11. Object detection
目标定位(Object localization)
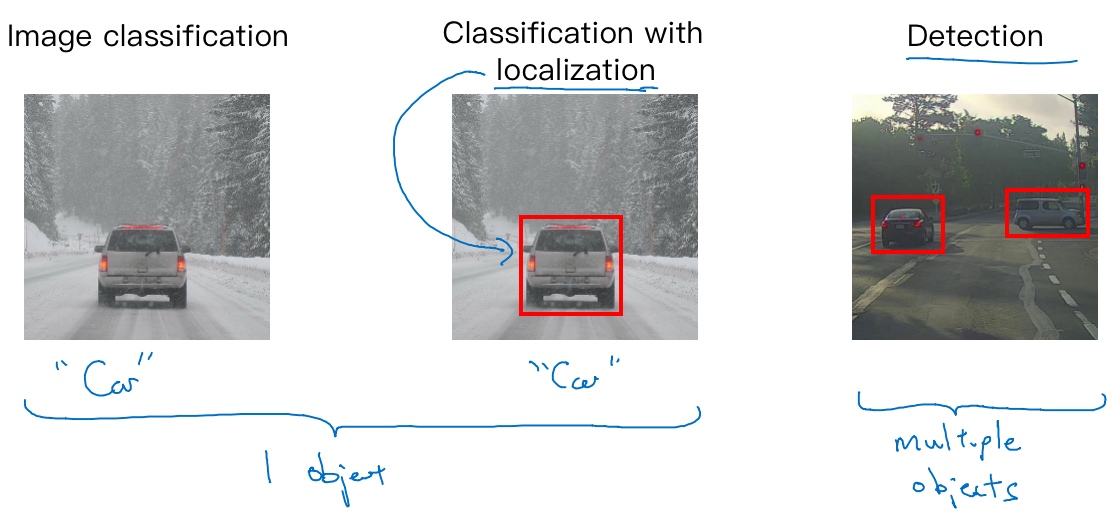
从左到右依次是,
- 图像分类,
- 图像定位分类(除了判断是否是车, 还要标记出其位置, 用红色框圈起),
- 检测 (检测多个目标和位置)
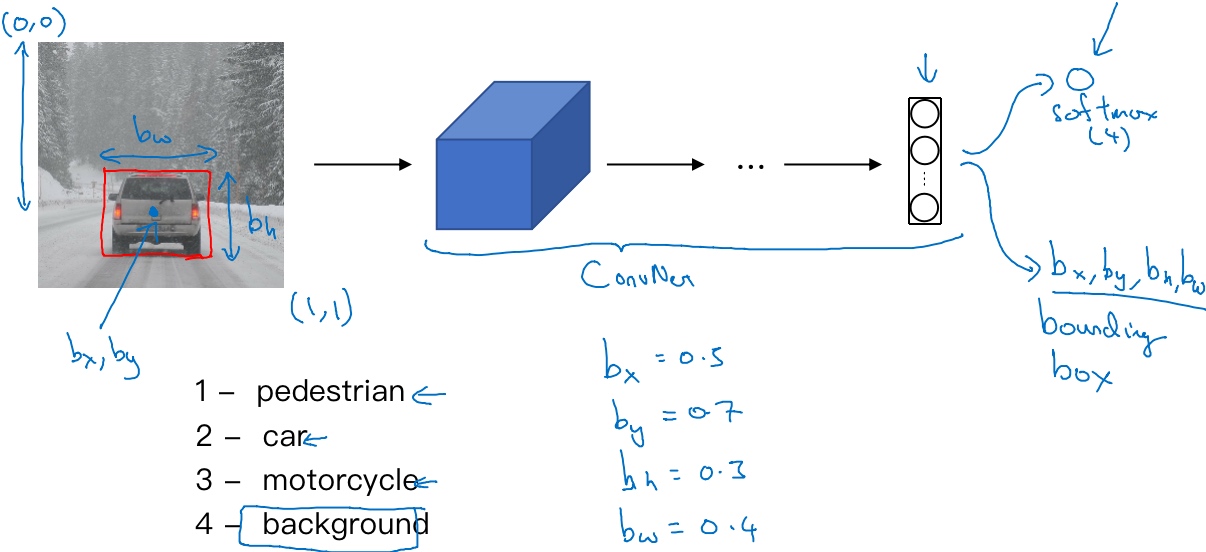
假设构建一个汽车自动驾驶系统, 那么对象可能包括以下几类:行人、汽车、摩托车和背景(如果没有检测到前三个, 输出的结果就是背景).
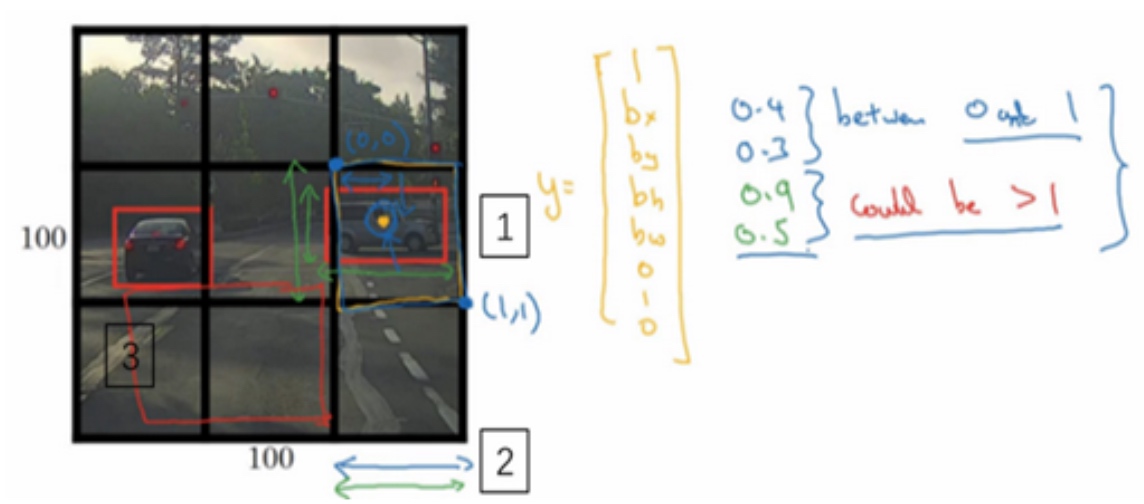
为了定位图片中汽车的位置, 让神经网络多输出几个单元, 输出一个边界框, 标记为$b_x, b_y, b_h, b_w$, 这4个数字是被检测对象的边界框的参数化表示.
($b_x, b_y$)表示红色框的中心点
($b_h, b_w$)分别表示红色框的高度和宽度
例子:
图中红色框住的汽车,
$b_x$的理想值是0.5, 表示汽车位于图片水平方向的中间位置;
$b_y$是0.7, 表示车位于距离图片底部3/10的位置;
$b_h$是0.3, 红色方框的高度是图片高度的0.3倍
$b_w$是0.4, 红色方框的宽度是图片高度的0.4倍
目标标签$y = \begin{bmatrix} P_c \\ b_x \\ b_y \\ b_h \\ b_w \\ C_1 \\ C_2 \\ C_3 \end{bmatrix}$
$P_c$表示分类标签出现的概率(被检测对象属于某一分类的概率,背景分类除外). 是否含有对象, 如果对象属于前三类(行人、汽车、摩托车), 则$P_c = 1$, 如果是背景,$P_c = 0$- 如果检测到对象,就输出被检测对象的边界框参数
$b_x, b_y, b_h, b_w$. - 如果存在对象, 则
$P_c = 1$, 同时输出$C_1 ,C_2, C_3$, 表示该对象属于行人、汽车、摩托车其中一类.
检测到汽车$y = \begin{bmatrix} 1 \\ b_x \\ b_y \\ b_h \\ b_w \\ 0 \\ 1 \\ 0 \end{bmatrix}$
检测到背景$y = \begin{bmatrix} 0 \\ ? \\ ? \\ ? \\ ? \\ ? \\ ? \\ ? \end{bmatrix}$, y的其它参数将变得毫无意义, 全部无需考虑
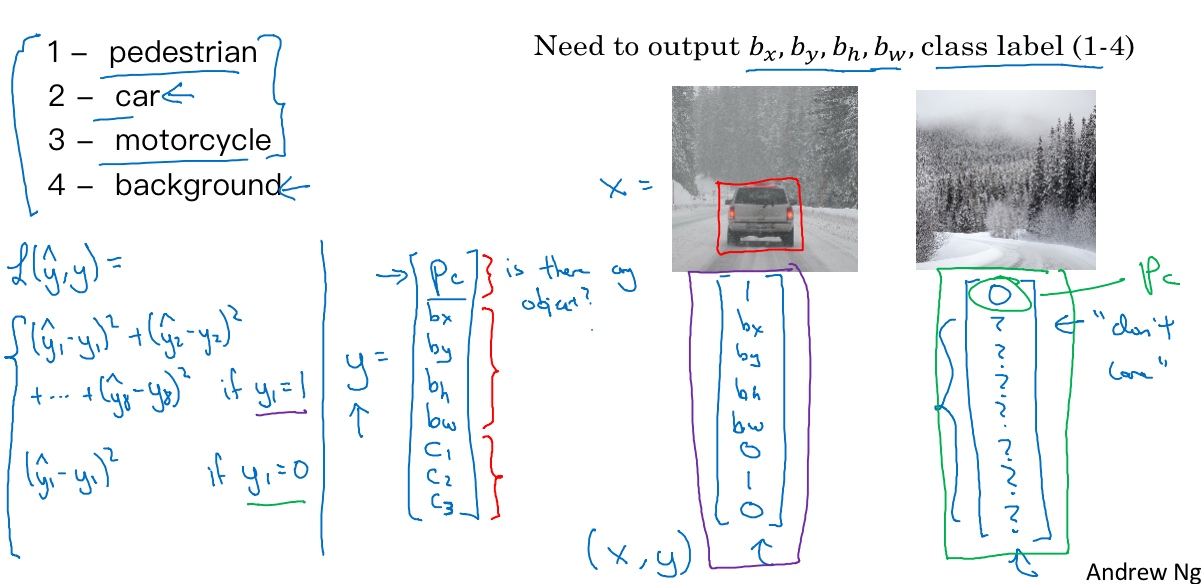
