻译单词数目,分子为相应单词是否出现在参考翻译中. 但是,这种方法很不科学,并不可取.
另外一种评价方法是看机器翻译单词出现在参考翻译单个语句中的次数,取最大次数. 上述例子对应的准确率为$\frac27 $,其中,分母为机器翻译单词数目,分子为相应单词出现在参考翻译中的次数(分子为2是因为’the’在参考1中出现了两次). 这种评价方法较为准确.

上述两种方法都是对单个单词进行评价. 按照beam search的思想,另外一种更科学的打分方法是bleu score on bigrams (二元词组),即同时对两个连续单词进行打分. 仍然是上面那个翻译例子:
- French: Le chat est sur le tapis.
- Reference 1: The cat is on the mat.
- Reference 2: There is a cat on the mat.
- MT output: The cat the cat on the mat.
对MT output进行分解,得到的bigrams及其出现在MT output中的次数count为:
- the cat: 2
- cat the: 1
- cat on: 1
- on the: 1
- the mat: 1
然后,统计上述bigrams出现在参考翻译单个语句中的次数(取最大次数)$count_{clip}$为:
- the cat: 1
- cat the: 0
- cat on: 1
- on the: 1
- the mat: 1
相应的bigrams precision为:
$\frac{count_{clip}}{count}=\frac{1+0+1+1+1}{2+1+1+1+1}=\frac46=\frac23$
如果只看单个单词,相应的unigrams precision为:
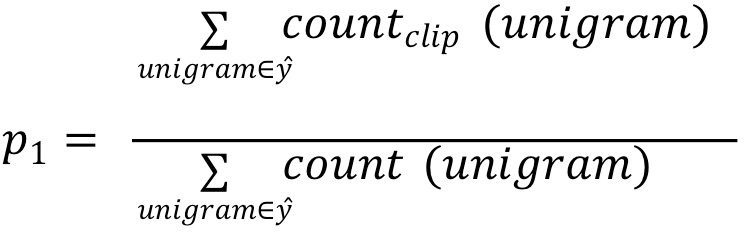
如果是n个连续单词,相应的n-grams precision为:
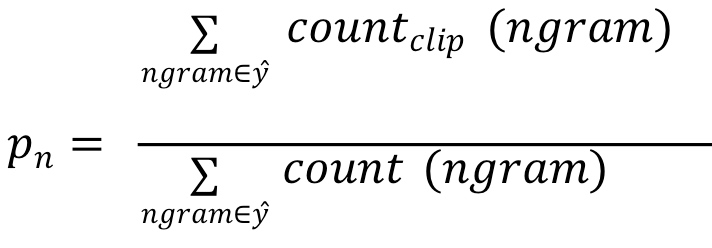

总结一下,可以同时计算$p_1,\cdots,p_n$,再对其求平均:
$p=\frac1n\sum_{i=1}^np_i$
通常,对上式进行指数处理,并引入参数因子brevity penalty, 记为BP. 顾名思义,BP是为了’惩罚’机器翻译语句过短而造成的得分’虚高’的情况.
$p=BP\cdot exp(\frac1n\sum_{i=1}^np_i)$
其中,BP值由机器翻译长度和参考翻译长度共同决定

注意力模型直观理解(Attention Model Intuition)
[Bahdanau et. al., 2014. Neural machine translation by jointly learning to align and translate]
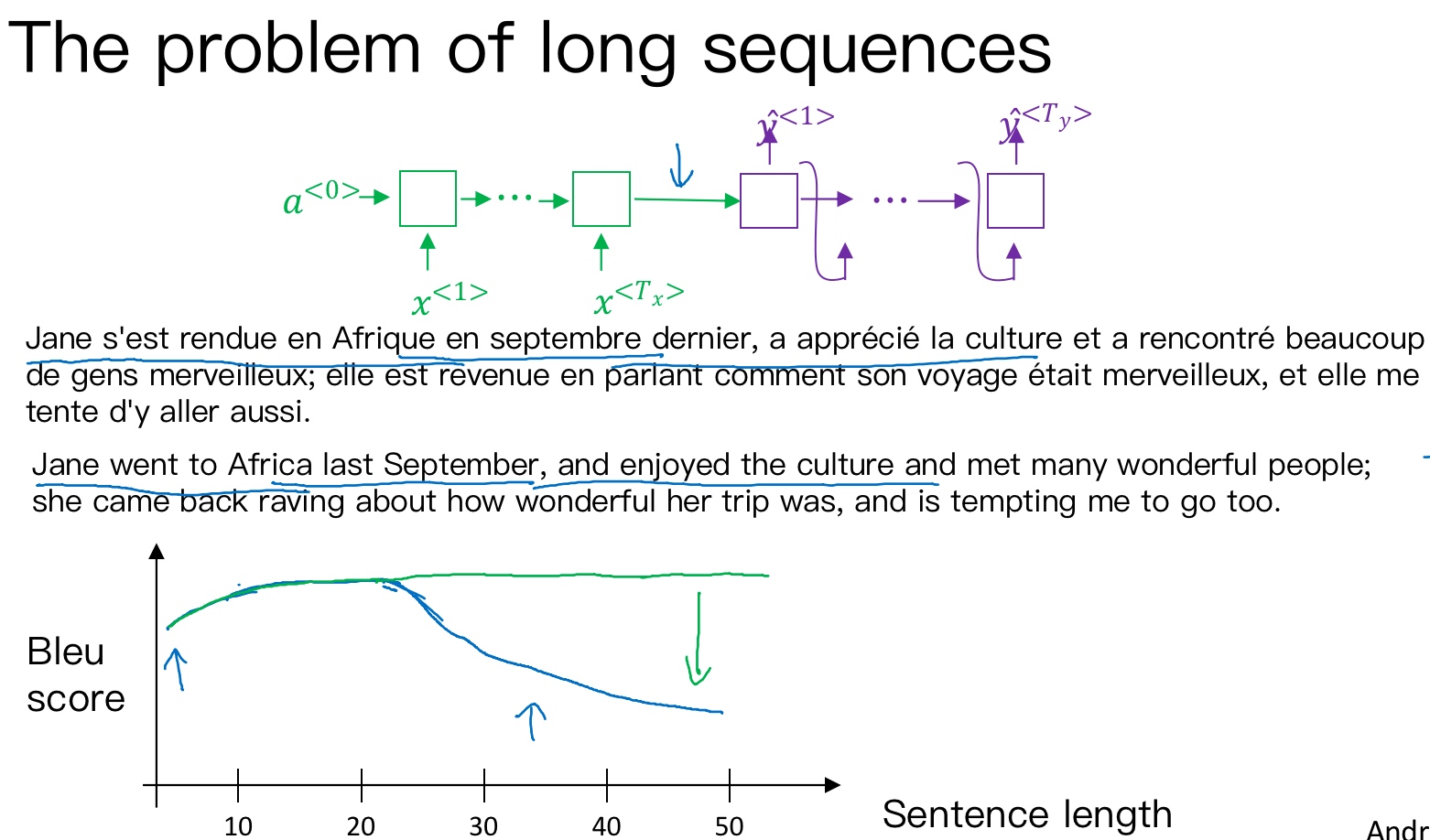
如果原语句很长, 要对整个语句输入RNN的编码网络和解码网络进行翻译, 则效果不佳. 相应的bleu score会随着单词数目增加而逐渐降低(上图蓝线所示).
对待长语句, 正确的翻译方法是将长语句分段, 每次只对长语句的一部分进行翻译. 人工翻译也是采用这样的方法,高效准确. 也就是说, 每次翻译只注重一部分区域, 这种方法使得bleu score不太受语句长度的影响(上图绿线所示).
根据这种’局部聚焦’的思想, 建立相应的注意力模型(attention model).
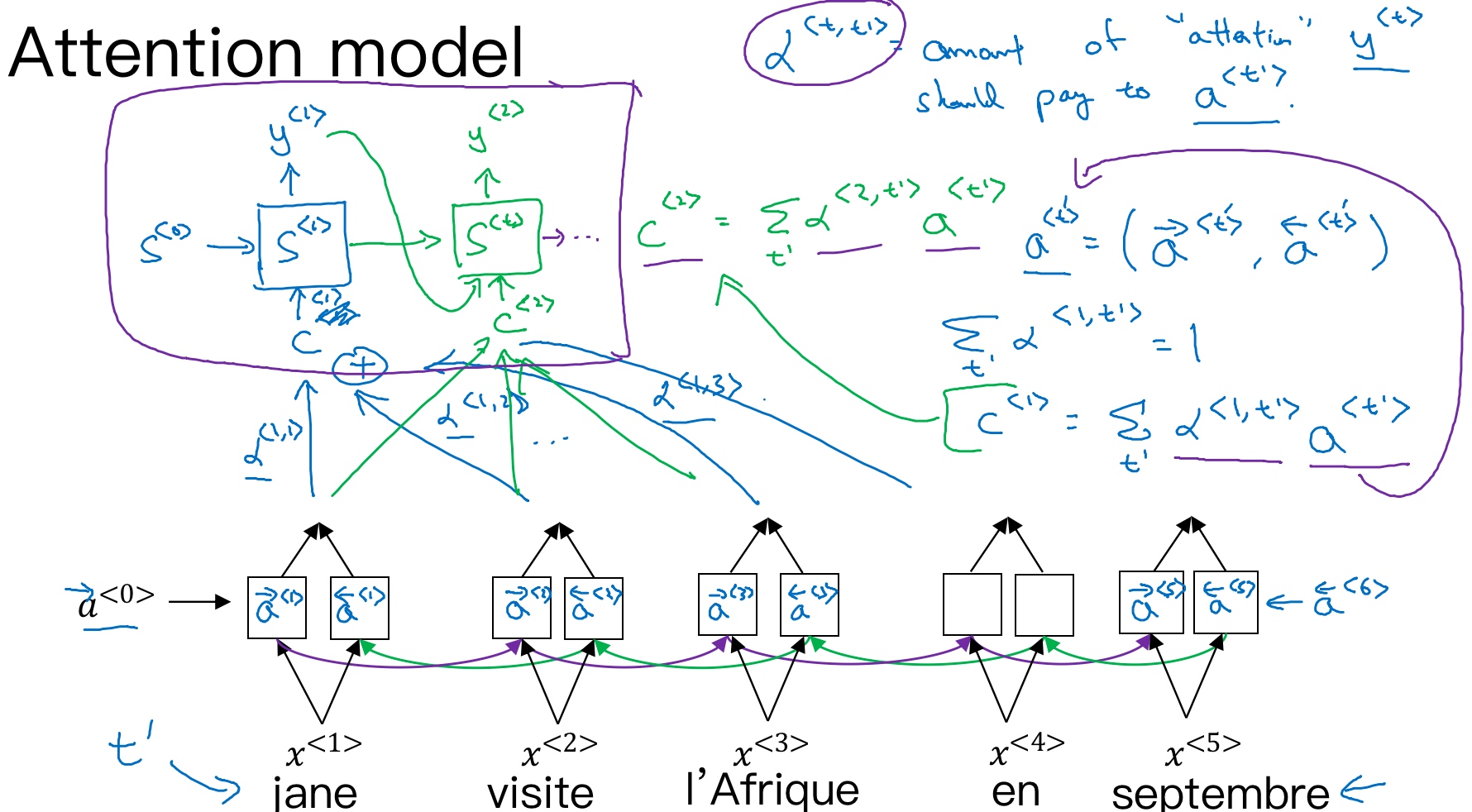
对于法语翻译英语的例子中,针对每个单词的输出,一般来说与某个输出相关的或者有较大影响的单词应该是集中在附近的几个单词或者说是某些部分. 所以注意力模型会在输入的每个输入的信息块上计算注意力权重,不同的权重对每一步的输出结果有不同的注意力影响.