神经网络的损失函数, 如果采用平方误差策略, 则
- if
$y = P_c = 1$,$L(\tilde{y},y) = (\tilde{y}_1 - y_1)^2 + (\tilde{y}_2 - y_2)^2 + ... + (\tilde{y}_8 - y_8)^2$ - if
$y = P_c = 0$,$L(\tilde{y},y) = (\tilde{y}_1 - y_1)^2$
特征点检测(Landmark detection)
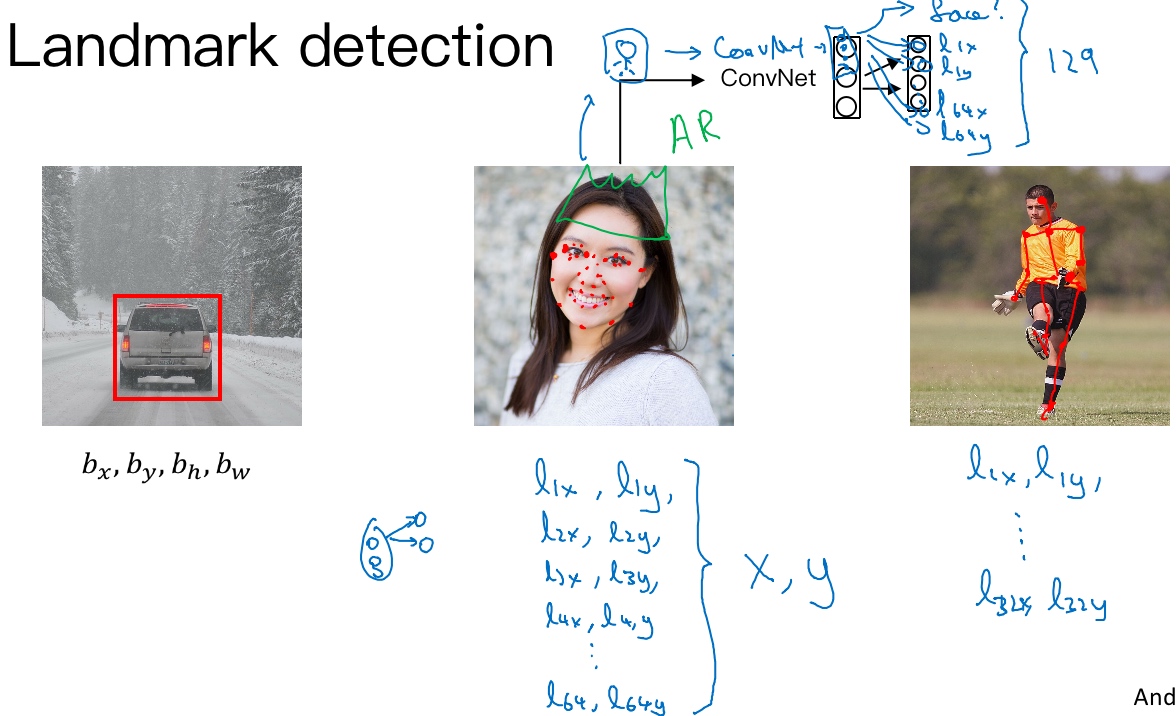
选定特征点个数(一个点代表一个特征在图片的坐标),并生成包含这些特征点的标签训练集,然后利用神经网络输出脸部关键特征点的位置.
具体做法是,准备一个卷积网络和一些特征集,将人脸图片输入卷积网络,
- 假设脸部有64个特征点
- 输出1或0,1表示有人脸,0表示没有人脸
- 然后输出(
$l_{1x},l_{1y}$)……直到($l_{64x},l_{64y}$). 这里用$l$代表一个特征(landmark) - 这里有129个输出单元,其中1表示图片中有人脸,因为有64个特征,64×2=128,所以最终输出128+1=129个单元
Snapchat过滤器实现了在脸上画皇冠和其他一些特殊效果, 检测脸部特征也是计算机图形效果的一个关键构造模块. 为了构建这样的网络,你需要准备一个标签训练集,也就是图片x和标签y的集合,这些点都是人为辛苦标注的
另一例子:
人体姿态检测, 定义一些关键特征点,如胸部的中点,左肩,左肘,腰等等。然后通过神经网络标注人物姿态的关键特征点,再输出这些标注过的特征点,就相当于输出了人物的姿态动作.
注意: 特征点的特性在所有图片中必须保持一致(标签在所有图片中必须保持一致); 假如你雇用他人或自己标记了一个足够大的数据集,那么神经网络便可以输出上述所有特征点,你可以利用它们实现其他有趣的效果,比如判断人物的动作姿态,识别图片中的人物表情等等
目标检测(Object detection)
通过卷积网络进行对象检测,采用的是基于滑动窗口的目标检测算法
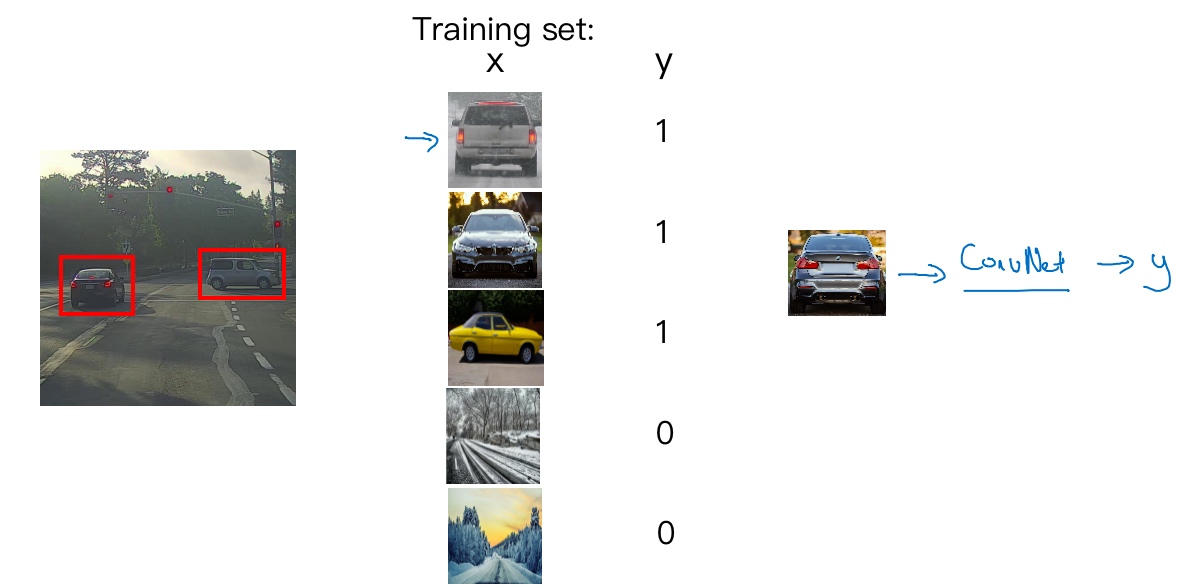
假如构建一个汽车检测算法,
- 创建一个标签训练集,也就是x和y表示适当剪切的汽车图片(整张图片几乎都被汽车占据, 汽车居于中间位置)样本(有汽车标记为1, 没汽车为0)
- 有了这个标签训练集,就可以开始训练卷积网络了,输入这些适当剪切过的图片, 卷积网络输出,0或1表示图片中有汽车或没有汽车
- 训练完这个卷积网络,就可以用它来实现滑动窗口目标检测