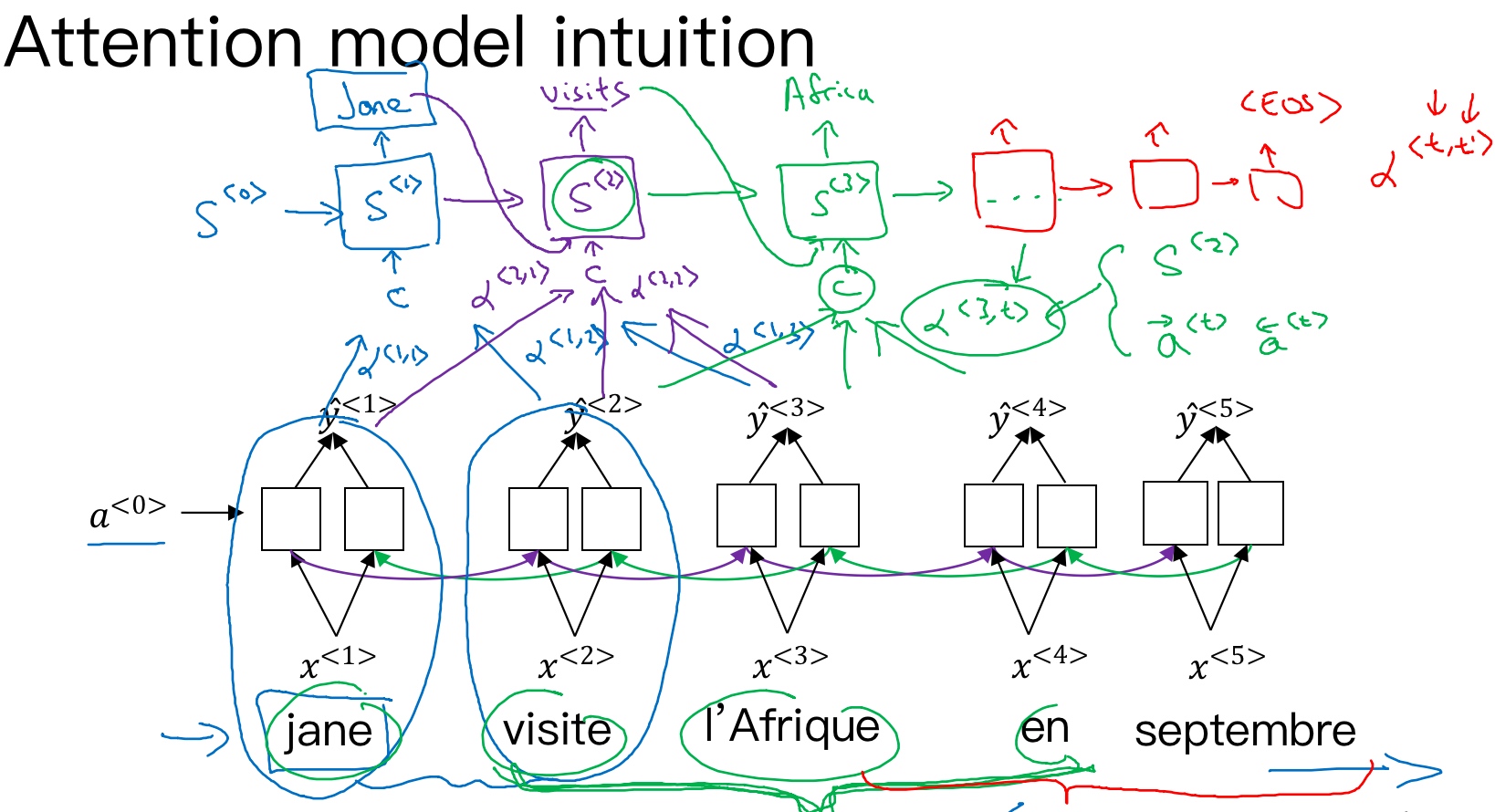
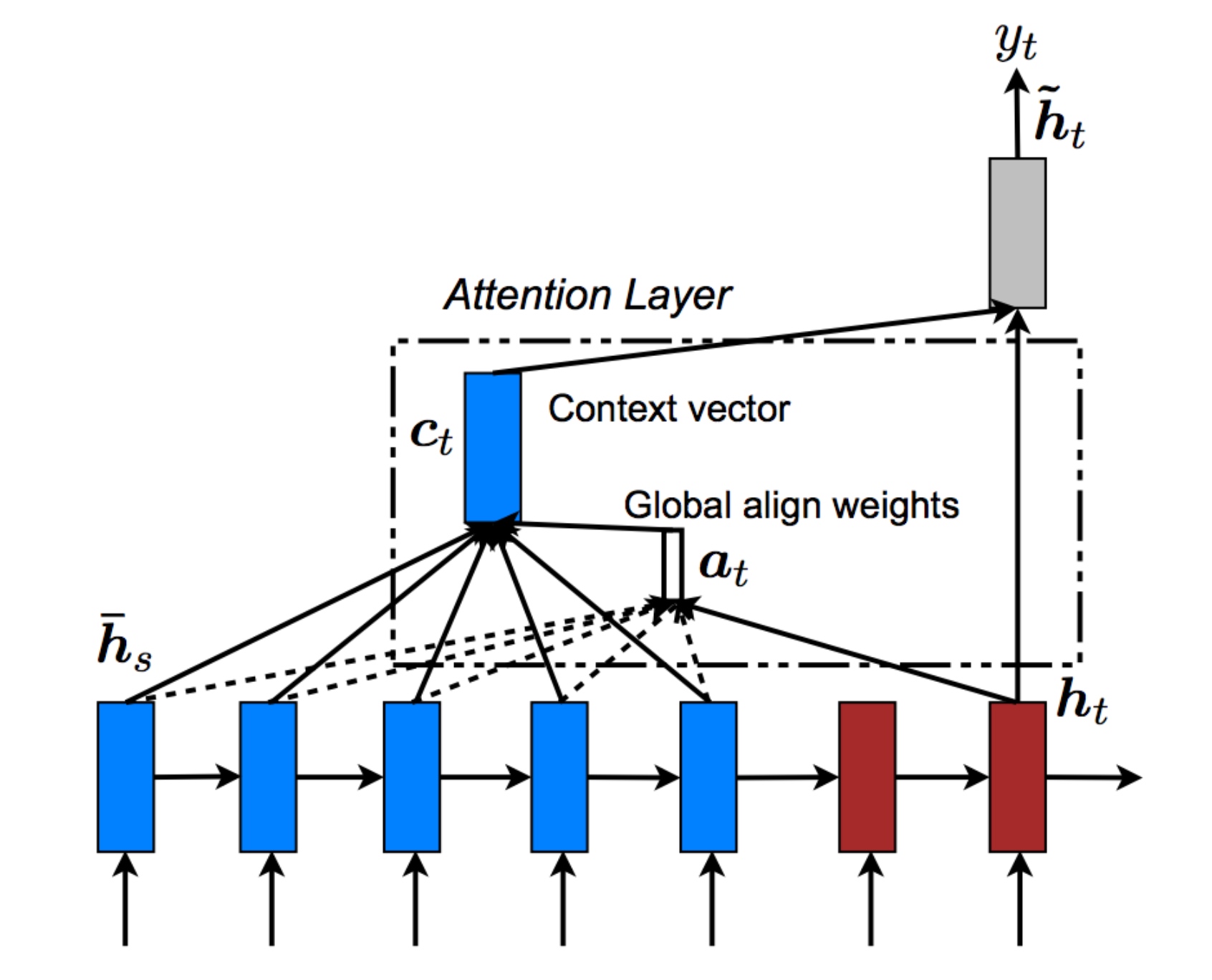
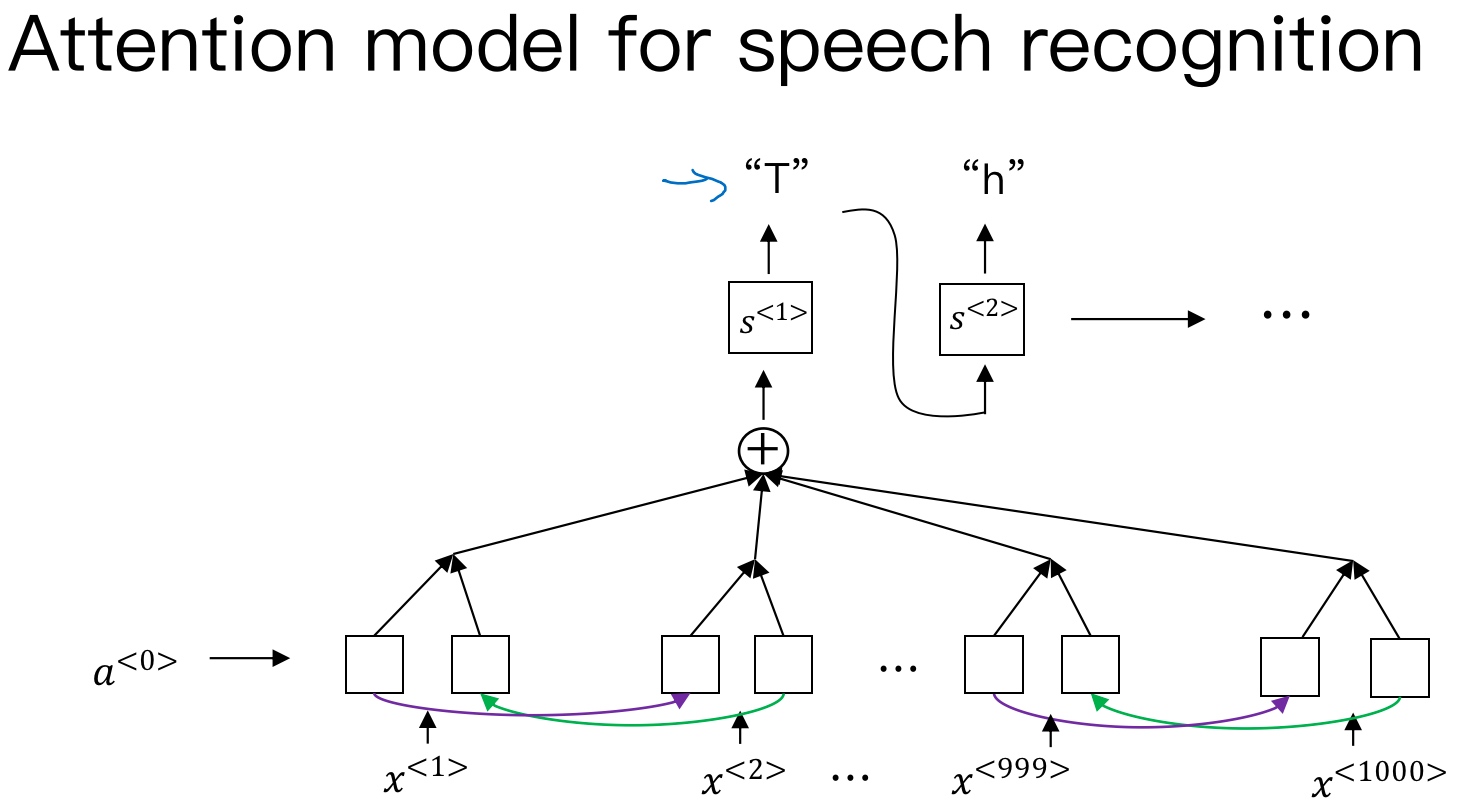
如上图所示,attention model仍由类似的编码网络(下,BRNN) 和解码网络(上)构成. 其中, $s^{<t>}$为RNN(Decoder)的隐藏状态, 由原语句附近单元共同决定, 原则上说, 离得越近, 注意力权重(attention weights)越大, 相当于在你当前的注意力区域(法语)有个滑动窗.
注意力模型会计算注意力权重(a set of attention weights) - $\alpha^{<t,t^{\prime}>}$, 它告诉你,当你尝试生成第$t$个英文词,它应该花多少注意力在第$t’$个法语词上面.
Machine translation
like human, looking at part of the sentence at a time (Bleu score(measure the ability neural network to memorize a long sentence) goes up)
first RNN to compute some set of features for each of the input words
Use another RNN to generate English translation
What the Attention Model would be computing is a set of attention weights
When you generating the first word, how much should you be paying attention to first piece of information. Then second ,third and so on; together these will tell us what is exactly the context from the demoter C that we should be paying attention to, and that is input to Second RNN unit to try to generate the first word. then second input derivie from the same way, together with first generated input to generate the second word.
The amounts that this RNN step should be paying attention to the input at time T that depends on the activations of the bidirectional RNN at time T and it will depend on the state from the previous step
RNN marches forward and generate one word at a time until eventually it generates the EOS. Every steps, there are attention weights that tells it when you are trying to generate the English word(t), how much u should be paying attention to the French word(t`). And this allows it on every time step to look only maybe within a local window of the French sentence to pay attention to when generating a specific English word.
注意力模型(Attention Model)
注意力模型如何让一个神经网络只注意到一部分的输入句子. 当它在生成句子的时候,更像人类翻译.
Attention model中选择双向RNN,可以使用GRU单元或者LSTM. 由于是双向RNN,通过前向和后向的传播,我们可以得到每个时间步的前向和后向的激活值, 用$a^{<t’>}$表示输入句子通过双向RNN(Encoder)得到的每一步的激活值:
$a^{<t’>}=(a^{\rightarrow <t’>},a^{\leftarrow <t’>})$
- 用
$t’$来索引法语句子里面的词
同时,对于英文输出,以另外一个RNN(Decoder)模型来构建,
通过对输入单词的注意力权重$\alpha^{<1, t^{\prime}>}$, 可以得到一个有关输入上下文的加权和$C^{<t>}$. 其中,注意力权重满足条件:
$\sum_{t’}\alpha^{<1, t^{\prime}>}=1$
注意力权重为对于每个输出$y^{<t>}$需要在每个输入单词的激活值$a^{<t′>}$上的关注度,得到相应的上下文C
$C^{<t>}=\sum_{t’}\alpha^{<t, t^{\prime}>} \cdot a^{<t′>}$- 即: Decoder的输入变成不同的上下文C, 且不同上下文C是由输入单词的权重和激活值相乘得来的.
注意力权重的计算:
注意力权重:$\alpha^{<t, t^{\prime}>}$,表示输出$y^{<t>}$需要在每个输出激活值$a^{<t′>}$上付出的注意力大小. 计算注意力权重的公式如下, 为了确保权重和($\alpha$之和)为1,利用softamx思想,引入参数e, 使得:
$\alpha^{<t, t′>}=\frac{exp(e^{<t, t′>})}{\sum_{t’=1}^{Tx}exp(e^{<t, t′>})}$
这样,只要求出e, 就能得到$\alpha$
而其中的$e^{<t,t′>}$则是通过一层神经网络来进行计算得到的,其值取决于输出RNN中前一步的激活值$s^{<t−1>}$以及输入RNN当前步的激活值$a^{<t′>}$
如何求出e呢?可以通过训练这个小的神经网络模型, 使用反向传播算法来学习一个对应的关系函数, 如下图所示. 输入是$s^{<t-1>}$,输出是e.