假设这是一张测试图片,首先选定一个特定大小的窗口,比如图片下方这个窗口,将这个红色小方块输入卷积神经网络,卷积网络开始进行预测,即判断红色方框内有没有汽车.

接下来继续处理第二个图像,即红色方框稍向右滑动之后的区域,并输入给卷积网络(只有红色方框内的区域),再次运行卷积网络,然后处理第三个图像,依次重复操作,直到这个窗口滑过图像的每一个角落

重复上述操作,不过选择一个更大的窗口,截取更大的区域,并输入给卷积神经网络处理,你可以根据卷积网络对输入大小调整这个区域,然后输入给卷积网络,输出0或1.

然后第三次重复操作,这次选用更大的窗口
这样做,不论汽车在图片的什么位置,总有一个窗口可以检测到它
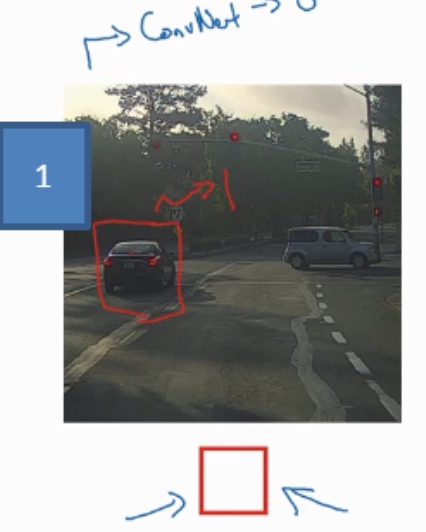
卷积网络对该输入区域的输出结果为1,说明网络检测到图上有辆车
滑动窗口目标检测算法缺点 - 计算成本
- 在图片中剪切出太多小方块,卷积网络要一个个地处理。如果选用的步幅很大,显然会减少输入卷积网络的窗口个数,但是粗糙间隔尺寸可能会影响性能。
- 反之,如果采用小粒度或小步幅,传递给卷积网络的小窗口会特别多,这意味着超高的计算成本
Use big stride, reduce number of windows you need to pass through the ConvNet, but it coarser granularity may hurt performance. Otherwise, there is high computational cost
在神经网络兴起之前,人们通常采用更简单的分类器进行对象检测,比如通过采用手工处理工程特征的简单的线性分类器来执行对象检测。至于误差,因为每个分类器的计算成本都很低,它只是一个线性函数,所以滑动窗口目标检测算法表现良好,是个不错的算法。然而,卷积网络运行单个分类人物的成本却高得多,像这样滑动窗口太慢。除非采用超细粒度或极小步幅,否则无法准确定位图片中的对象。
滑动窗口的卷积实现(Convolutional implementation of sliding windows)
提高卷积层上应用滑动窗口目标检测器的效率
首先要知道如何把神经网络的全连接层转化成卷积层 (Turning FC layer into convolutional layer)
参考论文:Sermanet, Pierre, et al. “OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks.” Eprint Arxiv (2013).

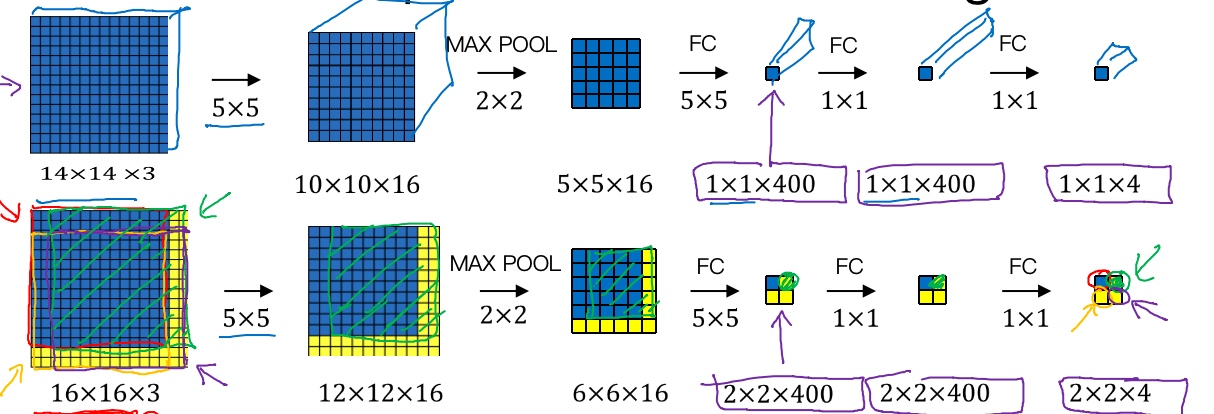
Original FC:
- 假设对象检测算法输入一个14×14×3的图像,过滤器大小为5×5,数量是16,14×14×3的图像在过滤器处理之后映射为10×10×16.
- 然后通过参数为2×2的最大池化操作,图像减小到5×5×16。
- 然后添加一个连接400个单元的全连接层,
- 接着再添加一个400的全连接层,
- 最后通过softmax单元输出y, 为4个分类出现的概率.
Convolutional FC:
- 卷积网络的前几层和之前的一样,
- 而对于下一层,也就是全连接层,可以用400个5×5的过滤器来实现(编号1所示), 输入图像大小为5×5×16,用5×5的过滤器对它进行卷积操作,过滤器实际上是5×5×16,因为在卷积过程中,过滤器会遍历这16个通道,所以这两处的通道数量必须保持一致,输出结果为1×1。应用400个这样的5×5×16过滤器,输出维度就是1×1×400,我们不再把它看作一个含有400个节点的集合,而是一个1×1×400的输出层。
- 从数学角度看,它和全连接层是一样的,因为这400个节点中每个节点都有一个5×5×16维度的过滤器,所以每个值都是上一层这些5×5×16激活值经过某个任意线性函数的输出结果。
- 再添加另外一个卷积层(编号2所示),这里用的是1×1卷积,假设有400个1×1的过滤器,在这400个过滤器的作用下,下一层的维度是1×1×400,它其实就是上个网络中的全连接层。
- 最后经由1×1过滤器的处理,得到一个softmax激活值,通过卷积网络,最终得到这个1×1×4的输出层(编号3所示).
通过卷积实现滑动窗口对象检测算法
[Sermanet et al., 2014, OverFeat: Integrated recognition, localization and detection using convolutional networks]
假设输入给卷积网络的图片大小是14×14×3,测试集图片是16×16×3,现在给这个输入图片加上黄色条块, 根据滑动窗口算法, 步幅为2, 从左到右从上到下依次滑动得到红, 绿, 橙, 紫框, 没得到一个框就输入一个颜色区域给卷积网络,卷积后得到一个0或1标签. 由于在这个16×16×3的小图像上滑动窗口,卷积网络运行了4次,于是输出了了4个标签.
结果发现,这4次卷积操作中很多计算都是重复的。所以执行滑动窗口的卷积时使得卷积网络在这4次前向传播过程中共享很多计算,例如第一步操作中, 卷积网络运行同样的参数,使得相同的5×5×16过滤器进行卷积操作,得到12×12×16的输出层, 后面类似.
所以该卷积操作的原理是我们不需要把输入图像分割成四个子集,分别执行前向传播,而是把它们作为一张图片输入给卷积网络进行计算,其中的公共区域可以共享很多计算.