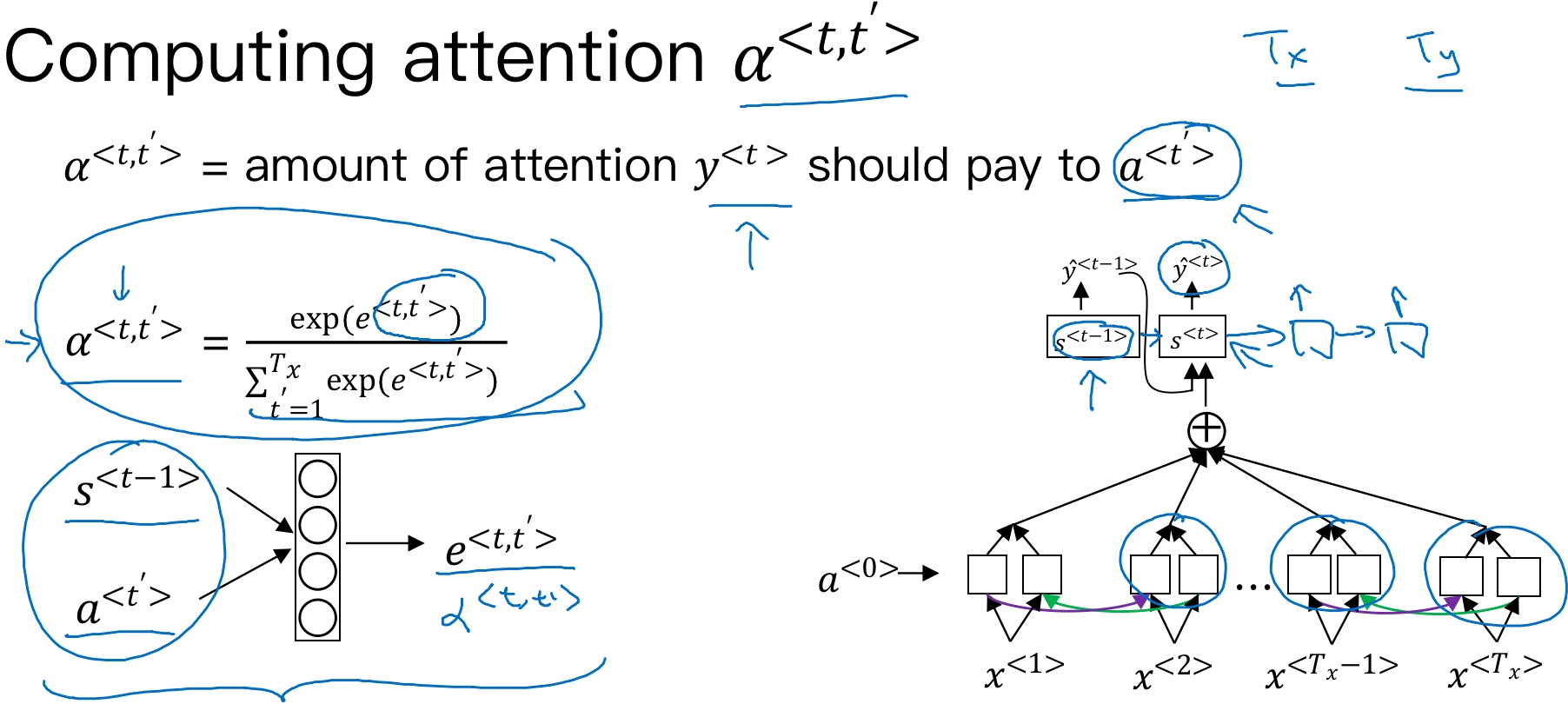
然后,利用梯度下降算法迭代优化,计算得到e 和$\alpha$
Attention model的一个缺点是其计算量较大 (具有$O(T_xT_y)$的复杂度),若输入句子长度为$T_x$, 输出句子长度为$T_y$, 则计算时间约为$T_x*T_y$. 但是,其性能提升很多,输入和输出的句子一般不会太长,这样的复杂度是可以接受的.
注意力的例子:
Attention model在图像捕捉方面也有应用.
Attention model能有效处理很多机器翻译问题,例如:
- 将不标准的时间格式转换为统一的时间格式
- 将注意力权重可视化:
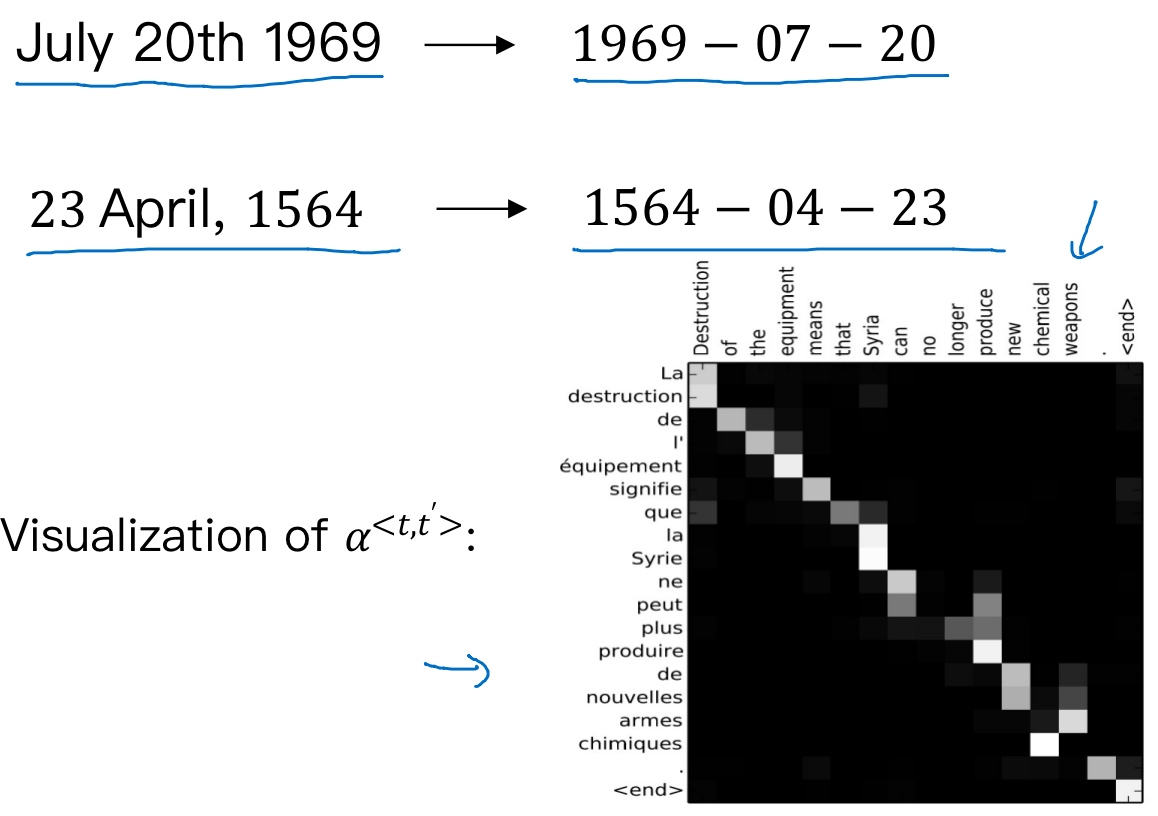
两个日期分别是, 阿波罗登月的日期 和 威廉·莎士比亚的生日
上图中,颜色越白表示注意力权重越大($\alpha$越大), 颜色越深表示权重越小 (这显示了当它生成特定的输出词时通常会花注意力在输入的正确的词上面). 可见,输出语句单词与其输入语句单词对应位置的注意力权重较大,即对角线附近.
attention小结
普通的seq2seq可以是:
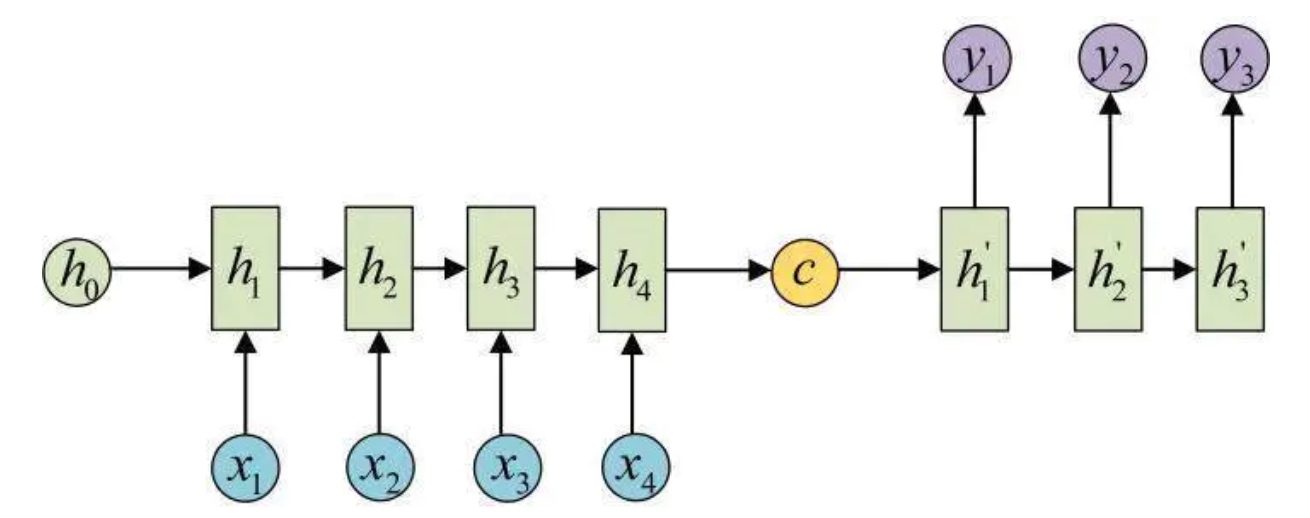
也可以是:
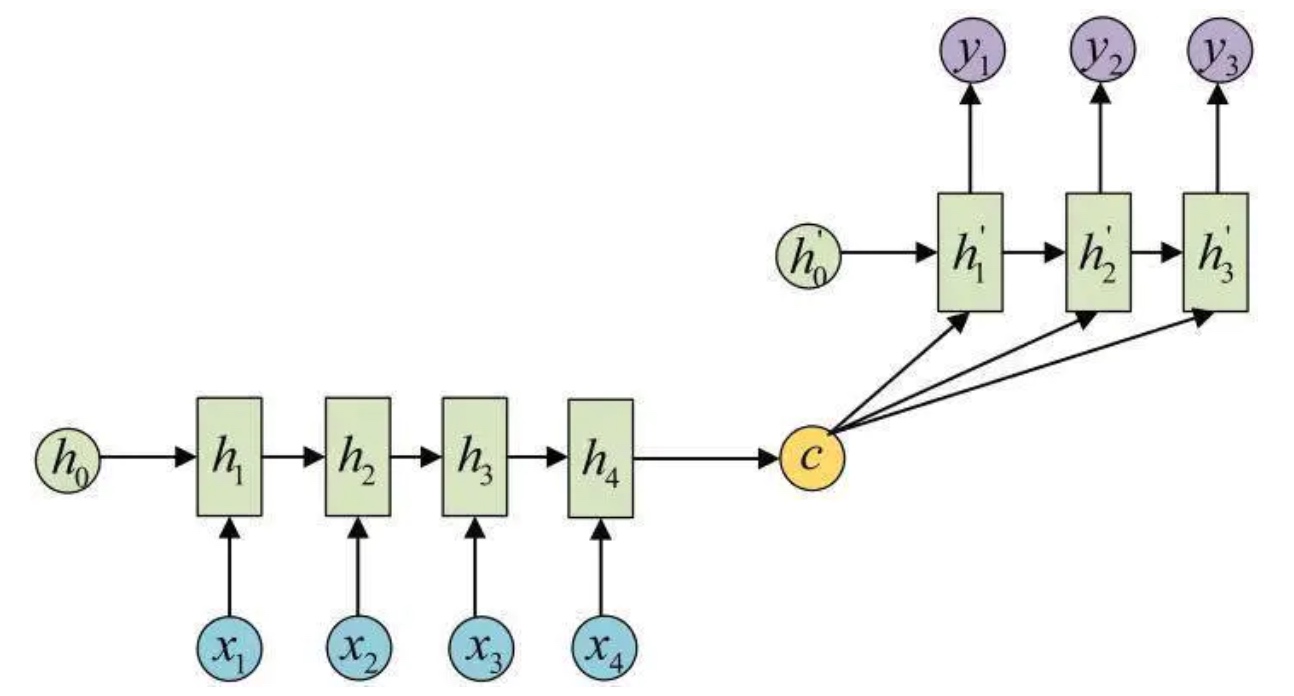
x,y就是输入输出; h就是encoder的隐状态(激活值); h’就是decoder的隐状态(激活值); c就是上下文context. Encoder每个时刻的输入是上一个时刻的隐状态(激活值)和输入(vector),然后会有一个输出(vector)和新的隐状态(激活值). 这个新的隐状态(激活值)会作为下一个时刻的输入隐状态(激活值). 每个时刻都有一个输出(vector),对于seq2seq模型来说,通常只保留最后一个时刻的隐状态(激活值),认为它编码了整个句子的语义 (Attention机制会用到Encoder每个时刻的输出(vector)). 最后, Encoder的输出是一个vector和一个隐状态(激活值). 而得到c有多种方式, 最简单的方法就是把Encoder的最后一个隐状态(激活值)赋值给c,还可以对最后的隐状态(激活值)做一个变换得到c,也可以对所有的隐状态(激活值)做变换. 最后c作为Decoder的初始隐状态.
问题: c是由句子X的每个单词经过Encoder 编码产生的,这意味着不论是生成哪个单词,y1,y2还是y3,其实句子X中任意单词对生成某个目标单词yi来说影响力都是相同的, 没有任何区别.
所以引入注意力机制, 对于生成每个目标单词yi都有一个不同的c (相当于权重), 最终得到下面的模型:
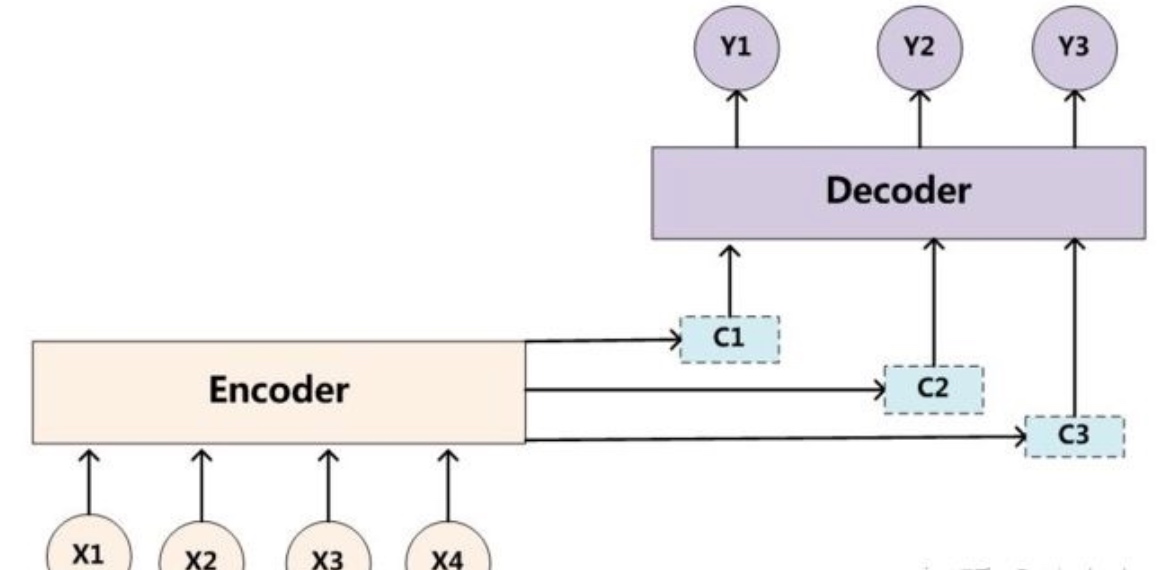
计算ci的过程:
$c_i = \sum_{j=1}^{T_x} \alpha_{ij}h_j$$\alpha_{ij} = \frac{exp(e_{ij})}{\sum_{k=1}^{T_x} exp(e_{ik})}$$e_{ij} = score(h'_{i-1},h_j)$
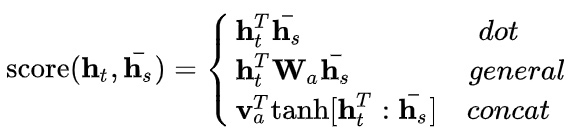
h’就是ht, 就是decoder的隐藏态(激活值); h就是hs, 就是encoder的隐藏态(激活值).