假如对一个28×28×3的图片应用滑动窗口操作,如果以同样的方式运行前向传播,最后得到8×8×4的结果。跟上一个范例一样,以14×14区域滑动窗口,首先在这个区域应用滑动窗口,其结果对应输出层的左上角部分。接着以大小为2的步幅不断地向右移动窗口,直到第8个单元格,得到输出层的第一行。然后向图片下方移动,最终输出这个8×8×4的结果。因为最大池化参数为2,相当于以大小为2的步幅在原始图片上应用神经网络。
Convolution implementation of sliding windows
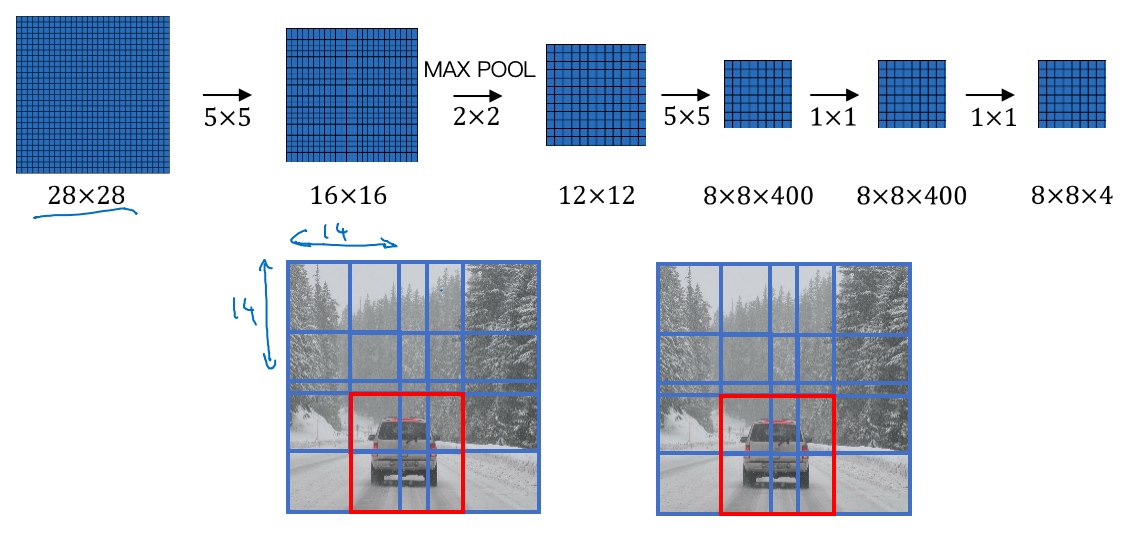
滑动窗口的实现过程,在图片上剪切出一块区域,假设它的大小是14×14,把它输入到卷积网络。继续输入下一块区域,大小同样是14×14,重复操作,直到某个区域识别到汽车.
Bounding Box预测(Bounding box predictions)
[Redmon, Joseph, et al. “You Only Look Once: Unified, Real-Time Object Detection.” (2015):779-788.]
使用Bounding Box可以得到更精准的边界框

在滑动窗口法中, 这些边界框没有一个能完美匹配汽车位置
其中一个能得到更精准边界框的算法是YOLO算法, YOLO(You only look once). 其最大优的点是速度极快, 可以达到实时识别, 也能够理解一般的对象表示.
- 首先,输入图像:

- 然后,YOLO将输入图像划分为网格形式(例如3 X 3):
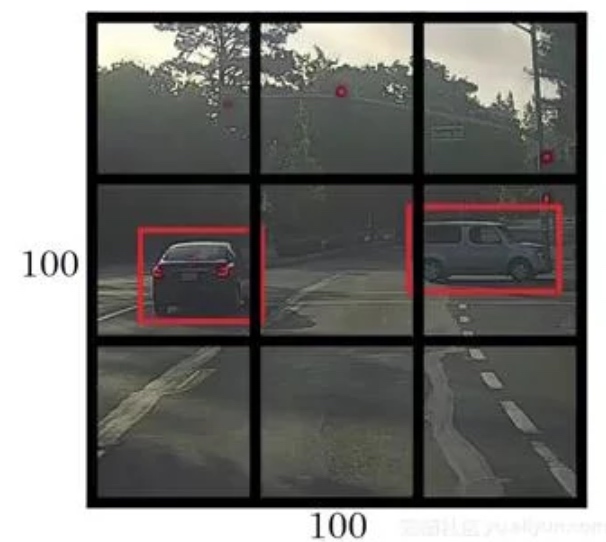
- 最后,对每个网格应用图像分类和定位处理,获得预测对象的边界框及其对应的类概率
具体来看:
输入图像是100×100的, 在图像上放一个3×3网格 (实际上可能是19x19)
基本思路是使用图像分类和定位算法, 将算法应用到9个格子上.
y是8维的, $y = \begin{bmatrix} P_c \\ b_x \\ b_y \\ b_h \\ b_w \\ c_1 \\ c_2 \\ c_3 \end{bmatrix}$
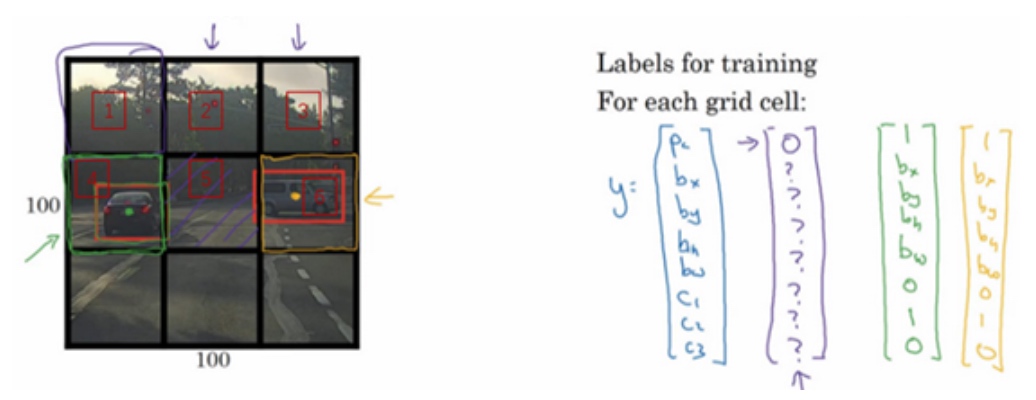
- Pc定义对象是否存在于网格中(存在的概率);
- bx、by、bh、bw指定边界框;
- c1、c2、c3代表类别。如果检测对象是汽车,则c2位置处的值将为1,c1和c3处的值将为0;
图中有两个物体(两辆车), YOLO算法做的就是,取两个物体的中点中心点,然后将物体分配给包含对物体中点的格子, $y = \begin{bmatrix} 1 \\ b_x \\ b_y \\ b_h \\ b_w \\ c_1 \\ 1 \\ c_3 \end{bmatrix}$
对于9个网格中的每一个单元格,都具有八维输出向量, 这里是3×3的网格(9个格子), 最终的输出形状为3X3X8.
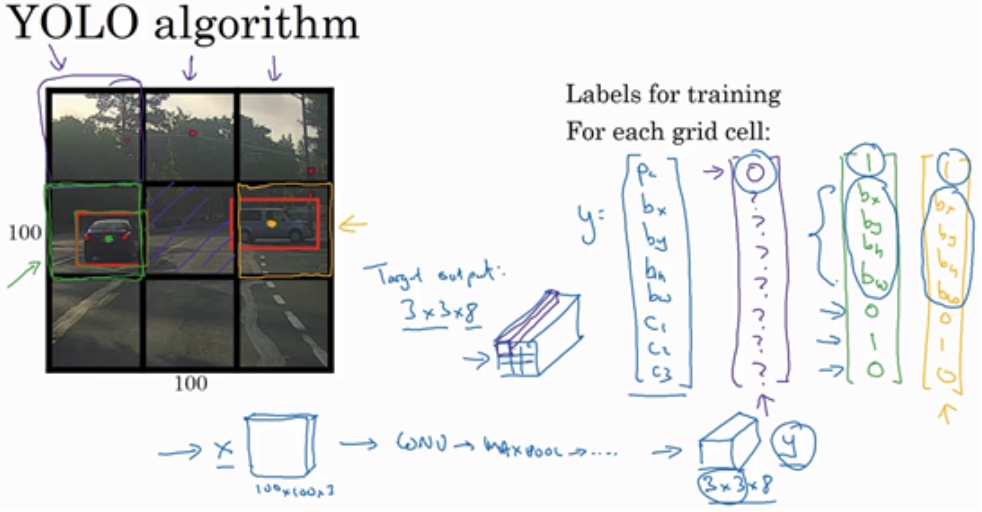
使用上面的例子(输入图像:100X100X3,输出:3X3X8),模型将按如下方式进行训练:
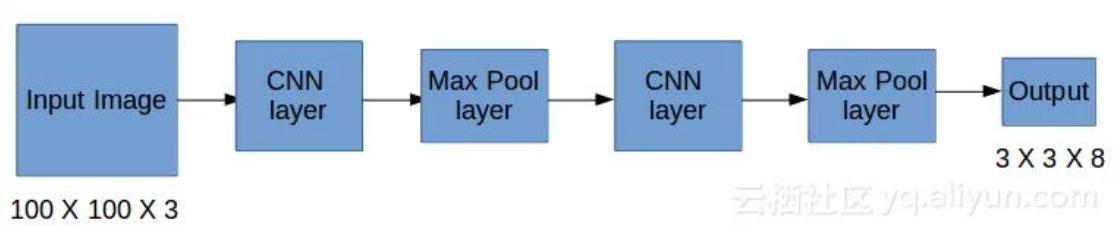
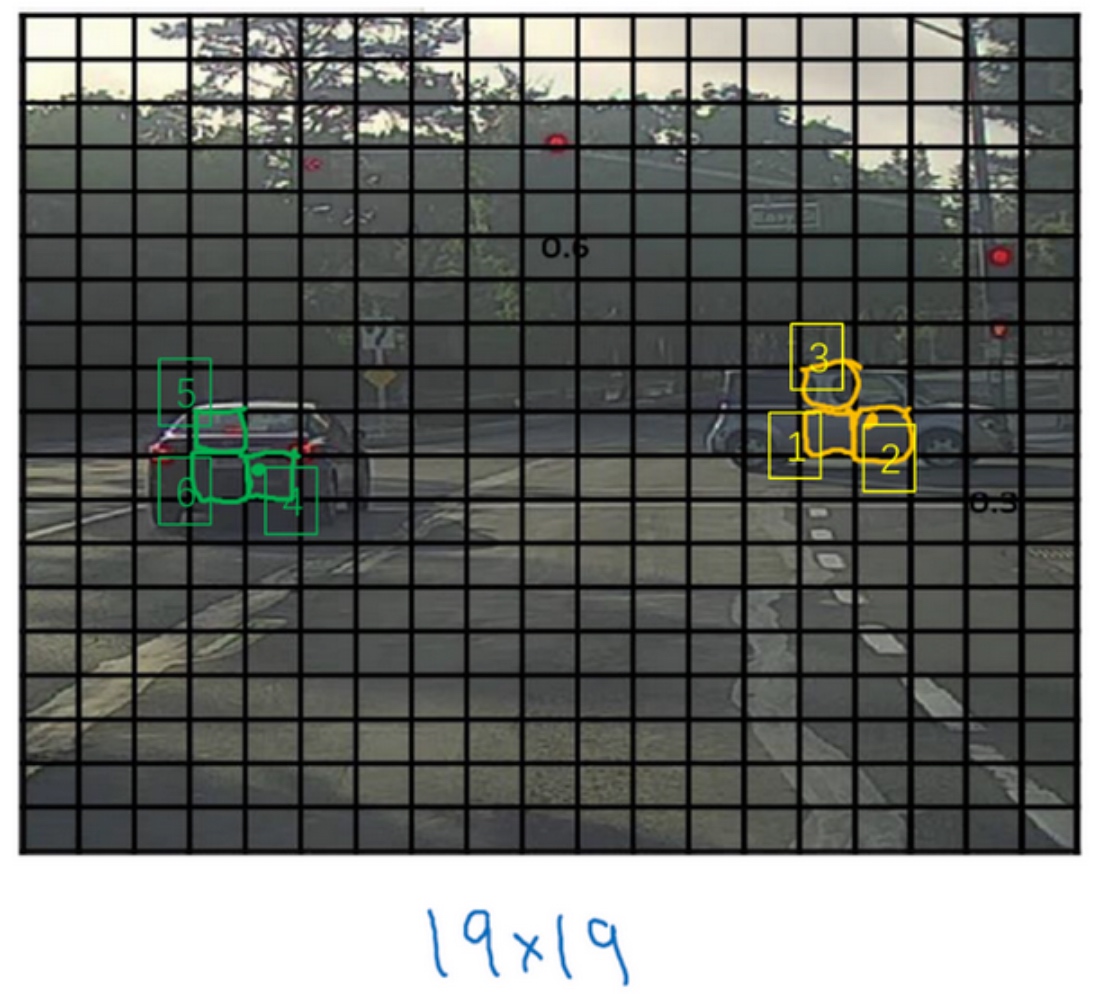
使用经典的CNN网络构建模型,并用反向传播进行模型训练. YOLO算法的优点在于神经网络可以输出精确的边界框, 所以在测试阶段,将图像传递给模型,经过一次前向传播(映射)就得到输出y. 实践中可能会使用更精细的19×19网格,所以输出就是19×19×8, 这样的网格精细得多, 那么多个对象分配到同一个格子得概率就小得多.
重申:
把对象分配到一个格子的过程是,
- 观察对象的中点,
- 然后将这个对象分配到其中点所在的格子
- 所以即使对象可以横跨多个格子,也只会被分配到9个格子其中之一
- 两个对象的中点处于同一个格子的概率就会更低
Specify the bounding boxes:
以橙色中心点的方格为例,
$b_x = 0.4$, 因为它的位置大概是水平长度的0.4$b_y = 0.3$, 因为它的位置大概是垂直长度的0.3$b_h = 0.9$, 红框的高度大概是黑格子的宽度的90%$b_w = 0.5$, 红框的宽度大概是黑格子的宽度的50%
$b_x,b_y$必须在0和1之间, 因为橙色点位于对象分配到格子的范围内.
$b_h,b_w$可能回大于1, 因为框住物体的红色框可能跨越多个黑色格子
在其他文章中, 还有其他更复杂的参数化方式,涉及到sigmoid函数,确保这个值$b_x,b_y$介于0和1之间,然后使用指数参数化来确保这些$b_x,b_y$都是非负数
交并比(Intersection over union)
并交比函数用来评价对象检测算法. Evaluate Whether or not the object is correctly localized.

The ground truth bounding box shows in red. But algorithm offer bounding box in purple. It is a good outcome or bad?
Intersection over Union(IoU): It computes the intersection over union of these 2 bounding boxes.
Size of Union == Green-shaded area
Size of Intersection == Yellow-shaded area
‘Correct’ if IoU >= 0.5
(If predictor and the ground truth bounding box overlapped perfectly, IoU=1)
Higher the IoUs, the more accurate the bounding box
非极大值抑制(Non-max suppression)
可以显着提高YOLO的效果——非极大值抑制
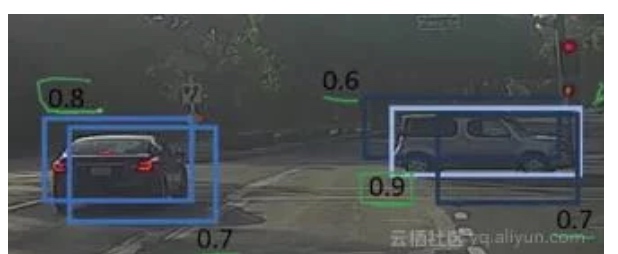
对象检测算法最常见的问题之一是,它不是一次仅检测出一次对象,而可能获得多次检测结果. Non-max suppression is a way to make sure that your algorithm detects each object only one.
理论上每个物体只有一个中点,所以它应该只被分配到一个格子里; 例如左边的车子也只有一个中点,所以理论上应该只有一个格子做出有车的预测. 但实际上, 格子4,5,6都可能认为这辆车车的中点应该在他们那里.

上图中,汽车不止一次被识别. 非极大值抑使得每个对象只能进行一次检测:
它首先查看与每次检测相关的概率并取最大的概率。在上图中,0.9是最高概率,因此首先选择概率为0.9的方框(浅蓝色):

现在,它会查看图像中的所有其他框。与当前边界框较高的IoU的边界框将被抑制。因此,在示例中,0.6和0.7概率的边界框将被抑制(深蓝色):
在部分边界框被抑制后,它会从概率最高的所有边界框中选择下一个,在例子中为0.8的边界框(浅蓝色):
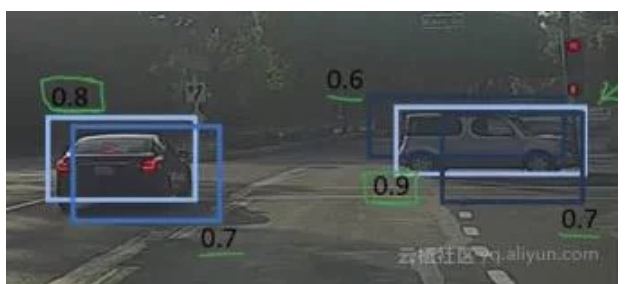
再次计算与该边界框相连边界框的IoU,去掉较高IoU值的边界框(深蓝色):

重复这些步骤,得到最后的边界框:

以上就是非极大值抑制的全部内容,总结一下关于非极大值抑制算法的要点:
- 丢弃概率小于或等于预定阈值(例如0.6)的所有方框;
- 对于剩余的边界框:选择具有最高概率的边界框并将其作为输出预测;
- 计算相关联的边界框的IoU值,舍去IoU大于阈值的边界框;
- 重复步骤2,直到所有边界框都被视为输出预测或被舍弃;
Summary:
- Get the each output prediction y
- Discard all boxes with Pc <= 0.6
- While there are any remaining boxes:
- Pick the box with the largest Pc output that as a prediction
- Discard any remaining box with IoU >=0.5 with the box output in the previous step
Anchor Boxes
Anchor Boxes可以帮助检测单个网格中的多个对象.
假设将下图按照3X3网格划分:

获取对象的中心点,并根据其位置将对象分配给相应的网格。在上面的示例中,两个对象的中心点位于同一网格中:

之前的方法只会获得两个边界框其中的一个,但是如果使用Anchor Boxes,可能会输出两个边界框.
做法:
首先,预先定义两种不同的形状(实际可能是多个),称为Anchor Boxes. 对于每个网格将有两个输出. 然后把预测结果和这两个anchor boxes关联起来.
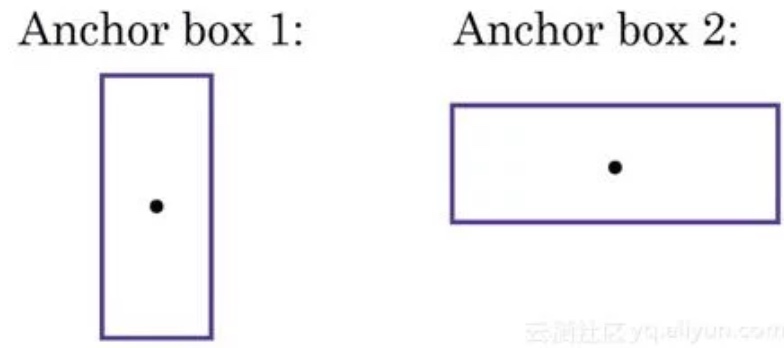
没有Anchor Boxes的YOLO输出标签$y = \begin{bmatrix} P_c \\ b_x \\ b_y \\ b_h \\ b_w \\ c_1 \\ c_2 \\ c_3 \end{bmatrix}$
有Anchor Boxes的YOLO输出标签$y = \begin{bmatrix} P_c \\ b_x \\ b_y \\ b_h \\ b_w \\ c_1 \\ c_2 \\ c_3 \\P_c \\ b_x \\ b_y \\ b_h \\ b_w \\ c_1 \\ c_2 \\ c_3\end{bmatrix}$
前8行属于Anchor Box1,其余8行属于Anchor Box2。基于边界框和框形状的相似性将对象分配给Anchor Boxes。由于Anchor Box1的形状类似于人的边界框,前者将被分配给Anchor Box1,并且车将被分配给Anchor Box2.在这种情况下的输出,将是3X3X16大小.
(判断属于哪个Anchor Boxes, 就是计算哪个nchor Boxes与实际物体的IoU高, 然后分配到y向量的上半部或者下半部)
因此,对于每个网格,可以根据Anchor Boxes的数量检测两个或更多个对象

具体例子:
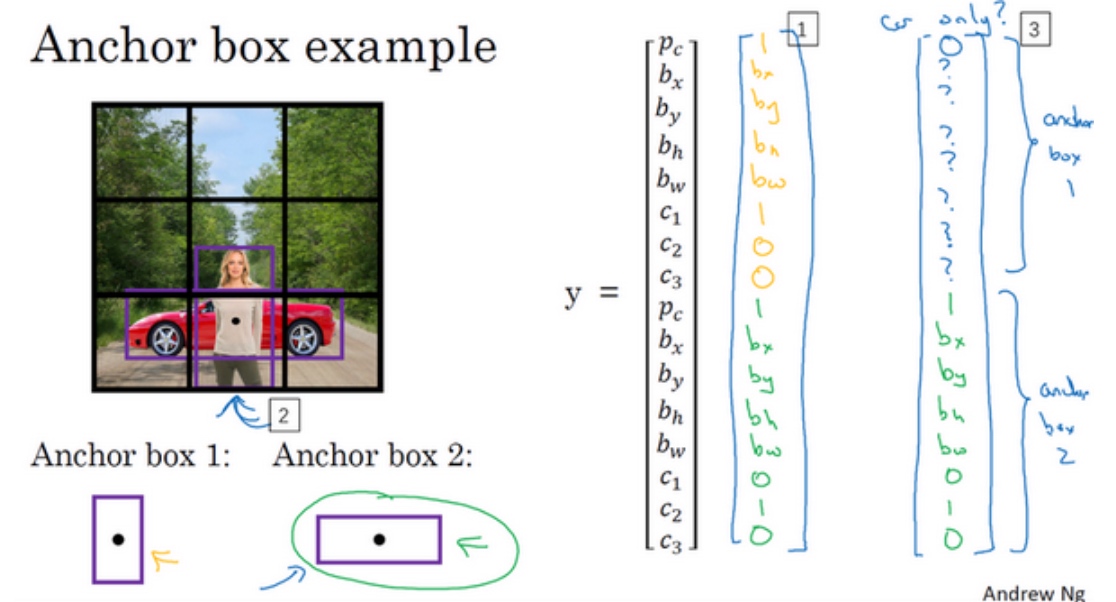
定义了y, 在人和车的中点在同一个格子的情况下: $y = \begin{bmatrix} 1 \\ b_x \\ b_y \\ b_h \\ b_w \\ 1 \\ 0 \\ 0 \\1 \\ b_x \\ b_y \\ b_h \\ b_w \\ 0 \\ 1 \\ 0\end{bmatrix}$
但若是人走了, 只剩车的情况下: $y = \begin{bmatrix} 0 \\ ? \\ ? \\ ? \\ ? \\ ? \\ ? \\ ? \\1 \\ b_x \\ b_y \\ b_h \\ b_w \\ 0 \\ 1 \\ 0\end{bmatrix}$
额外:
- 如果有两个anchor box,但在同一个格子中有三个对象,这种情况算法处理不好. 其实出现的情况不多,所以对性能的影响应该不会很大
- anchor box这个概念,是为了处理两个对象出现在同一个格子的情况,实践中这种情况很少发生,特别是如果用的是19×19网格, 两个对象中点处于361个格子中同一个格子的概率很低
- 人们一般手工指定anchor box形状,可以选择5到10个anchor box形状,覆盖到多种不同的形状.
- 但是更高级自动选择方法是使用k-means算法, 可以将两类对象形状聚类,如果用它来选择一组anchor box,选择最具有代表性的一组anchor box,可以代表试图检测的十几个对象类别
YOLO 算法(Putting it together: YOLO algorithm)
[Redmon et al., 2015, You Only Look Once: Unified real-time object detection]
训练阶段:
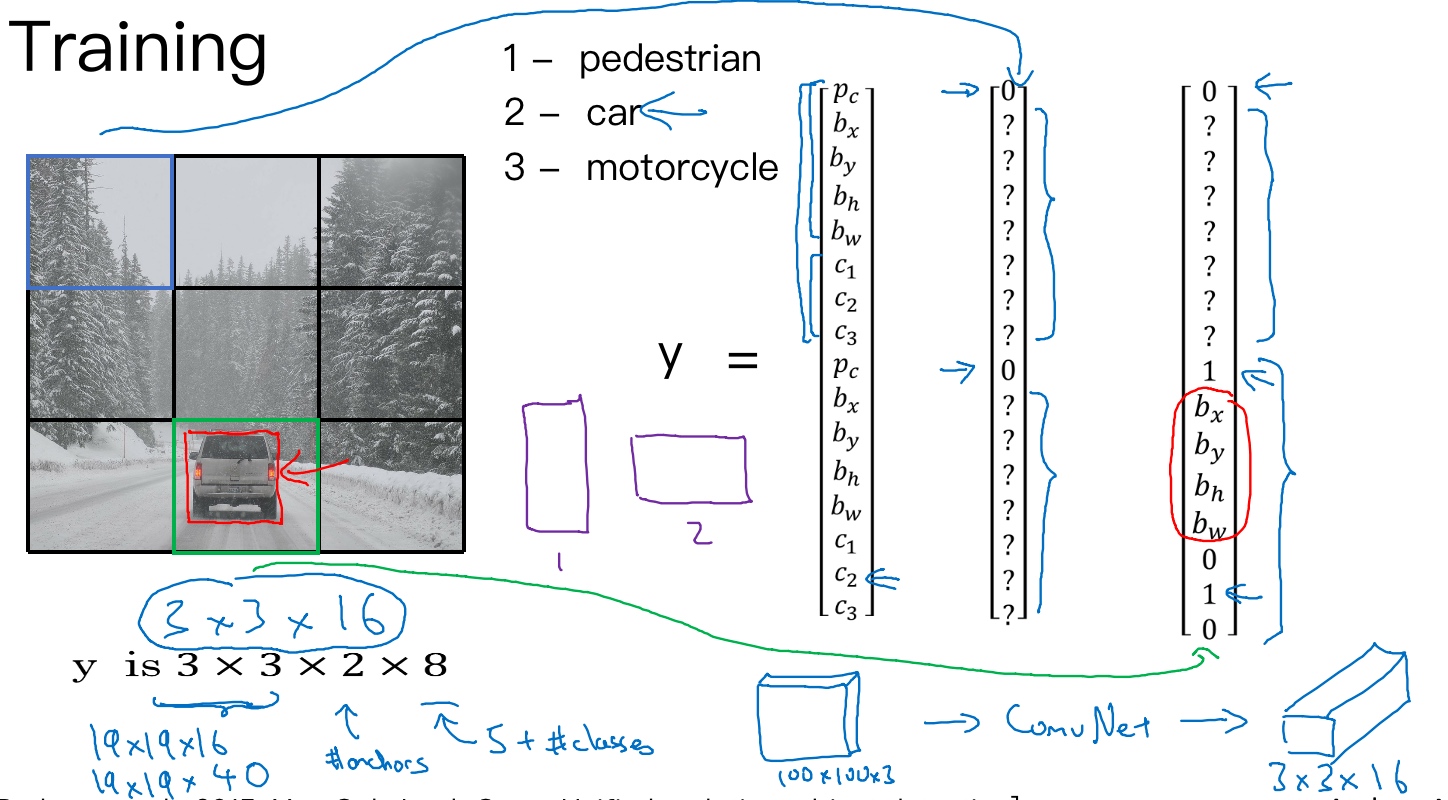
假设要训练一个算法去检测三种对象,行人、汽车和摩托车(3个类别标签),如果要用两个anchor box,那么输出y就是3×3×2×8.
(2是anchor box的数量,8是向量维度)
要构造训练集, 需要遍历9个格子,然后构成对应的目标向量y
第一个格子:$y = \begin{bmatrix} 0 \\ ? \\ ? \\ ? \\ ? \\ ? \\ ? \\ ? \\ 0 \\ ? \\ ? \\ ? \\ ? \\ ? \\ ? \\ ?\end{bmatrix}$
第八个格子: $y = \begin{bmatrix} 0 \\ ? \\ ? \\ ? \\ ? \\ ? \\ ? \\ ? \\1 \\ b_x \\ b_y \\ b_h \\ b_w \\ 0 \\ 1 \\ 0\end{bmatrix}$
以上就是训练集的构成,然后训练一个卷积网络,输入可能是100×100×3的图片, 卷积网络最后输出尺寸是3×3×16 (3×3×2×8)
测试阶段:
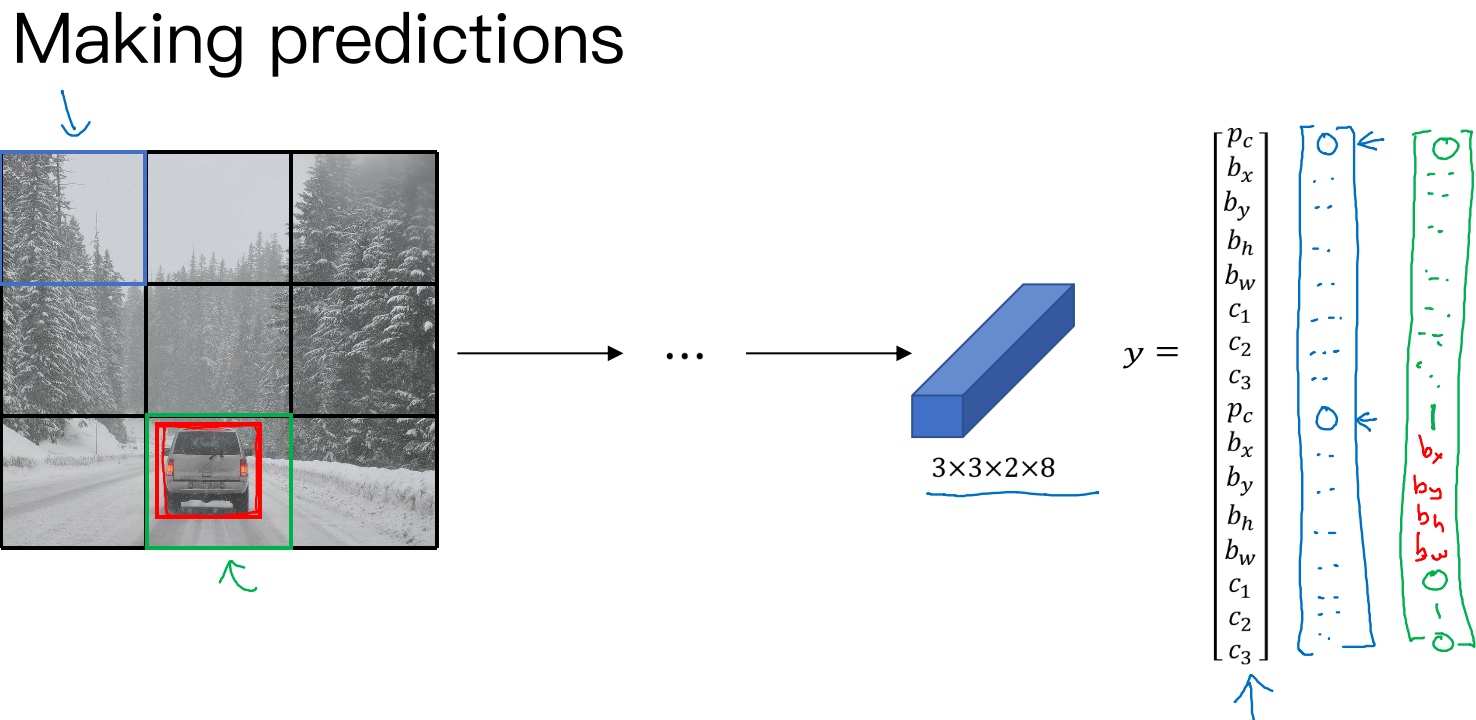
对于每个网格,模型将预测3X3X16大小的输出, 该预测中的16个值将与训练标签的格式相同.
最后, 非极大值抑制方法将应用于预测框以获得每个对象的单个预测结果(Outputting the non-max supressed outputs):

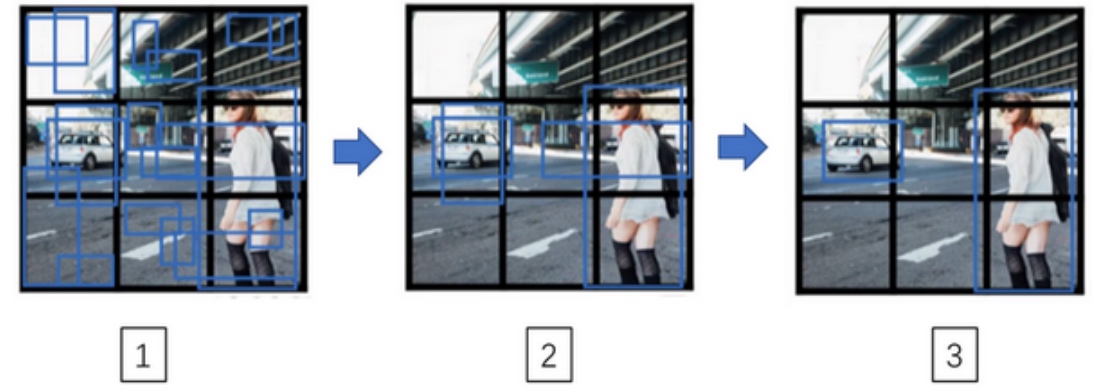
- For each grid call, get 2 predicted bounding boxes. (9个格子中任何一个都会有两个预测的边界框)
- Get rid of low probability predictions. (抛弃概率很低的预测)
- For each class (pedestrian, car, motorcycle) use non-max suppression to generate final predictions. (对于每个类别单独运行非极大值抑制,处理预测结果所属类别的边界框, 运行三次来得到最终的预测结果)
Summary, 以下是YOLO算法遵循的确切维度和步骤:
- 准备对应的图像(608,608,3);
- 将图像传递给卷积神经网络(CNN),该网络返回(19,19,5,85)维输出;
- 输出的最后两个维度被展平以获得(19,19,425)的输出量:
- 19×19网格的每个单元返回425个数字; 425=5 * 85,其中5是每个网格的Anchor Boxes数量;
- 85= 5+80,其中5表示(pc、bx、by、bh、bw),80是检测的类别数;
- 最后,使用IoU和非极大值抑制去除重叠框;
候选区域(Region proposals)
[Girshik et. al, 2013, Rich feature hierarchies for accurate object detection and semantic segmentation]
R-CNN (带区域的卷积网络), 这个算法尝试选出一些区域, 不再针对每个滑动窗运行检测算法,而是只选择一些有意义的窗口, 在少数窗口上运行卷积网络分类器.
Region proposal: R-CNN

选出候选区域的方法是运行图像分割算法(segementation alogrithm). 用分割算算法得到不同的色块, 并在该色块上色块上放置边界框. 可能找出2000多个色块, 然后在这2000个色块上运行分类器, 这样需要处理的位置可能要少的多,可以减少卷积网络分类器运行时间, 比在图像所有位置运行一遍分类器要快.
R-CNN算法不会直接信任输入的边界框,它也会输出一个边界框$b_x , b_y , b_h ,b_w$, 这样得到的边界框比较精确,比单纯使用图像分割算法给出的色块边界要好,所以它可以得到相当精确的边界框
R-CNN算法的一个缺点是太慢, Faster algorithms:
R-CNN:
- Propose regions. Classify proposed regions one at a time. Output label + bounding box.
- [Girshik et. al, 2013. Rich feature hierarchies for accurate object detection and semantic segmentation]
Fast R-CNN:
- Propose regions. Use convolution implementation of sliding windows to classify all the proposed regions.
- [Girshik, 2015. Fast R-CNN]
Faster R-CNN:
- Use convolutional network to propose regions. (使用的是卷积神经网络,而不是更传统的分割算法来获得候选区域色块)
- [Ren et. al, 2016. Faster R-CNN: Towards real-time object detection with region proposal networks]
BUT, still lower than YOLO
Code: https://kknews.cc/code/ror3xrv.html
https://blog.csdn.net/zhangqian_shai/article/details/80542406
YOLO算法实现
本节中用于实现YOLO的代码来自Andrew NG的GitHub存储库,需要下载此zip文件,其中包含运行此代码所需的预训练权重。
首先定义一些函数,这些函数将用来选择高于某个阈值的边界框,并对其应用非极大值抑制。首先,导入所需的库:
import os
import matplotlib.pyplot as plt
from matplotlib.pyplot import imshow
import scipy.io
import scipy.misc
import numpy as np
import pandas as pd
import PIL
import tensorflow as tf
from skimage.transform import resize
from keras import backend as K
from keras.layers import Input, Lambda, Conv2D
from keras.models import load_model, Model
from yolo_utils import read_classes, read_anchors, generate_colors, preprocess_image, draw_boxes, scale_boxes
from yad2k.models.keras_yolo import yolo_head, yolo_boxes_to_corners, preprocess_true_boxes, yolo_loss, yolo_body
%matplotlib inline然后,实现基于概率和阈值过滤边界框的函数:
def yolo_filter_boxes(box_confidence, boxes, box_class_probs, threshold = .6):
box_scores = box_confidence*box_class_probs
box_classes = K.argmax(box_scores,-1)
box_class_scores = K.max(box_scores,-1)
filtering_mask = box_class_scores>threshold
scores = tf.boolean_mask(box_class_scores,filtering_mask)
boxes = tf.boolean_mask(boxes,filtering_mask)
classes = tf.boolean_mask(box_classes,filtering_mask)
return scores, boxes, classes之后,实现计算IoU的函数:
def iou(box1, box2):
xi1 = max(box1[0],box2[0])
yi1 = max(box1[1],box2[1])
xi2 = min(box1[2],box2[2])
yi2 = min(box1[3],box2[3])
inter_area = (yi2-yi1)*(xi2-xi1)
box1_area = (box1[3]-box1[1])*(box1[2]-box1[0])
box2_area = (box2[3]-box2[1])*(box2[2]-box2[0])
union_area = box1_area+box2_area-inter_area
iou = inter_area/union_area
return iou然后,实现非极大值抑制的函数:
def yolo_non_max_suppression(scores, boxes, classes, max_boxes = 10, iou_threshold = 0.5):
max_boxes_tensor = K.variable(max_boxes, dtype='int32')
K.get_session().run(tf.variables_initializer([max_boxes_tensor]))
nms_indices = tf.image.non_max_suppression(boxes,scores,max_boxes,iou_threshold)
scores = K.gather(scores,nms_indices)
boxes = K.gather(boxes,nms_indices)
classes = K.gather(classes,nms_indices)
return scores, boxes, classes随机初始化下大小为(19,19,5,85)的输出向量:
yolo_outputs = (tf.random_normal([19, 19, 5, 1], mean=1, stddev=4, seed = 1),
tf.random_normal([19, 19, 5, 2], mean=1, stddev=4, seed = 1),
tf.random_normal([19, 19, 5, 2], mean=1, stddev=4, seed = 1),
tf.random_normal([19, 19, 5, 80], mean=1, stddev=4, seed = 1))最后,实现一个将CNN的输出作为输入并返回被抑制的边界框的函数:
def yolo_eval(yolo_outputs, image_shape = (720., 1280.), max_boxes=10, score_threshold=.6, iou_threshold=.5):
box_confidence, box_xy, box_wh, box_class_probs = yolo_outputs
boxes = yolo_boxes_to_corners(box_xy, box_wh)
scores, boxes, classes = yolo_filter_boxes(box_confidence, boxes, box_class_probs, threshold = score_threshold)
boxes = scale_boxes(boxes, image_shape)
scores, boxes, classes = yolo_non_max_suppression(scores, boxes, classes, max_boxes, iou_threshold)
return scores, boxes, classes使用yolo_eval函数对之前创建的随机输出向量进行预测:
scores, boxes, classes = yolo_eval(yolo_outputs)
with tf.Session() as test_b:
print("scores[2] = " + str(scores[2].eval()))
print("boxes[2] = " + str(boxes[2].eval()))
print("classes[2] = " + str(classes[2].eval())) score表示对象在图像中的可能性,boxes返回检测到的对象的(x1,y1,x2,y2)坐标,classes表示识别对象所属的类。
score表示对象在图像中的可能性,boxes返回检测到的对象的(x1,y1,x2,y2)坐标,classes表示识别对象所属的类。
现在,在新的图像上使用预训练的YOLO算法,看看其工作效果:
sess = K.get_session()
class_names = read_classes("model_data/coco_classes.txt")
anchors = read_anchors("model_data/yolo_anchors.txt")
yolo_model = load_model("model_data/yolo.h5")在加载类别信息和预训练模型之后,使用上面定义的函数来获取·yolo_outputs·。
yolo_outputs = yolo_head(yolo_model.output, anchors, len(class_names))之后,定义一个函数来预测边界框并在图像上标记边界框:
def predict(sess, image_file):
image, image_data = preprocess_image("images/" + image_file, model_image_size = (608, 608))
out_scores, out_boxes, out_classes = sess.run([scores, boxes, classes], feed_dict={yolo_model.input: image_data, K.learning_phase(): 0})
print('Found {} boxes for {}'.format(len(out_boxes), image_file))
# Generate colors for drawing bounding boxes.
colors = generate_colors(class_names)
# Draw bounding boxes on the image file
draw_boxes(image, out_scores, out_boxes, out_classes, class_names, colors)
# Save the predicted bounding box on the image
image.save(os.path.join("out", image_file), quality=90)
# Display the results in the notebook
output_image = scipy.misc.imread(os.path.join("out", image_file))
plt.figure(figsize=(12,12))
imshow(output_image)
return out_scores, out_boxes, out_classes接下来,将使用预测函数读取图像并进行预测:
img = plt.imread('images/img.jpg')
image_shape = float(img.shape[0]), float(img.shape[1])
scores, boxes, classes = yolo_eval(yolo_outputs, image_shape)最后,输出预测结果:
out_scores, out_boxes, out_classes = predict(sess, "img.jpg")