语音识别(Speech recognition)
深度学习中,语音识别的输入是声音,量化成时间序列. 更一般地,可以把信号转化为频域信号,即声谱图(spectrogram), 再进入RNN模型进行语音识别.
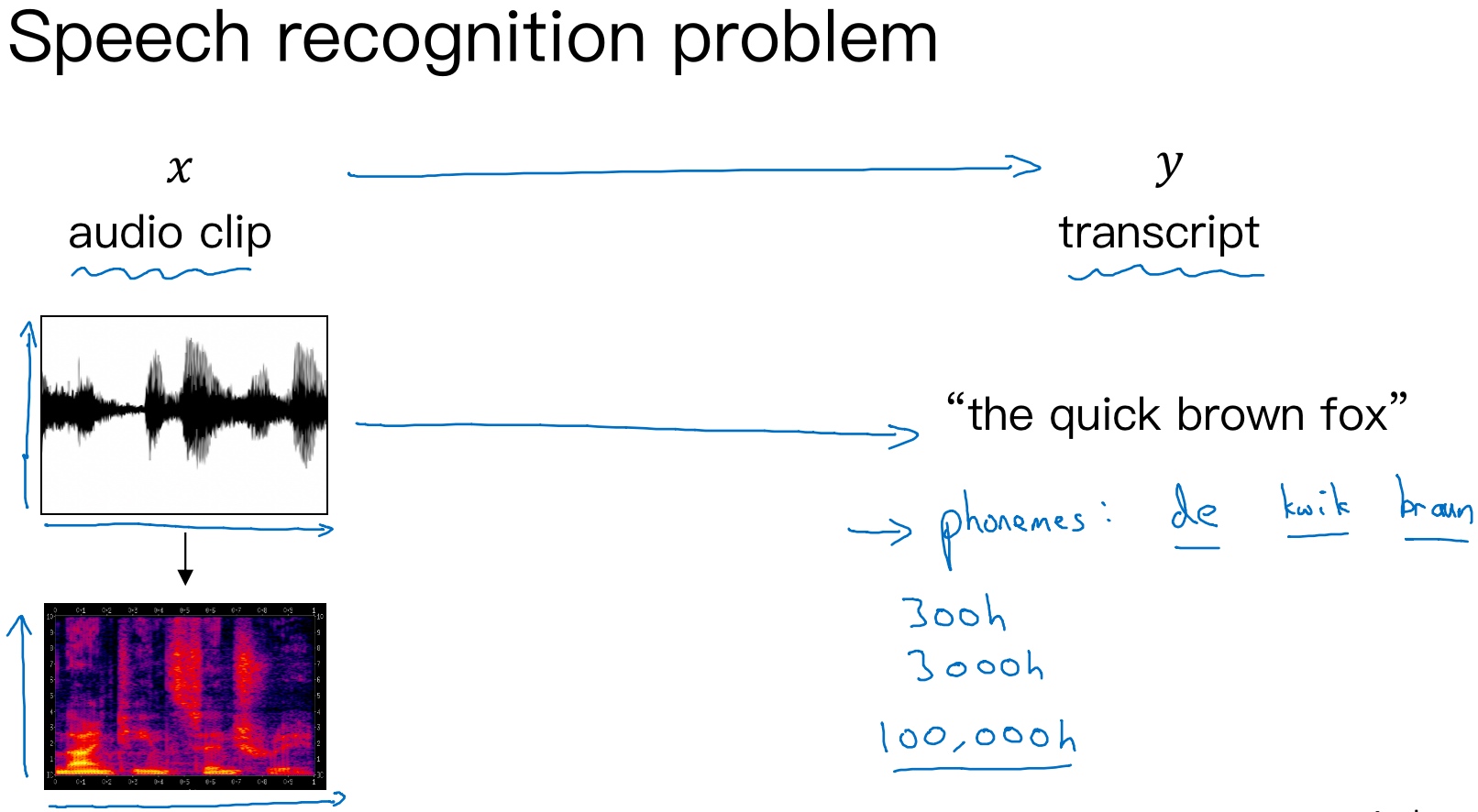
之前,语言学家们会将语音中每个单词分解成多个音素(phoneme), 构建更精准的传统识别算法. 但在end-to-end深度神经网络模型中,一般不需要这么做也能得到很好的识别效果. 通常训练样本很大, 目前的语音识别的应用中,常见的语音数据大小为300h、3000h,而在一些大型的更加精确的语音系统中,已经应用了上万小时的语音数据.
语音识别的注意力模型(attention model)如下图所示:
CTC 损失函数的语音识别:
[Graves et al., 2006. Connectionist Temporal Classification: Labeling unsegmented sequence data with recurrent neural networks]
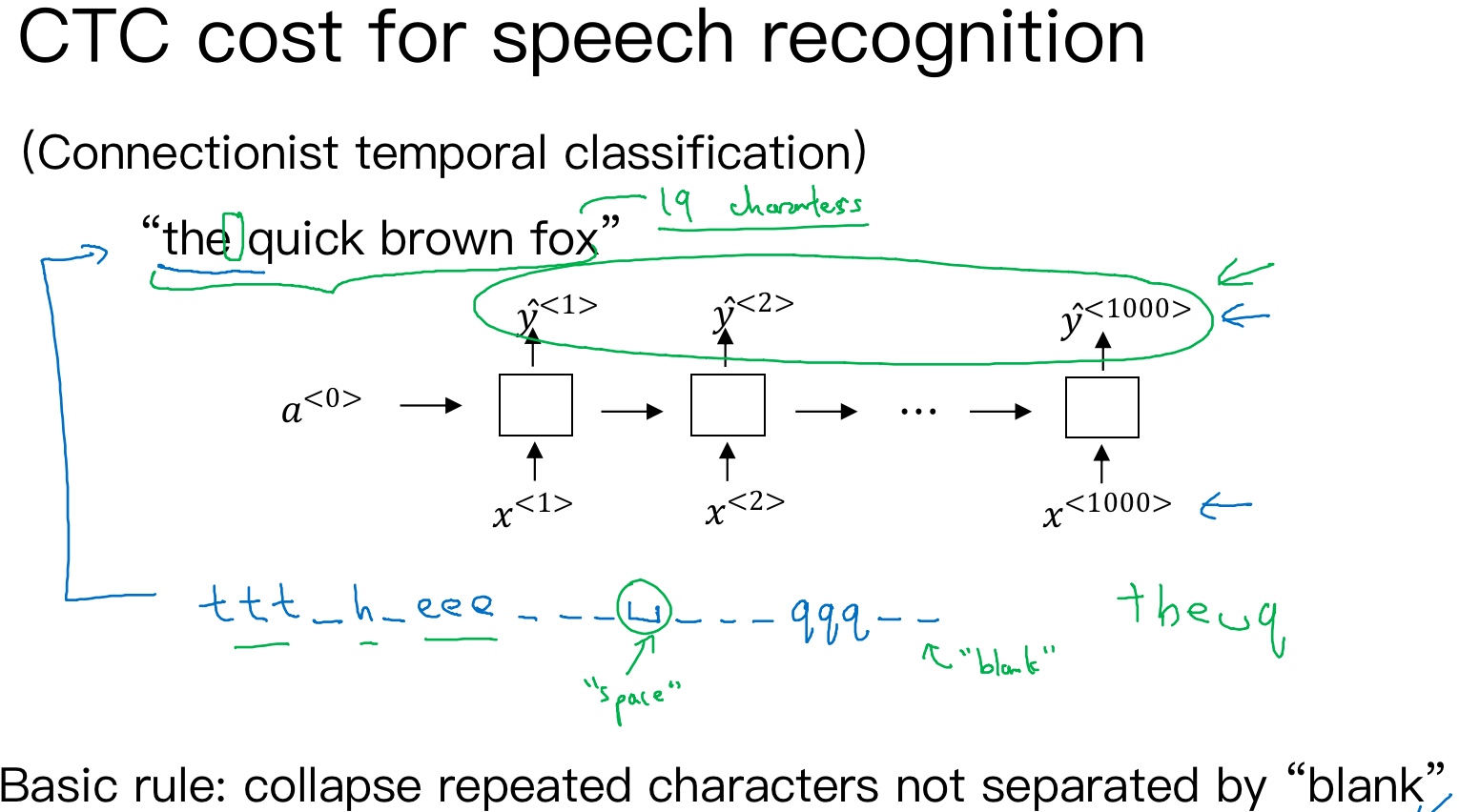
一般来说,语音识别的输入时间序列都比较长,例如是10s语音信号,采样率为100Hz,则语音长度为1000. 而翻译的语句通常很短,例如“the quick brown fox”,包含19个字符. 这时候,$T_x$与$T_y$ 差别很大. 为了让$T_x=T_y$, 可以把输出相应字符重复并加入空白(blank), 形如:

其中,下划线’‘表示空白, ‘$\sqcup$‘表示两个单词之间的空字符. 这种写法的一个基本准则是没有被空白符’‘分割的重复字符将被折叠到一起,即表示一个字符.
这样,加入了重复字符和空白符、空字符, 可以让输出长度也达到1000, 即$T_x=T_y$. 这种模型被称为CTC(Connectionist temporal classification)
触发字检测(Trigger Word Detection)
触发字检测(Trigger Word Detection)在很多产品中都有应用,操作方法就是说出触发字通过语音来启动相应的设备. 例如Amazon Echo的触发字是”Alexa“,百度DuerOS的触发字是”小度你好“,Apple Siri的触发字是”Hey Siri“,Google Home的触发字是”Okay Google“.

触发字检测系统可以使用RNN模型来建立. 如下图所示,输入语音中包含一些触发字,其余都是非触发字. RNN检测到触发字后输出1,非触发字输出0. 这样训练的RNN模型就能实现触发字检测.
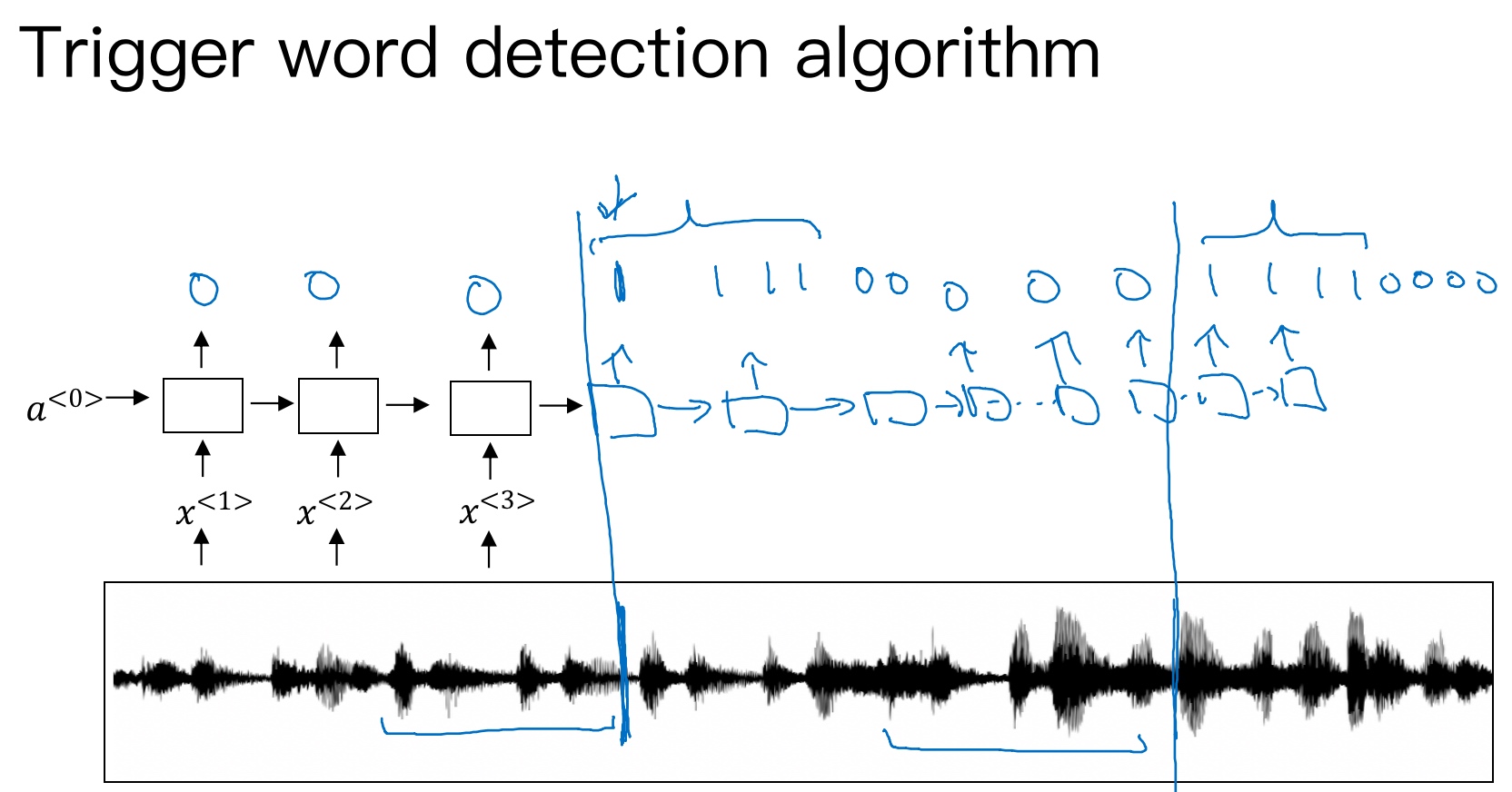
但是这种模型有一个缺点,就是通常训练样本语音中的触发字较非触发字数目少得多,即正负样本分布不均. 一种解决办法是在出现一个触发字时,将其附近的RNN都输出1. 这样就简单粗暴地增加了正样本, 在一定程度上可以提高系统的精确度
ref: